思考
如果tf读取文件是这样的:1. 读取文件, 2. 将文件数据送入内存计算。 那么就意味这读取和计算是串行的,效率低下。
那么提高效率的一个简单途径,就是将两个步骤并行化。

这样就可以把数据读取与数据计算分离。
tf改进
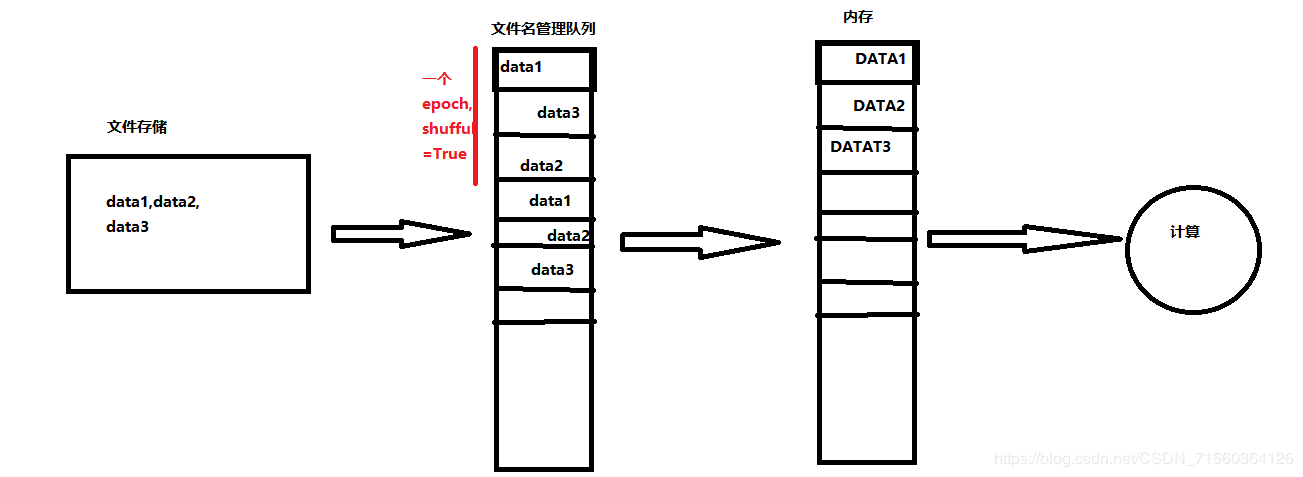
tf的数据读取更进一步,添加了一个文件名管理队列,用于先将需要处理的数据的文件存储起来,这样就可以与epoch(将所有数据训练一遍称为一个epoch)紧密结合起来,如果需要两个epoch,只需要把这些文件在文件名管理队列存储两遍即可。需要使用这个数据的时候,直接从这个文件名管理队列中获取文件,然后获取文件放到内存队列。这里文件名管理队列会在最后一个文件的后面添加结束标志,用于使程序抛出一个 OutOfRangeError 异常,提示已经完成所有文件读取和计算,程序结束。
相关函数
创建文件名队列:
filename_queue = tf.train.string_input_producer(fliename_list, shuffle=False, num_epochs=NUM)
从文件名队列中读取数据:
reader = tf.WholeFileReader()
key, value = reader.read(filename_queue)
上一步创建了队列,下一步需要填充队列,系统拿到计算数据进行计算:
tf.train.start_queue_runners()
参考:
《21个项目玩转tensorflow》