一、模拟登陆
1、为什么要进行模拟登陆
有时,我们需要爬取一些基于个人用户的用户信息(需要登陆后才可以查看)
2、为什么要需要识别验证码
因为验证码往往是作为登陆请求中的请求参数被使用
3、验证码识别:借助于线上的一款打码平台(超级鹰、云打码、打码兔)
超级鹰网站:http://www.chaojiying.com/about.html
超级鹰的使用流程:
1、没有就注册一个有的话直接登陆
2、点击 软件ID > 生成一个软件ID
3、下载实例代码:点击开发文档 > 选择python语言 > 点击下载
实例代码展示
import requests from hashlib import md5 class Chaojiying_Client(object): def __init__(self, username, password, soft_id): self.username = username password = password.encode('utf8') self.password = md5(password).hexdigest() self.soft_id = soft_id self.base_params = { 'user': self.username, 'pass2': self.password, 'softid': self.soft_id, } self.headers = { 'Connection': 'Keep-Alive', 'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)', } def PostPic(self, im, codetype): """ im: 图片字节 codetype: 题目类型 参考 http://www.chaojiying.com/price.html """ params = { 'codetype': codetype, } params.update(self.base_params) files = {'userfile': ('ccc.jpg', im)} r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers) return r.json() def ReportError(self, im_id): """ im_id:报错题目的图片ID """ params = { 'id': im_id, } params.update(self.base_params) r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers) return r.json() if __name__ == '__main__': chaojiying = Chaojiying_Client('用户名', '密码', '软件ID') #用户中心>>软件ID 生成一个替换 im = open('a.jpg', 'rb').read() #本地图片文件路径 来替换 a.jpg print(chaojiying.PostPic(im, 1902)) #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
下面用一个古诗词的网站作为演示上下应该在一起但是太长了故分开写了
先定义一个验证码识别的方法简单的封装下
def get_codeImg_text(imgPath,imgType): chaojiying = Chaojiying_Client('用户名', '密码', '软甲ID') #用户中心>>软件ID 生成一个替换 im = open(imgPath, 'rb').read()#本地图片文件路径 来替换 a.jpg return chaojiying.PostPic(im, imgType)['pic_str']
编写登陆爬虫
import requests from lxml import etree #前期准备工作 session = requests.Session() headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.64 Safari/537.36", } #两个url指向一样只是方便区分所以写了两个 url = "https://so.gushiwen.org/user/login.aspx?from=http://so.gushiwen.org/user/collect.aspx" login_url = 'https://so.gushiwen.org/user/login.aspx?from=http%3a%2f%2fso.gushiwen.org%2fuser%2fcollect.aspx' #请求登陆页面并且将登陆页面放到实例化的tree里 page_text = requests.session(url=url,headers=headers).text tree = etree.HTML(page_text) #解析验证码图片保存到本地 code_img_src = 'https://so.gushiwen.org'+tree.xpath('//*[@id="imgCode"]/@src')[0] code_img_data = requests.session(url=code_img_src,headers=headers).content #直接获取二进制流 with open("./code.jpg","wb") as f: f.write(code_img_data) #解析动态参数,动态参数往往都会隐藏在前台页面中 __VIEWSTATE = tree.xpath('//input[@id="__VIEWSTATE"]/@value')[0] __VIEWSTATEGENERATOR = tree.xpath('//input[@id="__VIEWSTATEGENERATOR"]/@value')[0] #使用打码平台识别出来的验证码图片数据 codeImg_text = get_codeImg_text("./code.jpg",1902) #整合所需要的数据 data = { #处理了动态参数 "__VIEWSTATE": __VIEWSTATE, "__VIEWSTATEGENERATOR": __VIEWSTATEGENERATOR, "from": "http://so.gushiwen.org/user/collect.aspx", "email": "www.zhangbowudi@qq.com", "pwd": "bobo328410948", "code": codeImg_text, "denglu": "登录", } #模拟登陆并把页面写入本地 page_text = requests.session(url=login_url,headers=headers,data=data).text with open("./login.html","w",encoding="utf-8") as f: f.write(page_text)
关于前面的动态参数
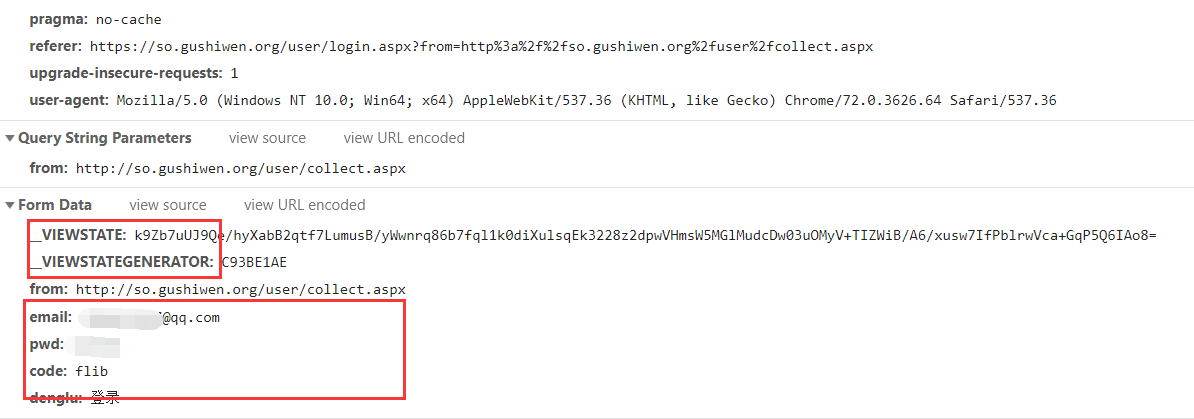
所以我们要找到上面那两个参数,不妨去前台看看
放到图片里的搜索框搜索下就可以了
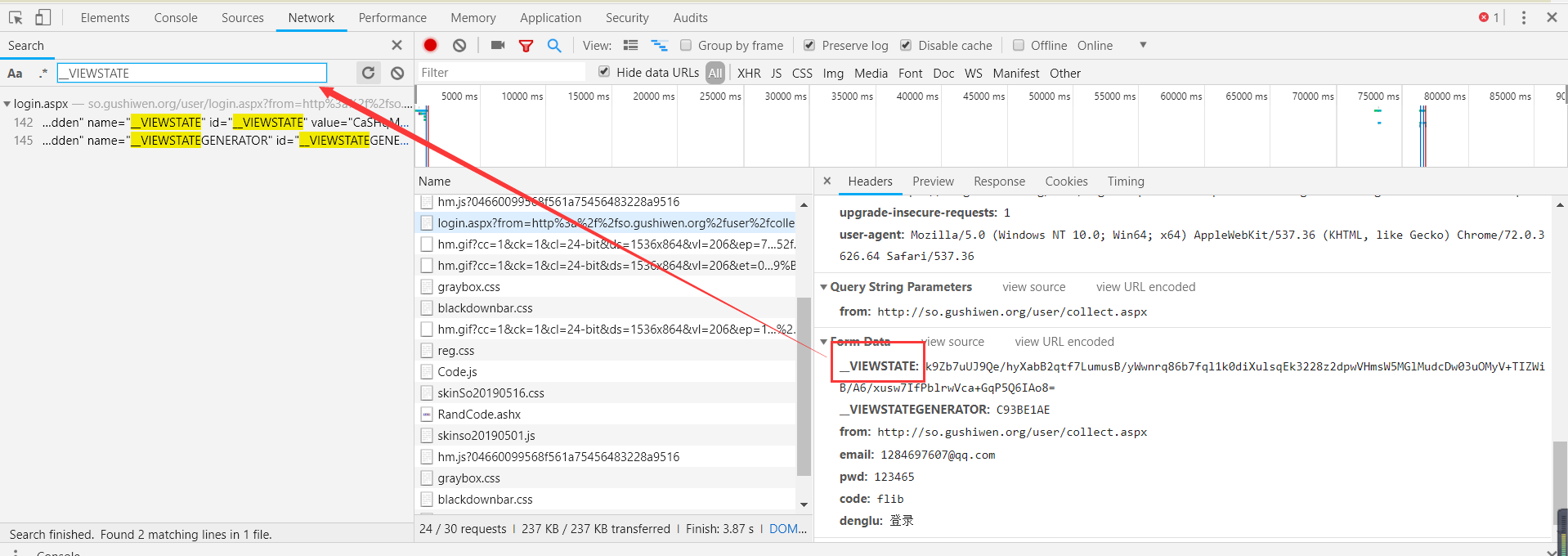
因为这两个也是作为参数发送到后端的所以不能少
因为用到了session所以该爬虫的所有的请求均为session
二、代理操作
给大家直接推荐个网址:里面有详细一些的描述在下就不在这里赘述了
因为是免费的所以成功率不大
http://www.goubanjia.com/
具体使用方法:
url = "https://www.baidu.com/s?ie=UTF-8&wd=ip" page_text = requests.get(url=url,headers=headers,proxies={"类型":"ip:端口号"}).text with open("./ip.html",'w',encoding="utf-8") as f: f.write(page_text)
三、线程池
线程池:尽可能用在耗时较为严重的操作中
使用模块: #导包 from multiprocessing.dummy import Pool #实例化 pool = Pool(4)#线程数 pool.map(func,iterable,chunksize=None) 可以基于异步实现:让参数1(func)对应的函数对参数2(iterable)对应的容器元素依次进行操作(基于异步的操作)
实例代码,效率对比:
import time pool = Pool(4) def func(url): print("正在请求:",url) time.sleep(2) print("请求完毕:",url) urls = [ "www.1.com", "www.2.com", "www.3.com", "www.4.com", ] start = time.time() for url in urls: func(url) print(time.time()-start) start2 = time.time() pool.map(fun,urls) print(time.time()-start2)