一、基本定义
Apache Kafka是一个基于分布式发布 - 订阅模式的消息系统,可以处理大量的数据,并能够将消息从一个端点传递到另一个端点。 Kafka适合离线和在线消息消费。 Kafka将消息按顺序保存在磁盘上,并在群集内复制以防止数据丢失。 Kafka构建在ZooKeeper同步服务之上。 它与Apache Storm和Spark非常好地集成,用于实时流式数据分析。
扩展:
什么是消息系统或消息队列(MQ:Message Queue):
消息系统负责将数据从一个应用程序传输到另外一个应用程序,使得应用程序可以专注于处理逻辑,而不用过多的考虑如何将消息共享出去。
分布式消息系统基于可靠消息队列的方式,消息在应用程序和消息系统之间异步排队。实际上,消息系统有两种消息传递模式:一种是点对点,另外一种是基于发布-订阅(publish-subscribe)的消息系统。
二、Kafka核心概念
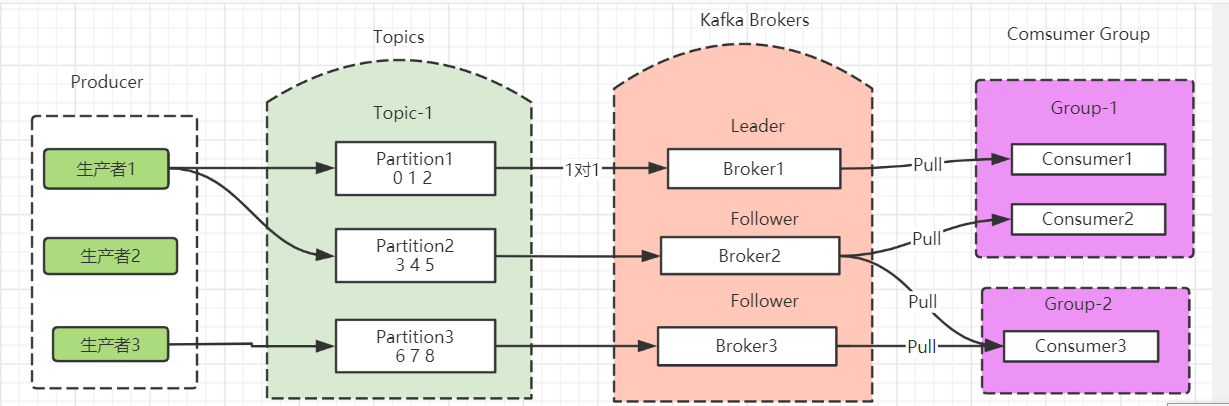
Producer(生产者):消息的生产者
Consumer(消费者):消息消费者
Broker(代理者):消息服务者,用于连接生产者和消费者,也就是Kafka Server
Topic(主题):消息的类别
Partition(分区):每个topic可以分为多个partition,每个partition在存储层面是一个append log文件。
为什么要进行分区呢?最根本的原因就是:
1、kafka基于文件进行存储,当文件内容大到一定程度时,很容易达到单个磁盘的上限,因此,采用分区的办法,一个分区对应一个文件,这样就可以将数据分别存储到不同的server上去,
2、另外这样做也可以负载均衡,容纳更多的消费者。partition的个数对应了消费者和生产者的并发度。例如partition的个数为3,则集群中最多同时有3个线程的消费者并发处理数据。
三、Kafka消息队列原理图