背景:
公司在做一个项目,大概功能就是一个通行闸机的人脸识别系统,要经过门禁的人注册了之后,系统就会存储一张原始的图片在服务器的数据文件夹里面,包括了永久的存储和一些访客注册临时存储。一天周五的时候要使用
df -h查看根目录已经被占用98%,根目录挂载的分区有50G大小;当时显示的是还有3.8G可用,按照每个人脸产生的数据只有200K大小的话,根据每天通过的人流量计算也不会产生太多的数据。 周一的时候,有电话打过来,说是系统不能正常使用了,想想可能是那个存储被占满了吧!登陆上去看,果然根目录所在分区已经被占用满了,当时想着两种方法:
- 给数据目录扩容,因为挂载
/的分区是LVM卷- 清除现在文件系统中的一些大的文件
计划A: 找到 / 目录下的大文件(当时没有截图)
使用find命令找到/目录中的大日志文件。
1.第一步找出大于500M的日志文件。
find / -type f -name "*.log" -size +500M
# 找到了这个日志文件,用ls -l查看有3.8G
/wls/appsystems/nginx-1.14.0/install/logs/access.log
2.把该文件复制到其它目录中
防止误删除,即使删除了也能够找回来,-a保持原来的属性,防止恢复的时候没有了原来的文件属性,导致程序报错。
# home目录下挂载了一个分区
cp -a /wls/appsystems/nginx-1.14.0/install/logs/access.log /home/
3.清除日志文件
>/wls/appsystems/nginx-1.14.0/install/logs/access.log
当时就使用这种方法清理出来了一部分的空间,但是到了中午的时候,发现又快满了,当时还是想的事给这个目录分区扩容,但是仔细的想了想,按照平时的用户量来看的话肯定不会增长的这么快。于是就放弃了扩容开始找数据为什么增加得那么快的原因。
计划B:找出数据异常增加的原因对症下药
1.使用du命令查看占用比较大的目录
先从/目录下查看占用比较大的目录。当时这个目录占用的47G,这是清理之后的。
du -sh ./*
-s size 查看大小
-h 以可读的方式查看显示G或者M为单位
-m 以M为单位显示
只用-s的话默认单位是K
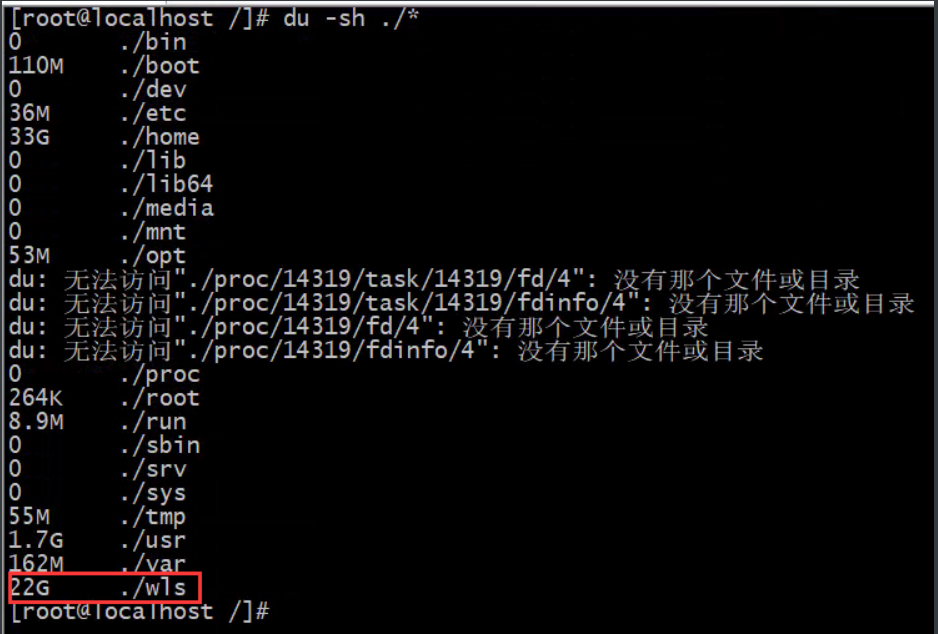
然后逐级的向下查找最大的产生数据的目录。最后确定是在/wls/files/FTR/faceFile/image/目录下,正好对应的是存储人脸数据的目录。如何查看他的变化情况?
2.查看数据目录单位时间变化量
我们查看目录所占的大小使du命令,再结合watch命令就可以查看到指定单位时间的变化了。
watch -n 1 -d "du -sm ./*"
-n 更新的频率单位s
-d 不同的显示高亮
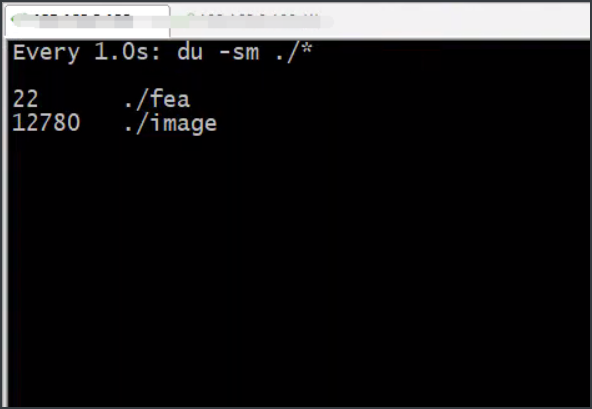
通过这样的方式查看到image目录发生的变化,我们直接观察了五分钟变化了多少,当时计算差不多5分钟差不多增加了100M左右。当时就确定了肯定是系统出问题了。
3.查看五分钟内产生的内容确定原因
通过find命令把5min钟之内产生的数据导出来,看看到底是产生了哪些数据。
# 在数据产生的目录下执行的。
find ./ -type f -mmin -5|xargs cp -t /opt/save/
cd /opt/save/
tar -czvf export_save.tar.gz ./save
sz export_save.tar.gz
把这个包导到了windows桌面上,解压查看。

原因出来了,一人注册只可能出现一次,而且这一张图片还出现了4次,通过原来watch命令还知道,这个数据还在不断的产生。总结出来肯定是程序出了问题,打电话找开发,从根源上解决问题。
最后:使用shell脚本清洗脏数据
从linux中查找出这个前缀开头的数据。
# 因为查看结果的数据比较多所以只需要查看开头和结尾即可
find ./ -type f -name "20000009_6ae05_*" |xargs ls -lh |head
find ./ -type f -name "20000009_6ae05_*" |xargs ls -lh |tail
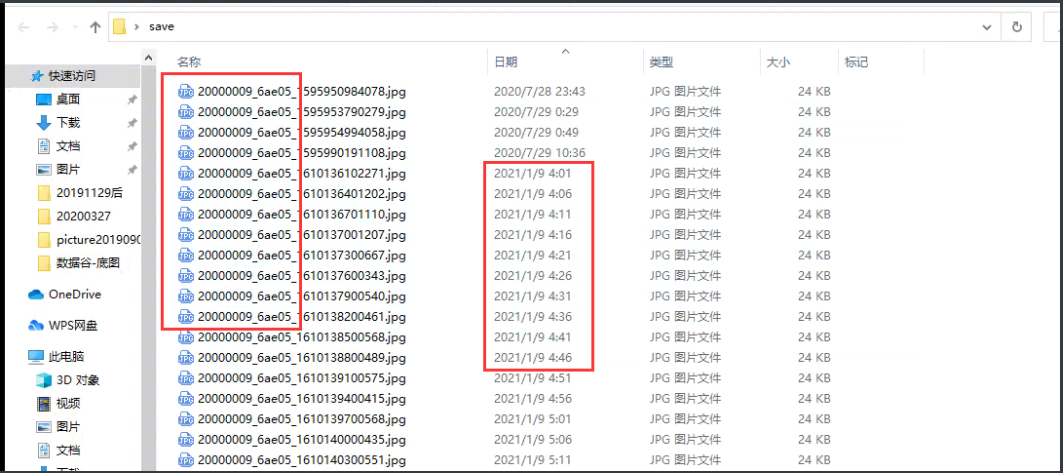
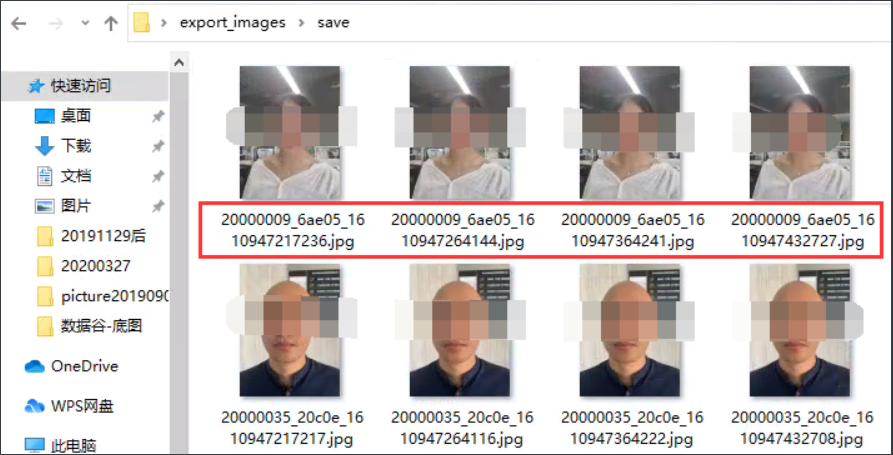
结合上面的两种结果来看,重复数据每五分钟会产生一次,重复图片的前缀都是相同的,故障发生的时间是在 2021-1-9 4:00之后。那么之后产生的数据就有两种,一种是程序产生的重复图片,还有一种是正常使用产生的图片。确定逻辑关系。
- 某文件名前缀2021-1-9 4:00 之前的数据是正常的数据。之后的如果有重复的就脏数据。
- 找出2021-1-9 4:00 之后的重复照片。
- 查看该照片在2021-1-9 4:00之前是否有,如果有就把2021-1-9 4:00之后的删除。
- 如果没有就不用操作。
注: 在2021-1-9之后可能也有每天注册的新用户,但是用户量应该不是很大,因为我们是在1-18号处理得,之后新用户也可能产生新的重复文件,但是那个找起来就比较复杂了,于是就先清除了2021-1-9 4:00之后大部分的重复文件。
1.找出2021-1-9 4:00 之后的重复照片
# 找出2021-1-9 4:00 之后的重复照片
find ./ -type f -newermt "2021-1-9 4:00" >~/out-19400-image.txt
# 去重并截取前缀,按数字排序。再次输出统计结果。
cat out-19400-image.txt |sort|cut -c 3-17|uniq -c|sort -n > after1-9-4.txt
结果类似这样。
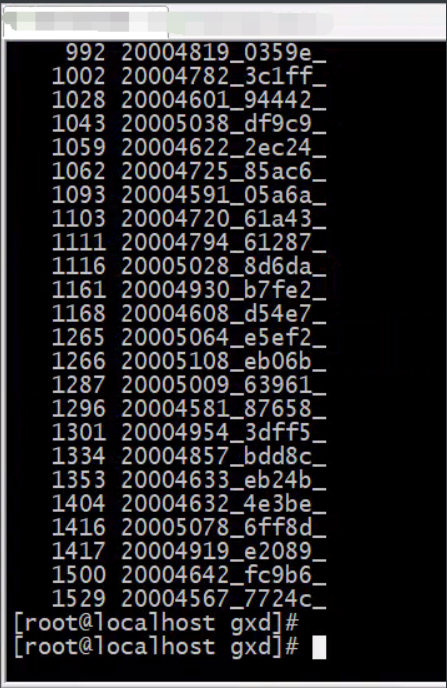
然后我只要文件名,需要再次处理一次;然后再按照上面的逻辑来编写脚本。
cat after1-9-4.txt |awk -F' ' '{print $2}' > filename_fina.txt
处理之后的文件前缀之后的结果。
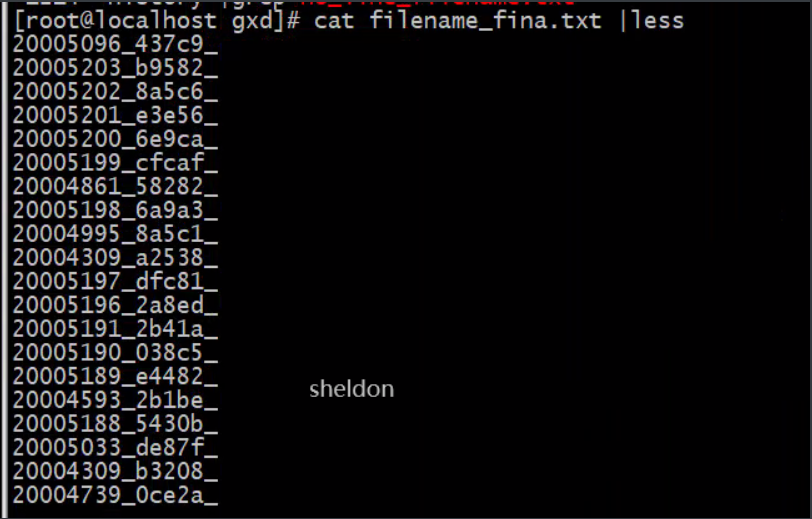
2.编写脚本
[root@localhost gxd]# vi clean.sh
#!/bin/bash
dir='/wls/files/FTR/faceFile/image/'
# 2020-1-9 4:00之后的图片且>=10张的文件前缀
for i in `cat filename_fina.txt`;do
#for i in "20004788_d2d9e_";do
# 查看在2020-1-9 4:00之前是否有记录
num_pic=`find $dir -type f -name "${i}*" ! -newermt "2021-1-9 4:00"|wc -l`
if [ $num_pic -ne 0 ];then
echo "这张图片在2020-1-9 4:00之前有记录了 前缀${i} 执行操作mv"
find $dir -type f -name "$i*" -newermt "2021-1-9 4:00" |xargs mv -t /home/laji
echo "============================================================="
else
echo -e "这张图片在2020-1-9 4:00之后才有记录 前缀${i}
不进行操作"
echo "============================================================="
fi
done
执行的效果。
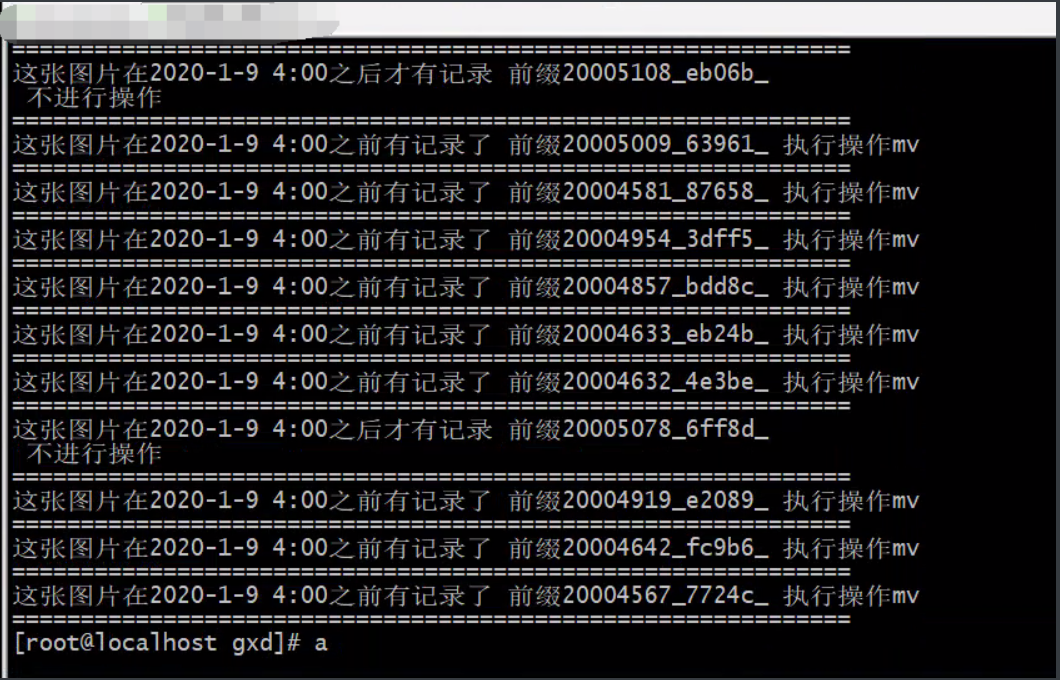
最后清理出来的空间。
清理出来重复的内容。