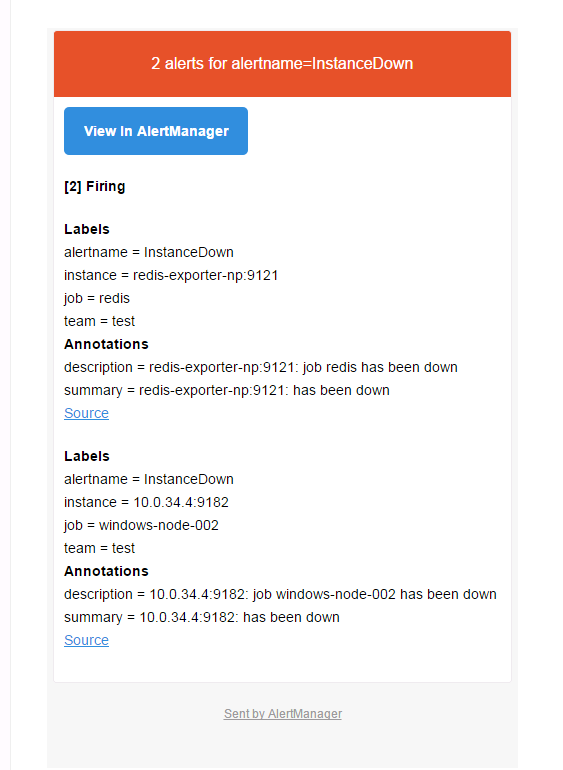
1、告警逻辑框架
Prometheus的告警逻辑框架:
1)指标获取:Prometheus从监控目标中获取指标数据;
2)设置规则:运维人员根据运维管理需要,设置告警规则(rule_files);
3)推送告警:在Pometheus中指定指定告警规则,并设置告警服务器(prometheus.yml),当发生符合告警的规则时,Prometheus就会将告警信息发送给设置的告警服务器;
4)发送告警:在告警服务器中,设置告警路由和告警接收,告警服务器将会根据告警管理配置将告警信息发送给告警接收器(email等);
5)处理告警:运维人员接收到告警信息后,对告警信息进行处理,保证被监控对象的正常运行。
2、指定告警服务和规则文件
告诉Promentheus,将告警信息发送给那个告警管理服务,以及使用那个告警规则文件。这里的告警服务在Kubernetes中部署,对外提供的服务名称为alertmanager,端口为9093。告警规则文件为“/etc/prometheus/rules/”目录下的所有规则文件。
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# 指定告警服务器
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
# 指定告警规则文件
rule_files:
- "/etc/prometheus/rules/*.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: 'redis'
static_configs:
- targets: ['redis-exporter-np:9121']
- job_name: 'node'
static_configs:
- targets: ['prometheus-prometheus-node-exporter:9100']
- job_name: 'windows-node-001'
static_configs:
- targets: ['10.0.32.148:9182']
- job_name: 'windows-node-002'
static_configs:
- targets: ['10.0.34.4:9182']
- job_name: 'rabbit'
static_configs:
- targets: ['prom-rabbit-prometheus-rabbitmq-exporter:9419']
3、设置告警规则
设置告警的规则,Prometheus基于此告警规则,将告警信息发送给告警服务。这将未启动的实例信息发送给告警服务,告知哪些实例没有正常启动。
#rules
groups:
- name: node-rules
rules:
- alert: InstanceDown # 告警名称
expr: up == 0 # 告警判定条件
for: 3s # 持续多久后,才发送
labels: # 标签
team: k8s
annotations: # 警报信息
summary: "{{$labels.instance}}: has been down"
description: "{{$labels.instance}}: job {{$labels.job}} has been down "
4、设置告警信息路由和接受器
这里设置通过邮件接收告警信息,当告警服务接收到告警信息后,会通过邮件将告警信息发送给被告知者。
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:25' # 发送信息邮箱的smtp服务器代理
smtp_from: 'xxx@163.com' # 发送信息的邮箱名称
smtp_auth_username: 'xxx' # 邮箱的用户名
smtp_auth_password: 'SYNUNQBZMIWUQXGZ' # 邮箱的密码或授权码
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: 'xxxxxx@aliyun.com' # 接收告警的邮箱
headers: { Subject: "[WARN] 报警邮件"} # 接收邮件的标题
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
5、验证
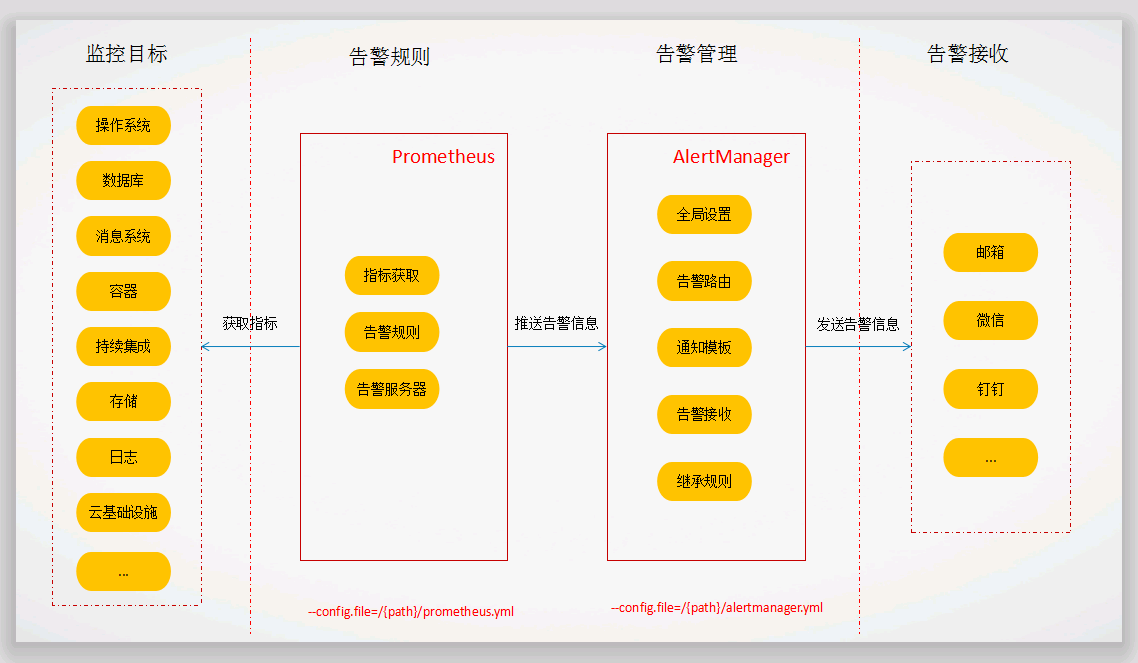
在方案中Prometheus所监控的实例中,redis和windows-node-002没有正常启动,因此根据上述的告警规则,应该会将这些信息发送给被告警者的邮箱。
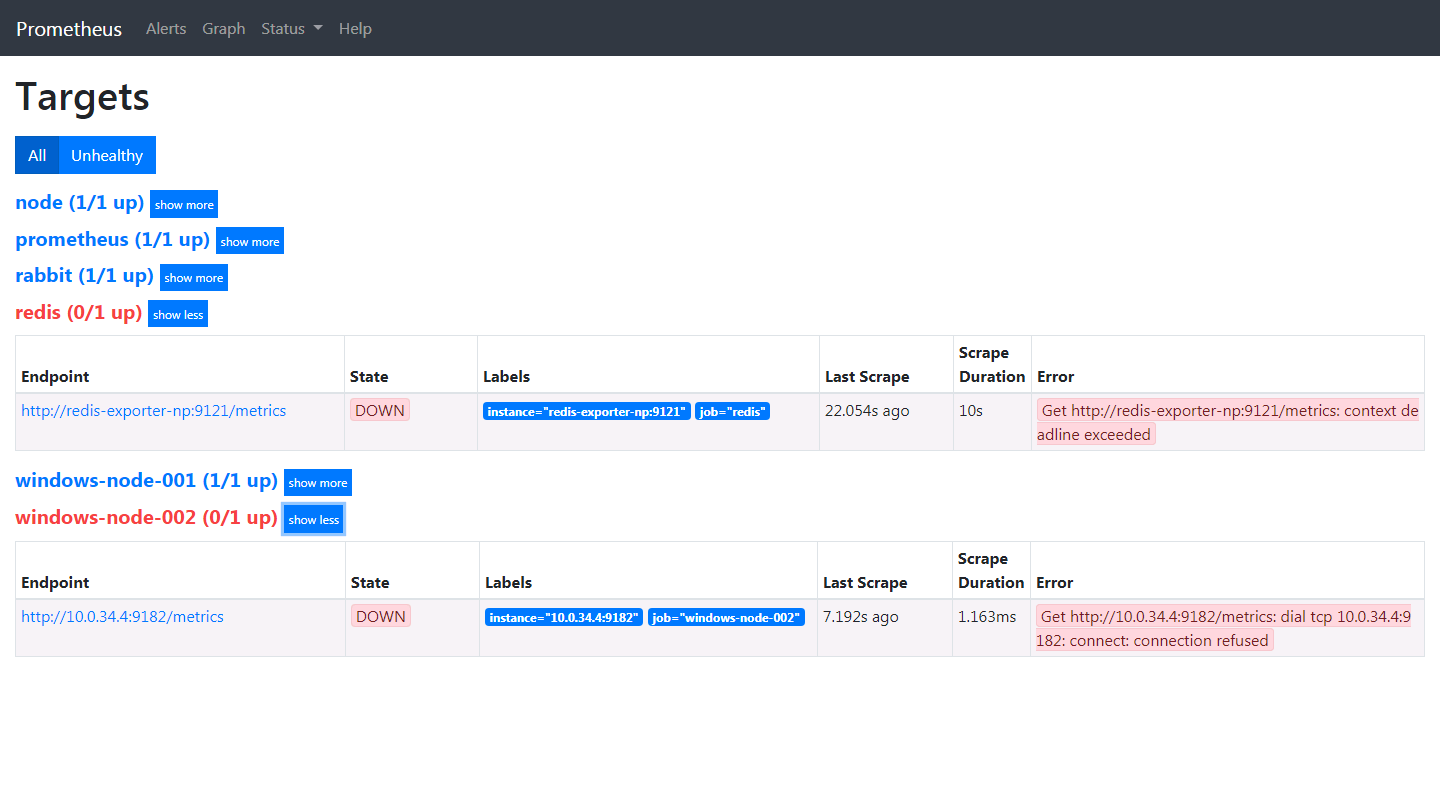
在被告警者的邮箱中,接收的告警信息如下。