一、TensorFlow
TensorFlow 是一个使用数据流图进行数值计算的开源软件库。图中的节点表示数学运算,而图边表示在它们之间传递的多维数据阵列(又称张量)。灵活的体系结构允许你使用单个API将计算部署到桌面、服务器或移动设备中的一个或多个CPU或GPU。
被定义为“最流行”、“最被认可”的开源深度学习框架, 拥有产品级的高质量代码,有 Google 强大的开发、维护能力的加持,整体架构设计也非常优秀。
TensorFlow 是 Google 的开源人工智能工具。它提供了一个使用数据流图进行数值计算的库。可以运行在多种不同的有着单或多 CPU 和 GPU 的系统,甚至可以在移动设备上运行。它拥有深厚的灵活性、真正的可移植性、自动微分功能,并且支持 C++ / Python (Go,Java,Lua,Javascript,或者是R)。
但由于 TensorFlow 的每个计算流都必须构造为一个静态图,且缺乏符号性循环,增加了计算困难。TensorFlow 在执行性能方面并无优势,对 RNN 支持不如 Theano,缺乏许多预先训练的模型。
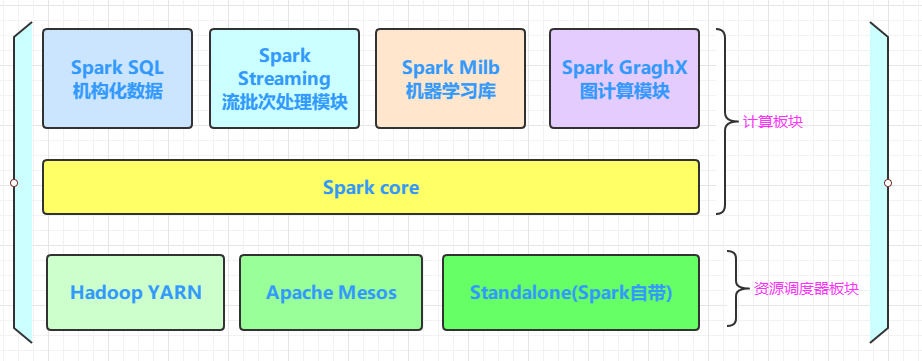
二、Apache Spark
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎 。现在形成一个高速发展应用广泛的生态系统。
1、易用性
2、更快的速度
3、通用性
4、丰富的资源管理器
三、Deeplearning4j:为 Java 用户量身定制
Deeplearning4j(以下简称:DL4J)是 Java 和 Scala 环境下的一个开源分布式的深度学习项目,可以构建、定型和部署神经网络。
DL4J 与 Hadoop 和 Spark 集成,支持分布式 CPU 和 GPU,为商业环境,而非研究工具目的所设计。DL4J 支持 YARN 与 RBM、DBN、CNN、RNN、RNTN 和 LTSM等多种深度网络架构,还对矢量化库 Canova 提供支持。
DL4J 使用 Java 语言实现,本质上比 Python 快,在图像识别、欺诈检测和自然语言处理方面的表现出众。