项目中有一个需求,对一个基类而言,拥有一个比较方法和拷贝方法,某些地方需要频繁地对这两个方法进行调用。对于所有子类而言,需要重写这两个方法,并在其中维护类内一些成员变量。例如有一个变量m_iMyVal,在Copy方法中需要维护this.m_iMyVal = data.m_iMyVal;在IsEqual方法中需要维护if(this.m_iMyVal != data.m_iMyVal) return false;...等等。当子类中的变量一旦多了,譬如一个类中拥有十余个甚至更多这样的变量,并且日后有可能删除或添加,维护起来就有点痛苦了,因为需要在两处都补充对应的方法,而且每一个都不能写漏写错。
这些子类一般都是数据类,在编写代码的时候往往是一口气写相当多的变量,如果写一个然后到两个地方编写对应的代码,这样可能的确出错率比较低,但是很容易打断思路;但是把所有变量写完后再去补充代码,就会有写漏写错之嫌,一旦写漏当时可能没有bug,后期查错起来非常痛苦,从而导致开发效率下降。另外麻烦的一点在于,不同类型的变量,比较方法和拷贝方法可能不尽相同(如浮点数需要eps,list需要循环比较等等)。
那么有没有写一个变量然后告诉系统这个变量是需要在比较和拷贝方法中补充代码的,然后有“人”帮我自动补充上去呢?由于笔者使用的是C#语言开发,自然而然想到了添加标签的方法,之后通过反射找到所有带有这种标签的成员变量,在比较和拷贝方法中直接进行操作即可。
但是担心这种做法由于反射有性能较低之嫌,因此暂时不作考虑,转而使用下面这种利用Python自动生成代码的方法。
利用Python读取文件,正则查询带有某些标签或者注释的变量,把这些变量收集起来,然后替换原文件的比较和拷贝方法即可。
那么工作流就变成了:
1.写需要的成员变量
2.如果需要自动为其生成代码,则添加对应的标签(不采用注释的方法是因为标签可以被自动补全,防止正则找错)。
3.执行批处理文件,自动把需要的文件生成代码(如果之前有这部分代码,则是替换)。
整个过程几乎不耽误什么时间,但是自动生成代码使得开发效率大大提升。
Python源码如下:


1 # -*- encoding:utf-8 -*-
2
3 import os
4 import sys
5 import re
6
7
8 def process_file(path):
9 keyword = 'debug_util.'
10 modify_flag = False
11
12 auto_start = "// python automatic generation start"
13 auto_end = "// python automatic generation end"
14 normalLabel = "\[NormalLabel\]"
15 floatLabel = "\[FloatLabel\]"
16 vec3Lable = "\[Vec3Label\]"
17
18 normalCmp = "[NormalLabel]"
19 floatCmp = "[FloatLabel]"
20 vec3Cmp = "[Vec3Label]"
21
22 with open(path, 'rb') as f:
23 txt = f.read()
24 # print ("txt is " + txt)
25 pattern = "(%s|%s|%s)[\s\S]+?public\s+\w+\s+(\w+)" % (normalLabel, floatLabel, vec3Lable)
26 matchStr = re.findall(pattern, txt)
27 # print (matchStr)
28 labelList = []
29 varList = []
30 for i, packed in enumerate(matchStr):
31 labelName = packed[0]
32 varName = packed[1]
33 labelList.append(labelName)
34 varList.append(varName)
35 # print (labelName + ".." + varName)
36
37 # 开始找类的名称
38 pattern = "public class (\w+)\s*:\s*SkillBaseData"
39 matchStr = re.findall(pattern, txt)
40 className = ""
41 for i, packed in enumerate(matchStr):
42 className = packed
43 break # 类名只会有一个
44
45
46 ## 找注释部分
47 index = 0
48 begin = txt.find(auto_start, index) + len(auto_start)
49 end = txt.find(auto_end, index)
50 copyContent = ""
51 equalContent = ""
52 for labelName, varName in zip(labelList, varList):
53 copyContent += "\t\t\tthis." + varName + " = data." + varName + ";\n"
54 if labelName == normalCmp:
55 equalContent += ("\t\t\tif(this.%s != data.%s) return 1;\n" % (varName, varName))
56 elif labelName == floatCmp:
57 equalContent += ("\t\t\tif(FloatNotEqual(this.%s, data.%s)) return 1;\n" % (varName, varName))
58 elif labelName == vec3Cmp:
59 equalContent += ("\t\t\tif(Vec3NotEqual(this.%s, data.%s)) return 1;\n" % (varName, varName))
60
61
62 auto_code = ""
63 auto_code += (("\n\t\tpublic override void CopyDataFrom(SkillBaseData baseData)\n\t\t{\n\t\t\tvar data = (%s)baseData;\n" % className) + copyContent + "\t\t}\n")
64 auto_code += (("\n\t\tpublic override int IsEqual(SkillBaseData baseData)\n\t\t{\n\t\t\tvar data = (%s)baseData;\n" % className) + equalContent + "\t\t\treturn 0;\n\t\t}\n")
65 print (txt[:begin] + auto_code + txt[end:])
66 new_txt = txt[:begin] + auto_code + "\t\t" + txt[end:]
67 with open(path, 'wb') as f:
68 f.write(new_txt)
69
70 def okPath(path):
71 if path.endswith("TestSkillData.cs"):
72 return True
73
74 return False
75
76 if __name__ == '__main__':
77 cwd = os.getcwd()
78 _len = len(cwd) - 22 # 22是最后一级目录的长度,在这里是魔法数字,据需求而改动,当然也可以用其他方法找到需要的目录= =。
79 cwd = cwd[:_len] + 'SkillDerivedData'
80 print(cwd)
81 # cwd = cwd + '/Package/Script/Python/'
82 directiory = os.walk(cwd)
83 for root, dirs, files in directiory:
84 for f in files:
85 if okPath(f):
86 process_file(os.path.join(root, f))
87 # print("name is " + f)
写完C#直接跑下面这个bat即可。
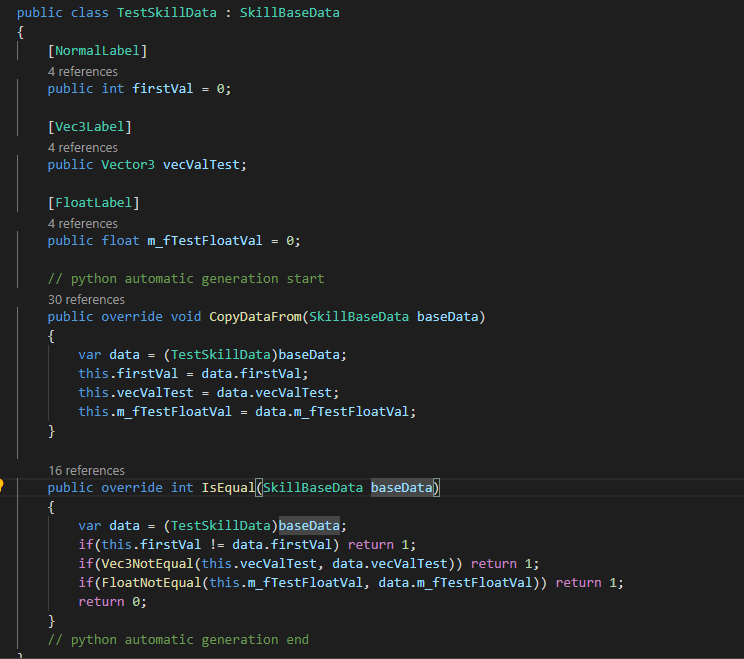
最后生成代码的效果如下图所示,感觉还算比较美观的= =。(针对三种不同的标签提供了不同的处理方法):
总的来说,学会了一种新的处理问题的方法,收获挺大的。最后感谢一下教会我这种方法的@仓鼠和提供正则帮助的@聪哥。