一、黑盒测试:
1、定义:
把被测程序视为一个不能打开的黑盒子,在完全不考虑程序内部结构和内部特性的情况下进行测试,也叫做功能测试或者是数据驱动测试。
黑盒测试并不是无知的测试,它意味着产品内部知识在测试中不起重要作用,同时强调有关软件的用户和环境知识。
2、目的:
在已知软件产品所应具有的功能的基础上进行测试:
(1)、检查程序功能能否按需求规格说明书的规定正常使用,测试各个功能是否有遗漏,检测性能等特性要求是否满足;
(2)、检测人机交互是否错误,检测数据结构或外部数据库访问是否错误,程序是否能适当地接收输入数据而产生正确的输出结果;
(3)、检测程序初始化和终止方面的错误。
3、优缺点:
优点:
(1)、针对性地寻找问题,并且定位问题更准确。
(2)、黑盒测试可以证明产品是否达到用户要求的功能,符合用户的工作要求。
(3)、能重复执行相同的动作,测试工作中最枯燥的部分可交由机器完成。
缺点:
(1)、需要充分了解产品用到的技术,测试人员需要具有较多经验。
(2)、在测试过程中很多是手工测试操作。
(3)、测试人员要负责大量文档、报表的编制和整理工作。
4、静态黑盒和动态黑盒:
(1)、静态黑盒:文档测试,特别是产品需求文档、用户手册、帮助文件等的审查。
(2)、动态黑盒:通过数据输入并运行程序来检验输出结果。
二、黑盒测试用例设计方法:
1、等价类划分:
一种重要的、常用的黑盒测试方法,它将不能穷举的测试过程进行合理分类,从而保证设计出来的测试用例具有完整性和代表性。
等价类划分法一般把所有可能的输入数据(有效的和无效的)划分成若干个等价的子集,使得每个子集中的一个典型值在测试中的作用与这一子集中所有其它值的作用相同,再从每个子集中选取一组数据来测试程序。
有效等价类:
对于程序的需求规格说明书来说是合理的、有意义的输入数据组成的集合。
利用有效等价类可以检验程序是否实现了规格说明书中所要求的功能或性能。
(正面用例)
无效等价类:
与有效等价类正好相反,无效等价类指对程序的规格说明是不合理的或无意义的输入数据所构成的集合。
无效等价类至少应有一个,也可能有多个。
(负面用例)
采用等价类划分法设计测试用例通常分两步进行:
(1)、确定等价类,列出等价类表。
(2)、确定测试用例。
例子:
输入条件为整数num应该大于等于20小于等于100,整数num2应该大于等于50小于等于80,输出为num和num2的和。
此时有效等价类为:20<=num<=100和50<=num2<=80
无效等价类为:num<20、num>100、num2>80、num2<50
| 输入条件 | 有效等价类 | 标识 | 无效等价类 | 标识 |
| 整数num | 20<=num<=100 | ① | num<20 | ② |
| num>100 | ③ | |||
| 整数num2 | 50<=num<=80 | ④ | num<50 | ⑤ |
| num>80 | ⑥ |
测试用例:
| 序号 | 输入条件 | 覆盖等价类 | 输出结果 | |
| num | num2 | |||
| 1 | 25 | 55 | ①④ | 80 |
| 2 | 10 | 55 | ②④ | num不合理 |
| 3 | 150 | 60 | ③④ | num不合理 |
| 4 | 50 | 30 | ①⑤ | num2不合理 |
| 5 | 60 | 90 | ①⑥ | num2不合理 |
2、边界值分析:
边界值分析法就是对输入或输出的边界值进行测试的一种黑盒测试方法,通常边界值分析法是作为对等价类划分法的补充,这种情况下,其测试用例来自等价类的边界。
大量的错误往往是发生在输入或输出范围的边界上,而不是发生在输入输出范围的内部。因此针对各种边界情况设计测试用例,可以查出更多的错误。
使用边界值分析方法设计测试用例,首先应确定边界情况。通常输入和输出等价类的边界,就是应着重测试的边界情况。应当选取正好等于,刚刚大于或刚刚小于边界的值作为测试数据,而不是选取等价类中的典型值或任意值作为测试数据。
步骤:
(1)、确定边界min和max
(2)、取值min(正好等于最小边界)、min+(刚刚大于最小边界)、nom(常规项)、max-(刚刚小于最大边界)、max(正好等于最大边界)
例子:
有二元函数f(x,y),其中x∈[1,12],y∈[1,31],则采用边界值分析法设计的测试用例是:
{ <1,15>, <2,15>, <11,15>, <12,15>, <6,15>, <6,1>, <6,2>, <6,30>, <6,31> }
对于一个含有n个变量的程序,采用边界值分析法测试程序会产生4n+1个测试用例。
扩充:
健壮性测试是在边界值分析法基础上添加max+(刚刚大于最大边界)和min-(刚刚小于最小边界)
3、因果图法:
一种利用图解法分析输入的各种组合情况,从而设计测试用例的方法,它适合于检查程序输入条件的各种组合情况。
步骤:
(1)、分析软件规格说明中哪些是原因(输入),哪些是结果(输出),并给每个原因和结果赋予一个标识符。
(2)、分析软件规格说明中的语义,找出原因与结果之间、原因与原因之间对应的关系, 根据这些关系画出因果图。
(3)、由于语法或环境的限制,有些原因与原因之间、原因与结果之间的组合情况不可能出现。为表明这些特殊情况,在因果图上用一些记号表明约束或限制条件。
(4)、把因果图转换为决策表。
(5)、根据决策表中的每一列设计测试用例。
优点:
(1)、考虑到了输入情况的各种组合以及各个输入情况之间的相互制约关系。
(2)、能够帮助测试人员按照一定的步骤,高效率的开发测试用例。
(3)、因果图法是将自然语言规格说明转化成形式语言规格说明的一种严格的方法,可以指出规格说明存在的不完整性和二义性。
关系画法:
恒等:

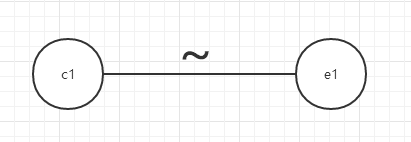
非:
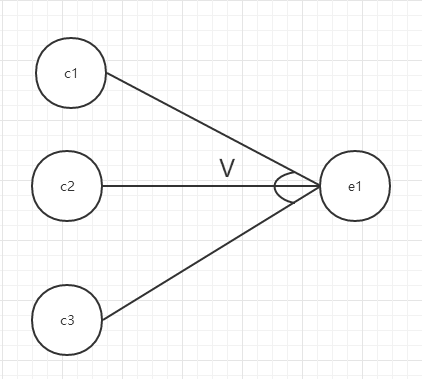
或:
与:
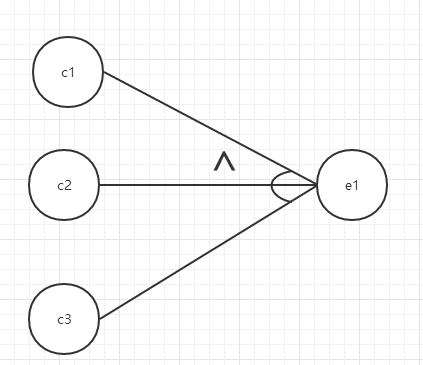
ci表示输入状态(或称原因),ei表示输出状态(或称结果)。
约束:
(1)、E约束(互斥):原因a和原因b中最多有一个可能成立,即a和b不会同时成立。
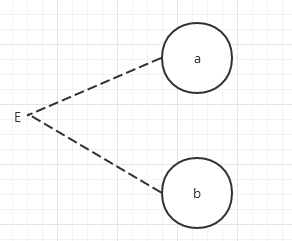
(2)、I约束(包含):a、b这两个原因中至少有一个必须成立。

(3)、O约束(唯一):原因a和b中必须有一个,且仅有一个成立。
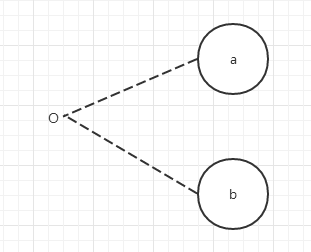
(4)、R约束(要求):原因a出现时,原因b也必须出现,a出现时,不可能b不出现。

(5)、M约束(强制):若结果a为1,则结果b强制为0。
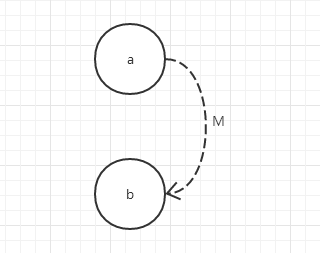
例子:
一个处理单价为1元5角钱的盒装饮料自动售货机。
若投入1元5角的硬币,按下“可乐”、“雪碧”或“红茶”按钮,相应的饮料就送出来。
若投入的是两元硬币,在送出饮料的同时退出5角硬币。
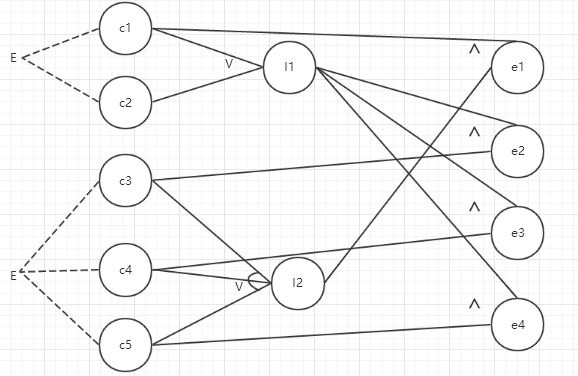
c1:投币2元;c2:投币1.5元;c3:按可乐按钮;c4:按雪碧按钮;c5:按红茶按钮;
I1:已投币;I2:已按钮;
e1:找5毛;e2:出可乐;e3:出雪碧;e4:出红茶
4、错误推测法:
在单元测试时曾列出的许多在模块中常见的错误、以前产品测试中曾经发现的错误等,这些就是经验的总结。
输入数据和输出数据为0的情况、输入表格为空格或输入表格只有一行等。
这些都是容易发生错误的情况,可选择这些情况下的例子作为测试用例。
5、判定表法:
判定表是分析和表达多逻辑条件下执行不同操作的情况的工具,判定表法是最为严格、最具有逻辑性的测试方法。
优点:
能够将复杂的问题按照各种可能的情况全部列举出来,简明并避免遗漏,利用判定表能够设计出完整的测试用例集合。
组成:
条件桩、动作桩、条件项、动作项及规则。
(1)、条件桩:列出了问题的所有条件,通常认为列出的条件的次序无关紧要;
(2)、动作桩:列出了问题规定可能采取的操作,这些操作的排列顺序没有约束;
(3)、条件项:列出针对它所列条件的取值,在所有可能情况下的真假值;
(4)、动作项:列出条件项的各种取值情况下应该采取的动作;
(5)、规则:任何一个条件组合的特定取值及其相应要执行的操作。
在判定表中贯穿条件项和动作项的一列就是一条规则。
步骤:
(1)、确定规则的个数;
(2)、列出所有的条件桩和动作桩;
(3)、填入条件项;
(4)、填入动作项,得到初始判定表;
(5)、 简化决策表,合并相似规则。
例子:
某学生成绩管理系统,要求“对平均成绩在90分以上,且没有不及格科目的学生,或班级成绩排名在前5位的学生,在程序中将学生的姓名用红色标识。”
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ||
|
条件 |
平均成绩大于90 |
1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
|
没有不及格的科目 |
1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | |
|
成绩排名在前5名 |
1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | |
|
动作 |
姓名用红色处理 |
√ | √ | √ | √ | √ | |||
|
姓名不做特殊处理 |
√ | √ | √ | ||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ||
|
条件 |
平均成绩大于90 |
1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
|
没有不及格的科目 |
1 | 1 | 0 | 0 | - | - | 0 | 0 | |
|
成绩排名在前5名 |
- | 0 | 1 | 0 | 1 | 0 | 1 | 0 | |
|
动作 |
姓名用红色处理 |
√ | √ | √ | √ | √ | |||
|
姓名不做特殊处理 |
√ | √ | √ | ||||||
6、正交试验法:
正交实验设计方法是依据Galois理论,从大量的数据中挑选适量的、有代表性的点,从而合理地安排实验的一种科学实验设计方法。
类似的方法有:聚类分析方法,因子方法方法等。
指标:通常把判断试验结果优劣的标准叫做试验的指标;
因子:影响实验指标的条件称为因子;
因子的状态:影响实验因子的条件。
步骤:
(1)、提取功能说明,构造因子-状态表;
(2)、加权筛选,生成因素分析表;
(3)、利用正交表构造测试数据集,正交表的推导依据Galois理论;
(4)、利用正交表每行数据构造测试用例。
试验次数计算公式:
在行数为mn型的正交表中,试验次数(行数)=∑(每列水平数-1)+1。
对![]() 这样的正交表计算试验次数公式为: (第一个因子数*(第一个水平数-1)+第二个因子数*(第二个水平数-1))+1 = 试验次数。
这样的正交表计算试验次数公式为: (第一个因子数*(第一个水平数-1)+第二个因子数*(第二个水平数-1))+1 = 试验次数。
例子:
为提高某化工厂产品的转化率,选择了3个有关因素进行条件试验,反应温度(A),反应时间(B),用碱量(C),并确定了他们的试验范围如下: A:80°C ~ 90°C B:90 ~ 150分钟 C:5% ~ 7% 对于A、B、C三个因子,在试验范围内都选了3个水平,如下所示: A:A1 = 80°C , A2 = 85°C , A3 = 90°C B:B1 = 90m , B2 = 120m , B3 = 150m C:C1 = 5% , C2 = 6% , C3 = 7%
| 因子1 | 因子2 | 因子3 | 因子4 | |
| 水平1 | 1 | 1 | 1 | 1 |
| 1 | 2 | 2 | 2 | |
| 1 | 3 | 3 | 3 | |
| 水平2 | 2 | 1 | 2 | 3 |
| 2 | 2 | 3 | 1 | |
| 2 | 3 | 1 | 2 | |
| 水平3 | 3 | 1 | 3 | 2 |
| 3 | 2 | 1 | 3 | |
| 3 | 3 | 2 | 1 |
| A | B | C | ==> | 试验号 | 水平组合 | 实验条件 | ||||
| 1 | 2 | 3 | 4 | 温度 | 时间 | 加碱量 | ||||
| 1 | 1 | 1 | 1 | 1 | 1 | A1B1C1 | 80 | 90 | 5 | |
| 2 | 1 | 2 | 2 | 2 | 2 | A1B2C2 | 80 | 120 | 6 | |
| 3 | 1 | 3 | 3 | 3 | 3 | A1B3C3 | 80 | 150 | 7 | |
| 4 | 2 | 1 | 2 | 3 | 4 | A2B1C2 | 85 | 90 | 6 | |
| 5 | 2 | 2 | 3 | 1 | 5 | A2B2C3 | 85 | 120 | 7 | |
| 6 | 2 | 3 | 1 | 2 | 6 | A2B3C1 | 85 | 150 | 5 | |
| 7 | 3 | 1 | 3 | 2 | 7 | A3B1C3 | 90 | 90 | 7 | |
| 8 | 3 | 2 | 1 | 3 | 8 | A3B2C1 | 90 | 120 | 5 | |
| 9 | 3 | 3 | 2 | 1 | 9 | A3B3C2 | 90 | 150 | 6 | |
7、场景法:
现在的软件都是用事件来触发流程的,事件触发时的情景并成了场景,而同一事件不同的触发顺序和处理结果就形成事件流。
用例场景用来描述流经用例的路径,从用例开始到结束,遍历这条路径上所有基本流和备选流。
基本流用直黑线表示,备选流用不同的彩色表示。
相关链接: