URI & URL
URI,Uniform Resource Identifier,统一资源标识符。
URL,Uniform Resource Location,统一资源定位符。
URI 简单来理解就是标识/定义了一个资源,而 URL 在定义/标识资源的同时还需要描述如何访问到该资源。可以认为 URL 是 URI 的一个子集。
举个例子:
公司里每个人都有一个内部唯一的花名,这个花名其实就可以认为是 URI,它对应了公司内部唯一的一个人(资源)。当我需要找这个人时,虽然我知道了花名(URI),但是并找不到他人,因为我不知道他的工位,这时候就需要知道他的工位号如 13B-11 ,工位号+花名其实就是一个 URL,它指定了一个人以及怎么找到这个人的位置。上述例子可能并不规范,但是感觉这样比较容易理解区分。一般来说 URI 有一个通用的结构描述:
scheme:[//[user:password@]host[:port]][/]path[?query][#fragment]
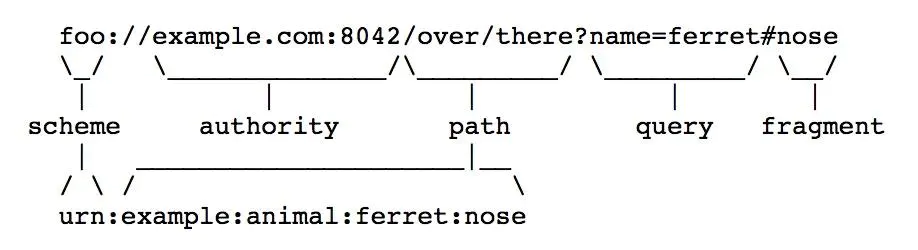
其实现在我们不必刻意去区分 URI / URL / URN 。在 [RFC3986]上已经明确说明这个点:
Future specifications and related documentation should
use the general term "URI" rather than the more restrictive terms
"URL" and "URN".
fragment
主要资源是由 URI 进行标识,URI 中的 fragment 用来标识次级资源。我理解看来,fragment 主要是用来标识 URI 所标识资源里的某个资源。
在 URI 的末尾通过 hash mark(#)作为 fragment 的开头,其中 # 不属于 fragment 的值。
https://domain/index#L18
这个 URI 中 L18 就是 fragment 的值。这有哪些特殊的地方呢?
-
#有别于?,?后面的查询字符串会被网络请求带上服务器,而 fragment 不会被发送的服务器; - fragment 的改变不会触发浏览器刷新页面,但是会生成浏览历史;
- fragment 会被浏览器根据文件媒体类型(MIME type)进行对应的处理;
- Google 的搜索引擎会忽略
#及其后面的字符串。
针对以上几点特性,分别介绍下 URI fragment 的应用。
特性 1 & 2 单页面路由
针对 1、2 这两个特性,目前主要的应用就是单页面路由。具体原理简单描述如下:JavaScript 提供了 location.hash 来操作当前 URI 的 fragment,同时提供了 Hashchange 事件监听 fragment 的变化。利用这两个 API 再结合上述特性 1、2 就可以实现一个简单前端路由。具体流程如下图:
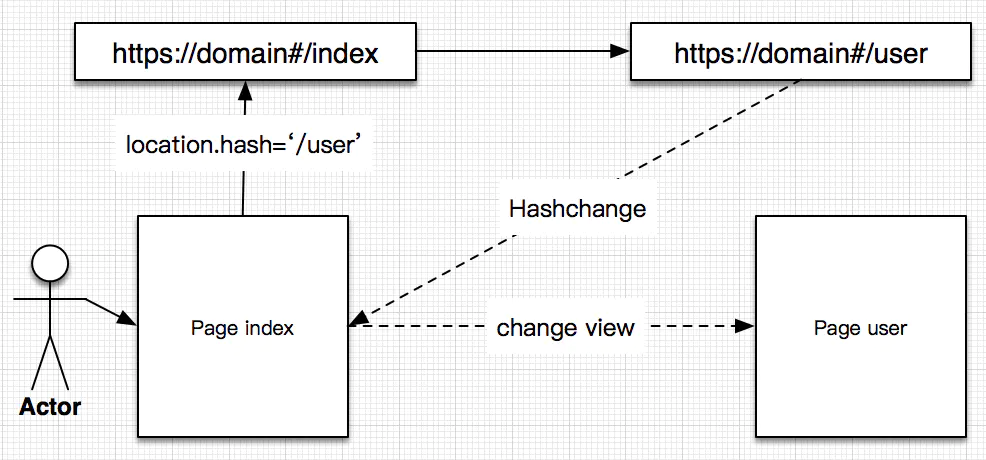
修改 location.hash 值,触发 hashchange 事件,JS 处理对应的逻辑,改变页面 UI 实现页面的跳转,并在浏览器中产生历史记录。
特性 3 HTML 锚点
在 HTML 中比较常见的一个应用 —— 页面内定位。在页面中通过设置标签的 id 属性来定义锚点,从而实现锚点定位。实际上锚点定位的实现正是依赖了 fragment 的特性 3。如这个 URI https://domain/index.html#L18,假设返回的文件类型是 text/html,则浏览器会读取 URI’s fragment,然后在页面中寻找 L18 这个锚点,并将页面滚动到该锚点的位置。
因此我们当点击 <a href="#top">top</a>时,实际上处理过程是 URI 的 hash 发生变化,然后浏览器读取新的 fragment,并寻找 DOM 中是否存在对应的锚点,将该锚点显示到页面中。在 MIME Type 为 HTML 或 XML 时,如https://domain/index.html#这个 URI 中是空的 fragment,则浏览器默认显示页面的最顶端。
特性 4
特性4 其实是针对 hash 模式前端路由来说的一个缺点。因为 fragment 会被 Google 搜索引擎忽略掉,因此对于用 hash 模式前端路由的应用的 SEO 来说是很不友好的。不过 Google 给了一个方案,就是在 # 紧跟一个 ! ,这样Google 搜索引擎就会将这个 URI 进行转换,如 https://domain/index.html#!L18转换后就成为了 https://domain/index.html?_escaped_fragment_=L18。这样搜索引擎就会携带上 URI’s fragment 直接去访问这个 URI,开发者可以利用这个 trick 优化网站的 SEO。
小结
- fragment 对于 HTML 文档来说就是页面内的定位标识符,可以实现 HTML 页面内的定位。当然浏览器针对不同类型的资源会有区分的处理 fragment;
- 利用 fragment 实现前端页面无刷新修改 Brower’s URI;
- 根据搜索引擎规则,可以优化无刷新修改页面的 SEO;