Kafka是一个开源的,轻量级的、分布式的、具有复制备份、基于zooKeeper协调管理的分布式消息系统。
它具备以下三个特性:
能够发布订阅流数据:
存储流数据时,提供相应的容错机制
当流数据到达时,能够被及时处理。
首发于个人博客网站:链接地址
下载安装
本次安装只介绍在linux环境下,windows的暂时不考虑。
下载
作为一个消息中间件,kafka并不是一个jar包,而是一个完整的应用,所以直接取官网下载部署包.
下载地址:https://kafka.apache.org/downloads
这里选择:
下载完毕之后,可以使用winSCP上传到服务器中。
也可以使用wget命令,直接下载:
配置
下载完安装包之后,把它放在/usr/local
1 tar -zxf kafka_2.11-1.1.1.tgz
2 mv kafka_2.11-1.1.1.tgz kafka
换个目录名称,kafka看起来更简洁一些。
启动服务
kafka是依赖于zookeeper的,所以再启动kafka之前需要先启动zookeeper。
之前看到某书,书中说是要再去下载一个zookeeper,其实是没必要的,kafka部署包中本身就有zookeeper。
首先进入kafka目录
cd /usr/local/kakfa
启动zookeeper:
执行完命令后使用jps命令查看是否启动:
1 [root@izbp18twqnsvndjvj1mnagz kafka]# jps
2 9088 app.jar
3 25170 Jps
4 24539 QuorumPeerMain
看到有QuorumPeerMain,说明zookeeper启动成功了。
启动kafka:
当然,你也可以去掉 -daemon,这样就不会kafka占用控制台了。
还是使用jps命令查看运行是否启动成功:

现在已经完成了helloWorld的第一步,接下来,就了解一下kafka的基本概念,进行验证。
Kafka中几个关键概念
Kafka的使用场景:
1.构建实时的数据流管道,系统和应用程序能够可靠的获取消息。
2.构建转换或响应数据流的实时流应用程序.
基本概念:
1.Kafka是以集群的方式运行在一个或多个数据中心的服务器上的
2.Kafka引入了主题的概念,它是以主题来分类消息流的
3.每一条消息都有三部分组成,键,值,时间戳。
主题(Topic)
主题就是一个分类,或者说一个集合,用来将发布到kafka的消息进行归类。
通常来说,在Kafka中,一个主题通常有多个用户来订阅和生产消息。
在实际生产中,在Kafka中都是有多个主题的,对于每个主题,都维护多个分区(partition)日志,如下图所示:
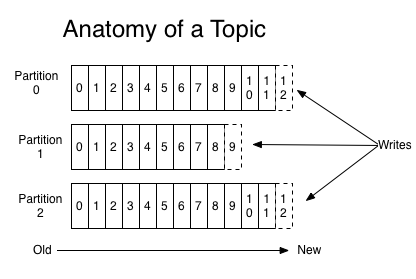

创建主题
创建主题使用kafka-topic.sh脚本,创建单分区单副本的topic test:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
查看主题:
bin/kafka-topics.sh --list --zookeeper localhost:2181
输出结果为:

分区(partition)
在主题中,每个分区都是一个有序的、不可变的记录序列,并不断地附加到一个结构化的提交日志中。
分区中的记录序列都被分配了一个偏移值,该偏移量惟一地标识分区中的每个记录。
这个偏移值可以是自增的,也可以是开发者自己指定。
在日志服务器中设置分区有以下几个好处:
首先,kafka集群允许日志消息扩展到适合的单个服务器的消息,每个分区都会有承载它大小的服务器,一个主题有多个分区,它可以处理任意数量的数据
其次,消息是并行的,可以同时处理.
分区的分布式
在kafka集群中,日志的分区是分布在每个主机上的,每个主机都共享数据和共同处理数据。
每个分区在集群中的服务器中进行复制,借此实现容错的功能。
与zookeeper类似,在集群中,总有一个主机扮演leader的角色,其他主机扮演follwers的角色。
当leader进行读和写操作时,follwers也将重复leader的操作,进行读和写。
遇到leader故障怎么办,那么其他follwers中的任意一台主机就会自动成为新的leader。
生产者(producers)
生产者,顾名思义,生产消息。生产者,选择kakfa中的某个主题某个分区进行推送消息。
为了负载均衡,也可以通过循环的方式来发送消息。
消费者(consumers)
消费者通常是以组的形式存在,消费者组订阅消息,并且分发给组中的每一个消费者实例。
消费者实例,可以分布在不同的进程中,也可是不同的机器中。
如果所有消费者都有相同的组,那么消息将会在消费者组中进行负载均衡分发。
如果所有消费者上都使用了不同的消费者,那么每个消息都将被广播到消费者实例。
如下图:

有两个kafka集群,这两个集群有四个分区,和两个消费者组。消费者组A有2个消费者实例,消费者组B有四个消费者实例。
通常来说,主题(topic)都会有少量的消费者组,主题中的一个逻辑(也可以说一个业务)对应着一个消费者组。
每个消费者组组都由许多消费者实例组成,从而保证可扩展性和容错性。
kafka只记录了所有分区的总数,并不单独记录每个主题中分区的总数。对于大多数应该程序来说,对分区的读写只需要根据分区的偏移值就能找到了。
保障
- 当消息发送到一个特定的主题分区中,消息的顺序按照其发送的顺序,比如先发送M1,后发送M2,那么M2就排在M1的后面。
- 当消费者订阅消息时,它获取消息的顺序是按照消息存储的顺序。
- 假设一个主题,他的容错因子是N(当它为leader时,有N个follwers),该集群最多能允许N-1个follwers 操作失败。
Kafka的优势
多个生产者
Kafka可无缝支持多个生产者,不管客户端使用单个主题还是多个主题。所以它适合从多个系统中收集数据,并以统一的格式对外提供数据。
多个消费者
Kafka支持多个消费者从一个单独的消息流上读取数据,而且消费者之间互不影响。这与其他队列系统不同,其他队列系统消息一旦被一个客户端读取,其他客户端就无法读取它。
除此之外,消费者可以组成一个群组,消费组可以共享消息流,并保证整个群组对每个给定的消息只处理一次。
消息持久化
消费者可以非实时的读取消息,这是因为kafka可以将消息存在磁盘中,根据设置的规则进行保存,而且每个主题可以设置单独的保留规则。
当消费者因为处理速度慢或者突然的流量暴增导致的无法及时的处理消息,那么就可以将消息进行持久化存储,并保证消息不会丢失。
消费者可以被关闭,但是消息被继续保留在Kafka中,消费者可以从上次中断的地方继续读取消息。
高性能与伸缩性
一个服务器可称为一个broker,开发时可以是一个,然后扩展成3个,小型集群,随着数据不断增长,可以扩展至上百个。
对于在线集群进行扩展,丝毫不影响系统的可用性。
在处理大数据时,Kafka能保证亚秒级别的消息延迟。
总结
kafka是高性能,吞吐量极高的消息中间件。学习kafka需要先去学习它其中的一些概念,只有理解了这些概念,
才能够在实际生产过程中更好的合理的使用kafka,本文是开篇,主要介绍了一些kafka的概念,下一篇主要内容是kafka的常用api。