1 文件读写
1.1 打开文件:
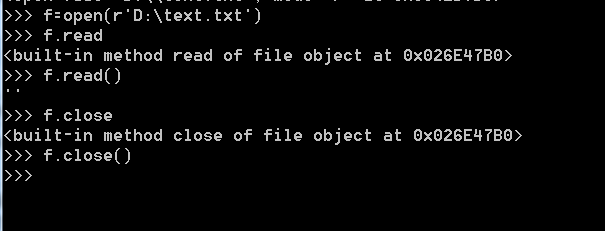
open(r'D: ext.txt')

1.2 文件模式
| 值 | 功能描述 |
|---|---|
| ‘r’ | 读模式 |
| ‘w’ | 写模式 |
| ‘a’ | 追加模式 |
| ‘b’ | 二进制模式 |
| ‘+’ | 读写模式 |
1.3 文件缓冲区
1.4 文件读取
-
使用try ...finally来保证程序的健壮性
-
使用with语句代替try finally和close方法
with open(r'd: ext.txt','r') as fileReader:
print fileReader.read() -
调用readline()可以每次读取一行内容
with open(r'd: ext.txt','r') as fileReader:
for line in fileReader.readline():
print fileReader.read()
1.5 文件写入
2 操作文件和目录
3 序列化操作
* 将内存中的变量序列化之后,可以把序列化的内容 写入磁盘,或者通过网络传输到别的机器上,实现程序状态的保存和共享,反之为反序列化
* python 提供两个模块:cPickle和pickle来实现序列化,两个模块功能和函数一样,前者运行效率高,使用c语言,不用pip安装,本身自带
* pickle实现序列化主要使用的是dumps方法或dump方法,dumps方法可以将任意对象序列化成一个str,然后将str写入文件进行保存
>>> import cPickle as pickle
>>> d = dict(url='index.html',title='home',content='home')
>>> pickle.dumps(d)
"(dp1
S'content'
p2
S'home'
p3
sS'url'
p4
S'index.html'
p5
sS'title'
p
6
g3
s."
>>>
* 如果使用dump方法,可以把序列化对象存在文件中
>>> f =open(r'D: ext.txt','wb')
>>> pickle.dump(d,f)
>>> f.close()
>>>
* pickle反序列使用loads或load方法,可先从文件取出放在str,在调用load,或者直接从文件load
>>> f =open(r'D: ext.txt','rb')
>>> d = pickle.load(f)
>>> f.close()
>>> d
{'content': 'home', 'url': 'index.html', 'title': 'home'}
>>>
3 进程和线程
3.1 多线程
-
python可以使用os模块和multiprocessing模块实现多线程,后者可以跨平台,前者只能在Unix/linux操作系统上运行
3.1.1 使用os模块中的fork方式实现多线程
import os
print os.getpid() #获取子进程的进程号
pid = os.fork()
if pid == 0 :
print 'I am child process (%s) and my parent is %s.' % (os.getpid(), os.getppid())
else :
print 'I (%s) just created a child process (%s).' % (os.getpid(), pid)
3.1.2 使用multiprocessing模块创建多线程
from multiprocessing import Process #导入Process模块
import os
def test(name):
'''
函数输出当前进程ID,以及其父进程ID。
此代码应在Linux下运行,因为windows下os模块不支持getppid()
'''
print "Process ID: %s" % (os.getpid())
print "Parent Process ID: %s" % (os.getppid())
if __name__ == "__main__":
'''
windows下,创建进程的代码一下要放在main函数里面
'''
proc = Process(target=test, args=('nmask',))
proc.start()
proc.join()
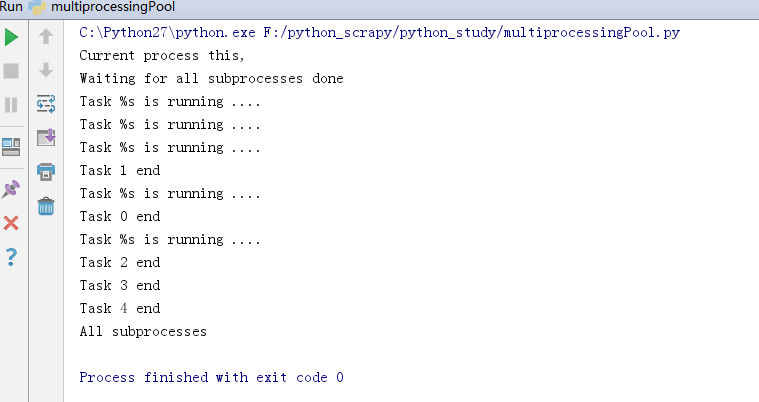
3.1.3 multiprocessing提供一个pool类来代表进程池
#!code:utf-8
from multiprocessing import Pool
import os,time,random
def run_task(name):
print('Task %s is running ....')
time.sleep(random.random()*3)
print('Task %s end' %name)
if __name__ == '__main__':
print 'Current process this,'
p = Pool(processes=3)
for i in range(5): #运行5个任务,但pool只允许3个进程,其余等待
p.apply_async(run_task,args=(i,))
print 'Waiting for all subprocesses done'
p.close() #close必须在join之前运行,调用close之后就不能再添加新的Process了
p.join()
print('All subprocesses')
- 运行结果: