kubenetes的整体架构
Kubernetes由两种节点组成:master节点和工作节点,前者是管理节点,后者是容器运行的节点。其中master节点中主要有3个重要的组件,分别是APIServer,scheduler和controller manager。APIServer组件负责响应用户的管理请求、进行指挥协调等工作;scheduler的作用是将待调度的pod绑定到合适的工作节点上;controller manage提一组控制器的合集,负责控制管理对应的资源,如副本(replication)和工作节点(node)等。工作节点上运行了两个重要组件,分别为kubelet和kube-proxy。前者可以被看作一个管理维护pod运行的agent,后者则负责将service的流量转发到对应的endpoint。在实际生产环境中,不少用户都弃用了kube-proxy,而选择了其他的流量转发组件。
Kubernetes架构可以用下图简单描述。可以看到,位于master节点上的APIServer将负责与master节点、工作节点上的各个组件之间的交互,以及集群外用户(例如用户的kubectl命令)与集群的交互,在集群中处于消息收发的中心地位;其他各个组件各司其职,共同完成应用分发、部署与运行的工作。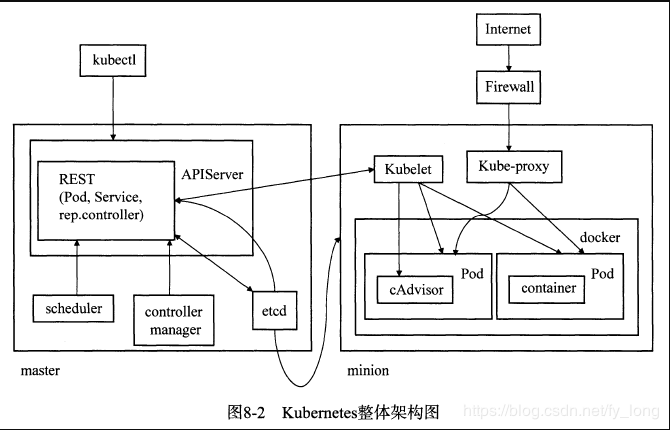
Kubernetes的架构体现了很多分布式系统设计的最佳实践,比如组件之间松耦合,各个组件之间不直接存在依赖关系,而是都通过APIServer进行交互。又比如,作为一个不试图形成技术闭环的项目,Kubernetes只专注于编排调度等工作,而在存储网络等方面留下插件接口,保证了整体的可扩展性和自由度,例如可以注册用户自定义的调度器、资源管理控制插件、网络插件和存储插件等,这使得用户可以在不hack核心代码的前提下,极大地丰富Kubernetes的适用场景。
API Server
Kubernetes APIServer负责对外提供Kubernetes API服务,它运行在Kubernetes的管理节点master节点中。作为系统管理指令的统一人口,APIServer担负着统揽全局的重任,任何对资源进行增删改查的操作都要交给APIServer处理后才能提交给etcd。
Kubernetes APIServer总体上由两个部分组成:HTTP/HTTPS服务和一些功能性插件。其中这些插件又可以分成两类:一部分与底层IaaS平台(Cloud Provider)相关,另一部分与资源的管理控制(admission control湘关。
APIServer的职能
APIserve咋为Kubernetes集群的全局掌控者,主要负责以下5个方面的工作。
- 对外提供基于RESTfuI的管理接口,支持对Kubernetes的资源对象譬如:pod, service,replication controller、工作节点等进行增、删、改、查和监听操作。例如,GET<apiserver-ip>:<apiserver-port>/api/v1/pods表示查询默认namespace中所有pod的信息。GET<apiserver-ip>:<apiserver-port>/api/v1/watch/pods表示监听默认namespace中所有pod的状态变化信息,返回pod的创建、更新和删除事件。该功能在前面的设计讲解中经常提到,这样一个ge睛求可以保持TCP长连接,持续监听pod的变化事件。
- 配置Kubernetes的资源对象,并将这些资源对象的期望状态和当前实际存储在etcd中供Kubernetes其他组件读取和分析。(Kubernetes除了etcd之外没有任何持久化节点)
- 提供可定制的功能性插件(支持用户自定义),完善对集群的管理。例如,调用内部或外部的用户认证与授权机制保证集群安全性,调用admission control插件对集群资源的使用进行管理控制,调用底层IaaS接口创建和管理Kubernetes工作节点等
- 系统日志收集功能,暴露在/logs API
- 可视化的API(用Swagger实现)
APIServer启动过程
APIServer的启动程序读者可以参考cmd/kube-apiserver/apiserver.go的main函数,其启动流程如下所示。
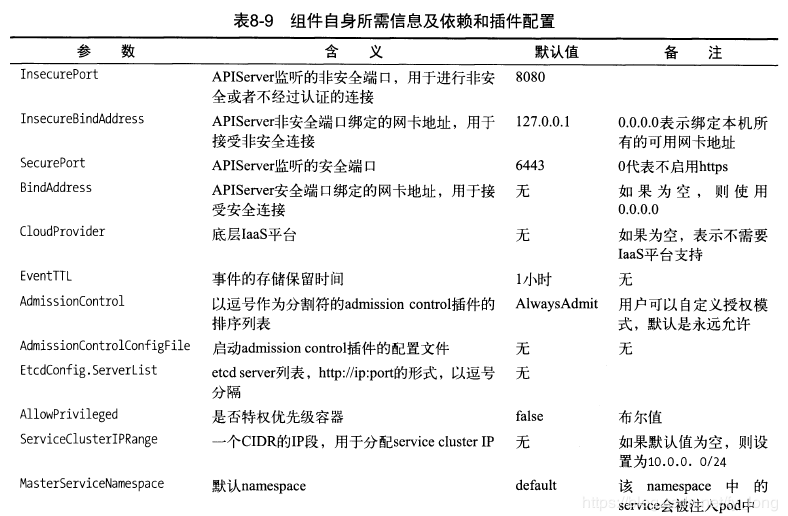
- 新建APIServer,定义一个APIServer所需的关键信息
首先是组件自身所需信息及其所需的依赖和插件配置,如表所示
- 接受用户命令行输入,为上述各参数赋值。
- 解析并格式化用户传入的参数,最后填充APIServer结构体的各字段。
- 初始化log配置,包括log输出位置、log等级等。Kubernetes组件使用glog作为日志函数库,Kubernetes能保证即使APIServer异常崩溃也能够将内存中的log信息保存到磁盘文件中。
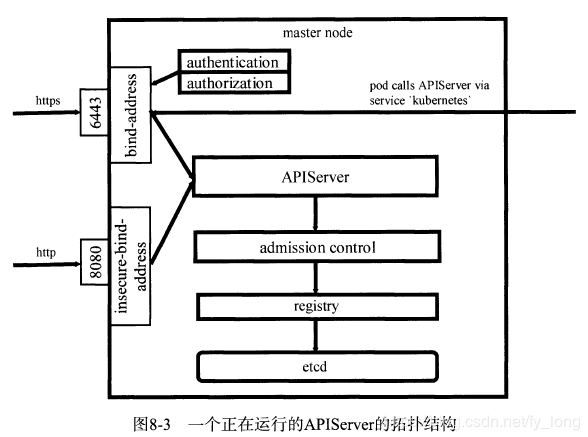
- 启动运行一个全新的APIServer。 APIServer作为master节点上的一个进程(也可以运行在容器中)通常会监听2个端口对外提供Kubernetes API服务,分别为一个安全端口和一个非安全端口,如图所示。
API Server对etcd的封装
Kubernetes使用etcd作为后台存储解决方案,而APIServer基于etcd实现了一套RESTfuI API,用于操作存储在etcd中的Kubernetes对象实例。所有针对Kubernetes资源对象的操作都是典型的RESTfuI风格操作,如下所示:
- GET /<resourceNamePlural> 返回类型为resourceName的资源对象列表,例如GET /pods返回一个pod列表。
- POST /<resourceNamePlural>根据客户端提供的描述资源对象的JSON文件创建一个新的资源对象。
- GET /<resourceNamePlural>/<name>根据一个指定的资源名返回单个资源对象信息,例如GET /pods/first返回一个名为first的pod信息。
- DELETE /<resourceNamePlural>/<name>根据一个指定的资源名删除一个资源对象。
- POST /<resourceNamePlural>/<name>根据客户端提供的描述资源对象的JSON文件创建或更新一个指定名字的资源对象。
- GET /watch/<resourceNamePlural>使用etcd的watch机制,返回指定类型资源对象实时的变化信息。
- GET /watch/<resourceNamePlural>/<name>使用etcd的watch机制,根据客户端提供的描述资源对象的JSON文件,返回一个名为name的资源对象实时的变化信息。
APIServer如何操作资源
APIServer将集群中的资源都存储在etcd中,默认情况下其路径都由/registry开始,用户可以通过传人etcd-prefix参数来修改该值。 当用户向APIServer发起请求之后,APIServer将会借助一个被称为registry的实体来完成对etcd的所有操作,这也是为什么在etcd中,资源的存储路径都是以registry开始的。
Kubernetes目前支持的资源对象很多,如表所示:
一次创建pod请求的响应流程
- APIServer在接收到用户的请求之后,会根据用户提交的参数值来创建一个运行时的pod对象
- 根据API请求的上下文和该pod对象的元数据来验证两者的namespace是否匹配,如不匹配则创建pod失败
- namespace验证匹配后,APIServer会向pod对象注入一些系统元数据,包括创建时间和uid等。如果定义pod时未提供pod的名字,则APIServe侩将pod的uid作为pod的名字
- API Server下来会检查pod对象中的必需字段是否为空,只要有一个字段为空,就会抛出异常并终止创建过程
- 在etcd中持久化该pod对象,将异步调用返回结果封装成restful.Response,完成操作结果反馈
- 至此,APIServer在pod创建的流程中的任务已经完成,剩余步骤将由Kubernetes其他组件(kube-scheduler和kubelet)通过watch APIServer继续执行下去
API Server如何保证API操作的原子性
由于Kubernetes使用了资源的概念来对容器云进行抽象,就不得不面临APIServer响应多个请求时竞争和冲突的问题。所以,Kubernetes的资源对象都设置了一个resourceVersion作为其元数据(详见pkg/api/v1/types.go的ObjectMeta结构体)的一部分,APIServer以此保证资源对象操作的原子性。
resourceVersion是用于标识一个资源对象内部版本的字符串,客户端可以通过它判断该对象是否被更新过。每次Kubernetes资源对象的更新都会导致APIServer修改它的值,该版本仅对当前资源对象和namespace限定域内有效。
scheduler
资源调度器本身经历了长足的发展,一向受到广泛关注。Kubernetes scheduler是一个典型的单体调度器。它的作用是根据特定的调度算法将pod调度到指定的工作节点上,这一过程通常被称为绑定(bind)。
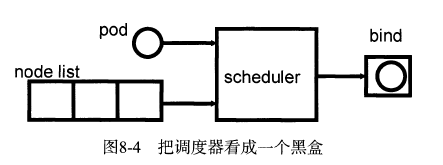
scheduler的输人是待调度pod和可用的工作节点列表,输出则是应用调度算法从列表中选择的一个最优的用于绑定待调度pod的节点。如果把这个scheduler看成一个黑盒,那么它的工作过程正如图所示。
scheduler的数据采集模型
不同于很多平台级开源项目(比如Cloud Foundry ), Kubernetes里并没有消息系统来帮助用户实现各组件间的高效通信,这使得scheduler需要定时地向APIServer获取各种各样它感兴趣的数据,比如已调度、待调度的pod信息,node状态列表、service对象信息等,这会给APIServe谴成很大的访问压力。
所以scheduler专门为那些感兴趣的资源和数据设置了本地缓存机制,以避免一刻不停的暴力轮询APIServer带来额外的性能开销。这里的缓存机制可以分为两类,一个是简单的cache对象(缓存无序数据,比如当前所有可用的工作节点),另一个是先进先出的队列(缓存有序数据,比如下一个到来的pod)。scheduler使用reflector来监测APIServer端的数据变化。
最后,我们总结一下scheduler调度器需要的各项数据、如何捕获这些数据,以及这些数据存储在本地缓存的什么数据结构中,如表所示。
scheduler调度算法
在Kubernetes的最早期版本中,scheduler为pod选取工作节点的算法是round robin —即依次从可用的工作节点列表中选取一个工作节点,并将待调度的pod绑定到该工作节点上运行,而不考虑譬如工作节点的资源使用情况、负载均衡等因素。这种调度算法显然不能满足系统对资源利用率的需求,而且极容易引起竞争性资源的冲突,譬如端口,无法适应大规模分布式计算集群可能面临的各种复杂情况。当然,这之后scheduler对调度器的算法框架进行了较大的调整,已经能够支持一定程度的资源发现。目前默认采用的是系统自带的唯一调度算法default,当然,scheduler调度器提供了一个可插拔的算法框架,开发者能够很方便地往scheduler添加各种自定义的调度算法。接下来将以default法为例,详细解析scheduler调度算法的整体设计。
Kubernetes的调度算法都使用如下格式的方法模板来描述:
func RegisterAlgorithmProvider(name string, predicateKeys, priorityKeys sets.String) string { //TODO }
其中,第1个参数即算法名(比如default),第2个和第3个参数组成了一个算法的调度策略。
Kubernetes中的调度策略分为两个阶段:Predicates和Priorities,其中Predicates回答“能不能”的问题,即能否将pod调度到某个工作节点上运行,而Priorities则在Predicates回答“能”的基础上,通过为候选节点设置优先级来描述“适合的程度有多高”。
具体到default算法,目前可用的Predicates包括:PodFitsHostPorts , PodFitsResources ,NoDiskConflict, NoVolumeZoneConflict, MatchNodeSelector, HostName, MaxEBSVoIumeCount和MaxGCEPDVoIumeCount。所以,工作节点能够被选中的前提是需要经历这几个Predicates条件的检验,并且每一条都是硬性标准。一旦通过这些筛选,候选的工作节点就可以进行打分(评优先级)了。
打分阶段的评分标准(Priorities)有7项:LeastRequestedPriority, BalancedResourceAllocation、SelectorSpreadPriority、NodeAffinityPriority、EqualPriority、ServiceSpreadingPriority和Image-LocalityPriority。每一项都对应一个范围是。}10的分数,0代表最低优先级,10代表最高优先级。除了单项分数,每一项还需要再分配一个权值(weight )。以default算法为例,它包含了LeastRequestedPriority, BalancedResourceAllocation, SelectorSpreadPriority和NodeAffmityPriority这三项,每一项的权值均为1。所以一个工作节点最终的优先级得分是每个Priorities计算得分的加权和,即Sum(score*weight)。最终,scheduler调度器会选择优先级得分最高的那个工作节点作为pod调度的目的地,如果存在多个优先级得分相同的工作节点,则随机选取一个工作节点。
scheduler的启动与运行
scheduler组件的启动程序放在plugin/and/kube-scheduler目录下,负责进行调度工作的核心进程为scheduler server,它的结构相对来说比较简单,主要的属性如表所示:

在程序入口的main函数中,首先完成对SchedulerServer的初始化工作,这是一个涵盖了要运行调度器所需要的参数的结构体,并且调用Run函数来运行一个真正的调度器。Run函数完成的事情如下:
- 收集scheduler产生的事件信息并构建事件对象,然后向APIServer发送这些对象,最终由APIServer调用etcd客户端接口将这些事件进行持久化。event来源非常广泛,除了scheduler外,它的来源还包括kubelet, pod, Docker容器、Docker镜像、pod Volume和宿主机等。
- 创建一个http server,默认情况下绑定到IP地址Address(见表8-12)上并监听10251端口。在启用对scheduler的profiling功能时,该server上会被注册3条路由规则(/debug/pprof/,/debug/pprof/profile和/debug/pprof/symbol),可以通过Web端对scheduler的运行状态进行辅助性检测和debug。
- 根据配置信息创建调度器并启动SchedulerServer。在启动调度器之前,需要进行一些初始化操作,这些初始化操作的结果将作为调度器的配置信息传入,如下所示:
-
- 客户端对象client,用于与APIServer通信。
- 用于缓存待调度pod对象的队列podQueue。
- 存储所有已经调度完毕的Pod的链表ScheduledPodLister。
- 存储已调度的所有pod对象的链表podLister,其中包括已经调度完毕的以及完成了调度决策但可能还没有被运行起来的pod。
- 存储所有node对象的链表NodeLister。
- 存储所有PersistentVolumes的链表PVLister。
- 存储所有PersistentVolumeClaims的链表PVCLister。
- 存储所有service对象的链表ServiceLister。
- 存储所有控制器的链表ControllerLister。
- 存储所有ReplicaSet的链表ReplicaSetLister。
- 用于关闭所有reflectors的channel, StopEverything。
- 用于操作ScheduledPodLister池的控制器scheduledPodPopulator,负责在完成调度的pod被更新时进行相应的操作。
- 用于提前更新pod在系统中被调度的状态,使得调度器能够提前感知的Modeler。
- 调度器的名字SchedulerName。
- 注册metrics规则,用于检测调度器工作的性能,包括调度延迟时间、binding延迟时间等。
controller manager
Kubernetes controller manager行在集群的master节点上,是基于pod API上的一个独立服务,它管理着Kubernetes集群中的各种控制器,包括读者已经熟知的replication controller和node controller。相比之下,APIServer负责接收用户的请求,并完成集群内资源的“增删改”,而controller manager系统中扮演的角色是在一旁默默地管控这些资源,确保它们永远保持在用户所预期的状态。
Contorller Manager启动过程
Contorller Manager启动过程大致分为以下几个步骤:
- 根据用户传入的参数以及默认参数创建kubeconfig和kubeClient。前者包含了controller manager工作中需要使用的配置信息,如同步endpoint, rc, node等资源的周期等;后者是用于与APIServer行交互的客户端。
- 创建并运行一个http server,对外暴露/debug/pprof/、/debug/pprof/profile, /debug/pprof/symbol和/metrics,用作进行辅助debug和收集metric数据之用。
- 按顺序创建以下几个控制管理器:服务端点控制器、副本管理控制器、垃圾回收控制器、节点控制器、服务控制器、路由控制器、资源配额控制器、namespace控制器,horizontal控制器、daemon sets制器、job控制器、deployment控制器、replicaSet控制器、persistent volume控制器(可细分为persistent volume claim binder , persistent volume recycler及persistent volume provision controller ), service account控制器,再根据预先设定的时间间隔运行。特别地,垃圾回收控制器、路由控制器仅在用户启用相关功能时才会被创建,而horizontal控制器、daemon set控制器、job控制器、deployment控制器、replicaSet控制器仅在extensions/vlbetal的API版本中会被创建。
- controller manager控制pod、工作节点等资源正常运行的本质,就是靠这些controller定时对pod、工作节点等资源进行检查,然后判断这些资源的实际运行状态是否与用户对它们的期望一致,若不一致,则通知APIServer进行具体的“增删改”操作。理解controller工作的关键就在于理解每个检查周期内,每种资源对象的实际状态从哪里来,期望状态又从哪里来。接下来,我们以服务端点控制器、副本管理控制器、垃圾回收控制器、节点控制器和资源配额控制器为例,分析这些controller的具体工作方式。
kubelet
kubelet组件是Kubernetes集群工作节点上最重要的组件进程,它负责管理和维护在这台主机上运行着的所有容器。本质上,它的工作可以归结为使得pod的运行状态(status)与它的期望值(spec)一致。目前,kubelet支持docker和rkt两种容器;而社区也在尝试使用C/S架构来支持更多container runtime与Kubernetes的结合。
kubelet的启动过程
- kubelet需要启动的主要进程是KubeletServer,它所需加载的重要属性包括kubelet本身的属性、接入的runtime容器所需的基础信息以及定义kubelet与整个集群进行交互所需的信息。
- 进行如下一系列的初始化工作。
- 选取APIServerList的第一个APIServer,创建一个APIServer的客户端。
- 如果上一步骤执行成功,则再创建一个APIServer的客户端用于向APIServer发送event对象。
- 初始化cloud provider。当然,如果集群的kubelet组件并没有运行在cloud provider上,该步骤将跳过。
- 创建并启动cAdvisor服务进程,返回一个cAdvisor的http客户端,IP和Port分别是localhost和CAdvisorPort的值。如果CAdvisorPort设置为0,将不启用cadvisor。
- 创建ContainerManager,为Docker daemon, kubelet等进程创建cgroups,并确保它们运行时使用的资源在限额之内。
- 对kubelet进程应用OOMScoreAdj值,即向/proc/self/oom_score_adj文件中写人OOMScoreAdj的值(默认值为-999 )。 OOMScoreAdj是用于描述在该进程发生内存溢出时被强行终止的可能性,分数越高,进程越有可能被杀死;其合法范围是[-1000, 1000]。换句话说,这里希望kubelet是最不容易被杀死的进程(之一)。
- 配置kubelet支持的pod配置方式,包括文件、url以及APIServer,支持多种方式一起使用。
- 初始化工作完成后,实例化一个真正的kubelet进程。重点值得关注的有以下几点:
- 创建工作节点本地的service和node的cache,并且使用list/watch机制持续对其进行更新。
- 创建DiskSpaceManager,用以与cadvisor配合进行工作节点的磁盘管理,这与kubelet是否接受新的pod在该工作节点上运行有密切关系。
- 创建ContainerRefManager,用以记录每个container及其对应的引用的映射关系,主要用于在pod更新或者删除时进行事件的记录。
- 创建VolumeManager,用以记录每个pod及其挂载的volume的映射关系。
- 创建OOMWatcher,用以从cadvisor中获取系统的内存溢出(Out Of Memory , OOM)事件,并对其进行记录。
- 初始化kubelet网络插件,可以指定传入一个文件夹中的plugin作为kubelet的网络插件。
- 创建LivenessManager,用以维护容器及其对应的probe结果的映射关系,用以进行pod的健康检查。
- 创建podCache来缓存pod的本地状态。
- 创建PodManager,用以存储和管理对pod的访问。值得注意的是,kubelet支持3种更新pod的方式,其中通过文件和url创建的pod是不能自动被APIServer感知的,称其为static pod。为了监控这些pod的状态,kubelet会为每个static pod在相同的namespace下创建一个同名的mirror pod,用以反应static pod的更新状态。
- 配置hairpin NAT。
- 创建container runtime,支持docker和rkt。
- 创建PLEG ( pod lifecycle event generator )。为了严密监控容器运行情况,kubelet在过去采用了为每个pod启动一个goroutine来进行周期性轮询的方法,即使在pod的spec没有变化的情况下依旧如此。这种做法会消耗大量的CPU资源,在性能上不尽如人意。为了改变这个现状,Kubernetes在v 1.2.0中引人了PLEG,专门进行pod变化的监控,避免了并发的pod worker来进行轮询工作。
- 创建镜像垃圾回收对象containerGC。
- 创建imageManager理容器镜像的生命周期,处理镜像的垃圾回收工作。
- 创建statusManager,用以向APIServer同步pod实际状态的更新。
- 创建probeManager,用作pod健康检查的探针。
- 初始化volume插件。
- 创建RuntimeCache,用以缓存pod列表。
- 创建reasonCache,用以缓存每个容器对应的最新的失败原因信息。
- 创建podWorker。每个pod将对应一个podWorker用以同步pod状态信息。
- kubelet启动完成后通过事件收集器向APIServer发送一个kubelet已经启动的event,表明集群新加人了一个新的工作节点,kubelet将这一过程称为BirthCry,即“出生的啼哭”。并且开始进行容器和镜像的垃圾回收,对应的时间间隔分别为1分钟和5分钟。
- 根据Runonce的值选择运行仅一次kubelet进程或在后台持续运行kubelet进程,如果Runonce为true,则kubelet根据容器配置文件的内容创建pod后就退出;否则,将以goroutine的方式持续运行kubelet。
- 另外,默认启用kubelet Server的功能,它将根据admin的配置创建HTTP Server或HTTPS Server,监听10250端口。同时,创建一个HTTP Server监听10255端口,用于heapster向kubelet收集统计信息。
kubelet与cAdvisor的交互
cAdvisor主要负责收集工作节点上的容器信息及宿主机信息,下面将一一进行介绍:
- 容器信息
- 获取容器信息的URL形如:/api/{api version}/containers/<absolute container name>。绝对容器名(absolute containere)与URL的对应关系如表所示。

-
- 绝对容器名/下包含整个宿主机上所有容器(包括Docker容器)的资源信息,而绝对容器名/docker下才包含所有Docker容器的资源信息。如果想获取特定Docker容器的资源信息,绝对容器名字段需要填入/docker/{container ID}。
- 宿主机信息
类似地,还可以访问URL: /api/{api version}/machine来获取宿主机的资源信息。要获取当前宿主机的资源信息。
kubelet如何同步工作节点状态
首先,kubelet调用APIServer API向etcd获取包含当前工作节点状态信息的node对象,查询的键值就是kubelet所在工作节点的主机名。
然后,调用cAdvisor客户端API获取当前工作节点的宿主机信息,更新前面步骤获取到的node对象。
这些宿主机信息包括以下几点:
- 工作节点IP地址。
- 工作节点的机器信息,包括内核版本、操作系统版本、docker版本、kubelet监听的端口、
- 工作节点上现有的容器镜像。
- 工作节点的磁盘使用情况—即是否有out of disk事件。
- 工作节点是否Ready。在node对象的状态字段更新工作节点状态,并且更新时间戳,则node controller就可以凭这些信息是否及时来判定一个工作节点是否健康。
- 工作节点是否可以被调度podo
最后,kubelet再次调用APIServer API将上述更新持久化到etcd里。