一、JDK 和 JRE 有什么区别?
-
JDK:Java Development Kit 的简称,java 开发工具包,提供了 java 的开发环境和运行环境。
-
JRE:Java Runtime Environment 的简称,java 运行环境,为 java 的运行提供了所需环境。
具体来说 JDK 其实包含了 JRE,同时还包含了编译 java 源码的编译器 javac,还包含了很多 java 程序调试和分析的工具。简单来说:如果你需要运行 java 程序,只需安装 JRE 就可以了,如果你需要编写 java 程序,需要安装 JDK。
关联:java的跨平台特性
原理:在不同的操作系统上可以安装不同版本的jdk,jdk中拥有jvm(虚拟机)可以去运行同样的字节码文件。
俗称:程序编写一次,可以在不同的操作系统上运行,只要该操作系统安装对应的版本的jdk。
二、Java环境变量配置
JAVA_HOME: jdk安装路径
path: %JAVA_HOME%/bin 配置命令文件的位置。
classpath: %JAVA_HOME%/lib 配置类库文件的位置。
注意:(如果在编译后就去执行java字节码文件的话就可以不用去配置,如果想去单独的运行之前生成的class字节码文件,那么最好去配置下)。
path与classpath的区别?
path:在任意目录下都能找到javac和java工具。
classpath:在任意目录下都能找到字节码文件。
基本常识:
1、如果一个源文件中什么内容都没有,是不会生成字节码文件的。
2、如果一个类中没有主方法,编译正常,运行报错(找不到入口函数)。
3、主方法是特殊的方法,当运行程序时,JVM会从类中的入口方法(main)里的第一条语句开始执行,注意: 一个类中可以没有main方法,如果没有main方法的类不能独立运行,会依赖于其他类执行。
4、一个java文件中只能有一个public修饰的类,但可以存在没有public 修饰的类,一个类的前面修饰了public ,其类名必须和文件名相同,若没有声明public 类名和文件名可以不同。
三、Java中关键字、保留字、标识符、常量的概念
关键字:设计java的时候赋予特殊意义的单词,所有的关键字字母全部小写
保留字:java中现在还没有赋予它特殊意义,以后可能会用,预留起来,例如:goto const
标识符: 给 Java 程序中变量、类、方法等命名的符号。
命名规则:① 标识符可以由字母、数字、下划线(_)、美元符($)组成,但不能包含 @、%、空格等其它特殊字符,不能以数字开头。
② 不能够使用java中的关键字 保留字作为我们的标识符。
③ 不建议使用已经存在的类名作为我们自己的类,命名做好做到见名知意。
④ 类名首字母大写,方法名 变量名使用 驼峰 式写法。
常量: 看成是一个固定不变的值。
常量的两种方式:字面直接量、final修饰常值变量
变 量 的 类 型 :① 成员变量:直接声明在类中的变量,如果用户没有赋值,那么系统会分配默认值。
②局部变量:声明在方法里面,(如:方法的形参,或者是代码块中)局部变量在使用之前必须得 初始化赋值,否则会编译报错。
四、Java基本数据类型、引用类型
1、基本数据类型、引用类型定义
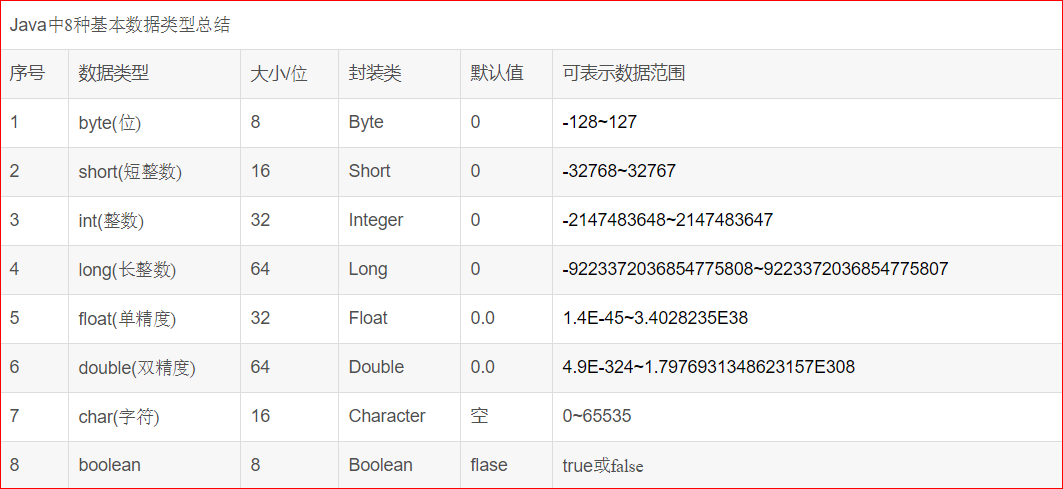
基本数据类:Java 中有八种基本数据类型“byte、short、int、long、float、double、char、boolean”
引用类型:new 创建的实体类、对象、及数组
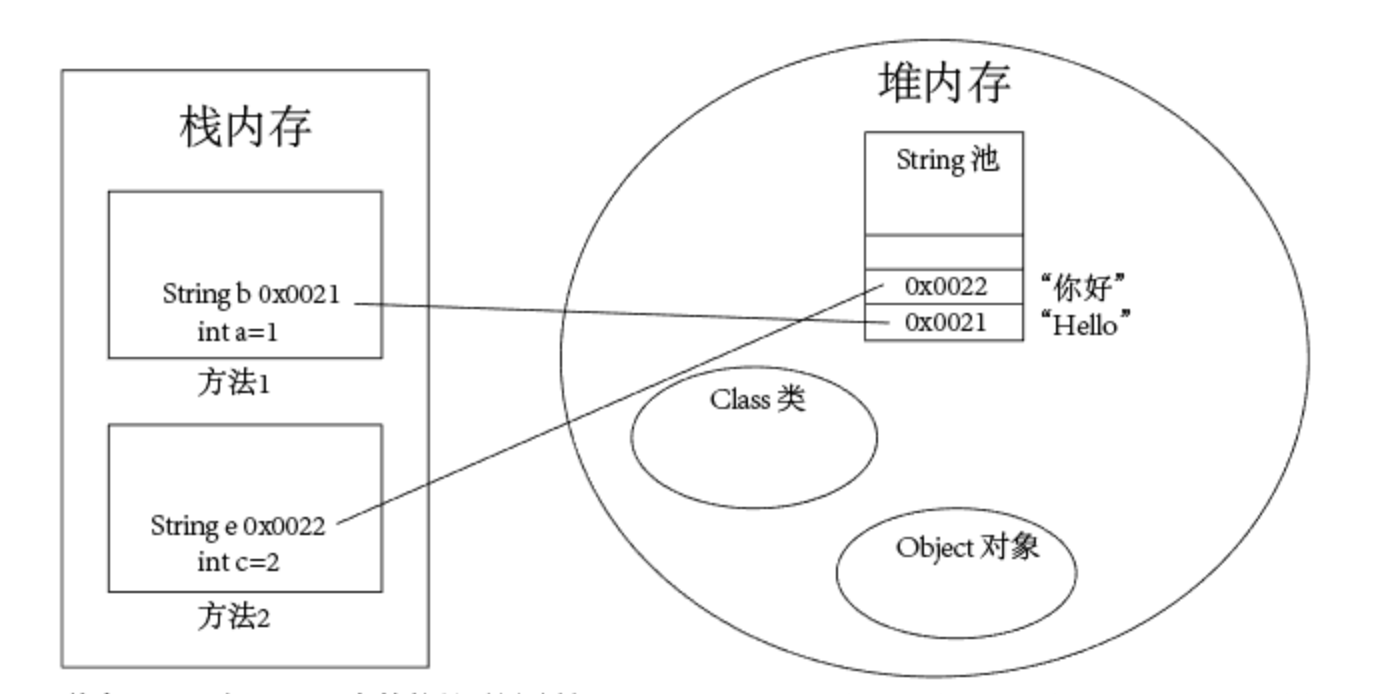
2、基本数据类型、引用类型在内存中的存储方式
基本数据类型:存放在栈内存中,用完就消失。
引用类型:在栈内存中存放引用堆内存的地址,在堆内存中存储类、对象、数组等。当没用引用指向堆内存中的类、对象、数组时,由 GC回收机制不定期自动清理。
3、基本类型、引用类型内存简单说明图如下:String b,String e存储的是引用地址。
五、数值类型的等级高低、类型转换
1、byte < short(char) <int < long < float < double
自动类型转换(隐式转换):将低等级类型的变量或者字面直接量 赋值给 高等级类型的变量 进行保存起来的过程。
强制类型转换: 将高等级的变量或者字面直接量 进行转换 让其与左边的变量类型相同或者更低的过程 eg int a = (int)2.35;或者int a = (short)2.35
注意:表达式计算出的结果取决于表达式中出现的最高等级的数据类型,根据该类型判断结果是否发生强制转换(表达式计算后的结果类型决定了 左边变量的数据类型)
2、char类型与数值类型转换问题
char类型的值或者变量 赋值给数值类型的变量保存时 ,会自动隐式转换。
数值类型的变量 赋值给 char类型的变量保存时 一定要强制转换。
数值类型的值 赋值给 char类型的变量保存时 可以不用强制转换,但不保证显示结果。
3、问:byte b = 0;其中0默认是int类型。为什么可以赋值给byte类型变量保存,并且不需要强制转换?
答:因为0这个字面直接量赋值给 byte的变量保存时,只考虑0这个值是否在btye类型保存值的范围内【-128,,127】,不考虑数据类型等级的高低
注意: byte a = 10+15; 只要字面直接量运算结果不超出范围,正确;有变量进行运算,要注意最高类型。
4、问:short s = 10; s = s +1;有没有错?原因?
short s = 10; s += 1 有没有错?原因?
答:(1)有错,因为1是int类型,整个表达式计算后的结果是int类型,而左边变量的类型是short类型,不符合语法。
(2)没错,因为+=是一个整体赋值运算符,表示将1这个值累加到s变量里去,累加过程中不考虑数值的类型。
5、浮点型:不能够精确的表示一个小数,他只能用无限接近于该数的一个数据去表示。浮点数默认类型是 double。精度更加高的类型使用 BigDecimal 。
6、字符型:用bit 来表示位 eg: 1byte = 8 bit
常用的表示形式:
-
-
- 通过字面直接量的表示形式
- 通过字符编码的表示形式
- 通过十六进制的表示形式
- 通过转译符存储特殊字符
-
注意:任何一个字符都有字符编码(十进制数),但不是任何一个十进制数都对应一个字符。byte short类型的变量进行运算时,计算结果会自动强制转换为int类型。
int a = 'a'+1; char c = (char)a; Console.WriteLine(c);
分析一下:
-
- ‘a’+1,是将a的编码加上1,结果为98,将98保存到变量a中。
- 然后,将98转换为对应的字符,转换的结果就是字符’b’,将其保存到变量c中。
- 最后输出变量c,就输出了字符b。
7、instanceof用来判断引用数据类型的变量 的所属类型。
六、数据过长和溢出
过长:数据超出了变量能够保存的值的范围

溢出:不同类型变量之间(数值类型:小数和整数)相互传值产生的精度损失。
七、原码、反码、补码
原码就是符号位加上真值的绝对值, 即用第一位表示符号, 其余位表示值。
反码的表示方法是:正数的反码是其本身;负数的反码是在其原码的基础上, 符号位不变,其余各个位取反。
补码的表示方法是:正数的补码就是其本身;负数的补码是在其原码的基础上, 符号位不变, 其余各位取反, 最后+1。 (即在反码的基础上+1)
举例:十进制数 原码 反码 补码

那么计算机为什么要使用补码呢?
首先,根据运算法则减去一个正数等于加上一个负数, 即: 1-1 = 1+(-1), 所以计算机被设计成只有加法而没有减法, 而让计算机辨别”符号位”会让计算机的基础电路设计变得十分复杂,于是就让符号位也参与运算,从而产生了反码。
用反码计算, 出现了”0”这个特殊的数值, 0带符号是没有任何意义的。 而且会有[0000 0000]和[1000 0000]两个编码表示0。于是设计了补码, 负数的补码就是反码+1,正数的补码就是正数本身,从而解决了0的符号以及两个编码的问题: 用[0000 0000]表示0,用[1000 0000]表示-128。
注意-128实际上是使用以前的-0的补码来表示的, 所以-128并没有原码和反码。使用补码, 不仅仅修复了0的符号以及存在两个编码的问题, 而且还能够多表示一个最低数。 这就是为什么8位二进制, 使用补码表示的范围为[-128, 127]。
八、位运算(&、|、^、>>、<<、>>>)
1、位运算概述
从现代计算机中所有的数据二进制的形式存储在设备中。即0、1两种状态,计算机对二进制数据进行的运算(+、-、*、/)都是叫位运算,即将符号位共同参与运算的运算。
口说无凭,举一个简单的例子来看下CPU是如何进行计算的,比如这行代码:
int a = 35;
int b = 47;
int c = a + b;计算两个数的和,因为在计算机中都是以二进制来进行运算,所以上面我们所给的int变量会在机器内部先转换为二进制在进行相加:
35: 0 0 1 0 0 0 1 1
47: 0 0 1 0 1 1 1 1
————————————————————
82: 0 1 0 1 0 0 1 0 所以,相比在代码中直接使用(+、-、*、/)运算符,合理的运用位运算更能显著提高代码在机器上的执行效率。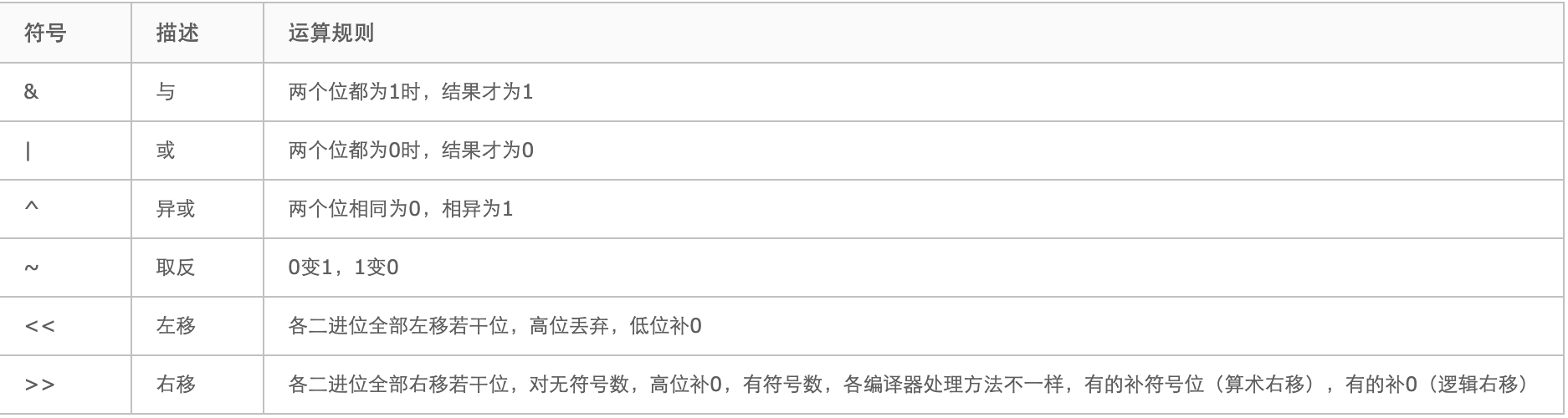
2、按位与运算符(&)
定义:参加运算的两个数据,按二进制位进行“与”运算。运算规则:0&0=0 0&1=0 1&0=0 1&1=1
总结:两位同时为1,结果才为1,否则结果为0。
例如:3&5 即 0000 0011& 0000 0101 = 0000 0001,因此 3&5 的值得1。
注意:负数按补码形式参加按位与运算。
与运算的用途:
1)清零
如果想将一个单元清零,即使其全部二进制位为0,只要与一个各位都为零的数值相与,结果为零。
2)取一个数的指定位
比如取数 X=1010 1110 的低4位,只需要另找一个数Y,令Y的低4位为1,其余位为0,即Y=0000 1111,然后将X与Y进行按位与运算(X&Y=0000 1110)即可得到X的指定位。
3)判断奇偶
只要根据最未位是0还是1来决定,为0就是偶数,为1就是奇数。因此可以用if ((a & 1) == 0)代替if (a % 2 == 0)来判断a是不是偶数。
3.按位或运算符(|)
定义:参加运算的两个对象,按二进制位进行“或”运算。运算规则:0|0=0 0|1=1 1|0=1 1|1=1
总结:参加运算的两个对象只要有一个为1,其值为1。
例如:3|5即 0000 0011| 0000 0101 = 0000 0111,因此,3|5的值得7。
注意:负数按补码形式参加按位或运算。
或运算的用途:
1)常用来对一个数据的某些位设置为1
比如将数 X=1010 1110 的低4位设置为1,只需要另找一个数Y,令Y的低4位为1,其余位为0,即Y=0000 1111,然后将X与Y进行按位或运算(X|Y=1010 1111)即可得到。
4、异或运算符(^)
定义:参加运算的两个数据,按二进制位进行“异或”运算。 运算规则:0^0=0 0^1=1 1^0=1 1^1=0
总结:参加运算的两个对象,如果两个相应位相同为0,相异为1。
异或的几条性质:
1、交换律
2、结合律 (a^b)^c == a^(b^c)
3、对于任何数x,都有 x^x=0,x^0=x
4、自反性: a^b^b=a^0=a;
异或运算的用途:参考Java异或详解
1)翻转指定位
比如将数 X=1010 1110 的低4位进行翻转,只需要另找一个数Y,令Y的低4位为1,其余位为0,即Y=0000 1111,然后将X与Y进行异或运算(X^Y=1010 0001)即可得到。
2)与0相异或值不变
例如:1010 1110 ^ 0000 0000 = 1010 1110
3)交换两个数
void Swap(int &a, int &b){
if (a != b){
a ^= b;
b ^= a;
a ^= b;
}
}
5、取反运算符 (~)
定义:参加运算的一个数据,按二进制进行“取反”运算。运算规则:~1=0 ~0=1
总结:对一个二进制数按位取反,即将0变1,1变0。
异或运算的用途:
1)使一个数的最低位为零
使a的最低位为0,可以表示为:a & ~1。~1的值为 1111 1111 1111 1110,再按"与"运算,最低位一定为0。因为“ ~”运算符的优先级比算术运算符、关系运算符、逻辑运算符和其他运算符都高。
6、左移运算符(<<) 、 右移运算符(>>)
左移运算符 << :将一个运算对象的各二进制位全部左移若干位(左边的二进制位丢弃,右边补0)。相当于该数乘以2。
右移运算符>>:将一个数的各二进制位全部右移若干位,正数左补0,负数左补1,右边丢弃。相当于该数除以2
举例:
/* 分别计算 12 >> 2 和 -12 >> 2 的结果: * -------------------------------------------------- */ 1. 12 >> 2 在做运算前,我们需要将十进制数转成二进制数,即可直观看出运算逻辑。 12的二进制数为(int类型为32bit):0000 0000 0000 0000 0000 0000 0000 1100 右移,顾名思义即将二进制的每一位数都向右移位,这里12移动2位后,高位补0:0000 0000 0000 0000 0000 0000 0000 0011 转换为十进制数后为:3 所以 12 >> 2 = 3 2. -12 >> 2 -12的二进制数为:1111 1111 1111 1111 1111 1111 1111 0100 延伸:负数的二进制,即正数的补码(其正数的反码加1) 12的反码:1111 1111 1111 1111 1111 1111 1111 0011 补码(反码+1):1111 1111 1111 1111 1111 1111 1111 0100 //注意:二进制加法是遇2进1,类似于十进制加法是遇10进1 故-12的二进制即:1111 1111 1111 1111 1111 1111 1111 0100 向右移2位,高位补1:1111 1111 1111 1111 1111 1111 1111 1101 转换位十进制数后为:-3
7、 无符号右移运算符>>>
不管正负标志位为0还是1,将该数的二进制码整体右移,左边部分总是以0填充,右边部分舍弃。
注意:Java的编写规则是没有<<<符号的。
var temp = -14 >>> 2 = 1073741820 变量 temp 的值为 -14 (即二进制的 11111111 11111111 11111111 11110010),向右移两位后等于 1073741820 (即二进制的 00111111 11111111 11111111 11111100)。
九、a++ 和 ++a
int a = 10;
System.out.println(a++);//10
System.out.println(a);//11
a += a++;
System.out.println(a);//22
System.out.println(a++);//22
System.out.println(a);//23
a += ++a;
System.out.println(a);//47
System.out.println(++a);//48
a = a + a++;
System.out.println(a);//96
System.out.println(++a);//97
十、数组
创建一维数组
1、声明数组: 数据类型[ ] 数组名称; eg: int[ ] a; 数组名称存储在栈中,通过地址将数据存在堆空间中。
2、分配内存空间: 数组名称 = new 数据类型[ int length ]; eg: a = new int[5]; new 出来的存储在堆中。
注意:声明并分配内存空间可以两部合成一步 eg int[] a = new int[5];
动态创建方式: Int[] ages = new int[5]; 静态创建方式:: Int[] ages = new int[]{12,33,11}; 或者 Int[] ages = {12,33,11}
创建二维数组: 数组中的每一个元素是一个一维数组。 创建方式: int[][] arrays = new int[5][ 4];
有关数组更多的知识参考:为什么很多编程语言中数组都是从 0 开始编号?
十一、Arrays类操作数组的常用方法
1、boolean equals(array1,array2):比较两个数组是否相等。
String[] str1={"1","2","3"};
String[] str2={"1","2",new String("3")};
System.out.println(Arrays.equals(str1, str2));//结果是:true
2、String toString(array):把数组array转换成一个字符串。
3、void sort(array):对数组array的元素进行升序排列。
int[] score ={79,65,93,64,88};
Arrays.sort(score);//给数组排序
String str = Arrays.toString(score);
System.out.println(str);
4、void fill(array,val):把数组array所有元素都赋值为val。
//fill方法:把数组中的所有元素替换成一个值
int[] num={1,2,3};
//参数1:数组对象
//参数2:替换的值
Arrays.fill(num, 6);
System.out.println(Arrays.toString(num));//打印结果:[6, 6, 6]
5、int binarySearch(array,val):查询元素值val在数组array中的下标。(前提是数组有序,因为这是基于二分搜索法,如果数组没有排序,则结果是不确定的。)
看案例:
int[] data = new int[] {5,8,6,7,2,9,1,0};
Arrays.sort(data);
System.out.println("数组是: "+ Arrays.toString(data));
System.out.println("6对应的下标是:" + Arrays.binarySearch(data, 6));
System.out.println("3对应的下标是:" + Arrays.binarySearch(data, 3));
System.out.println("4对应的下标是:" + Arrays.binarySearch(data, 4));
System.out.println("9对应的下标是:" + Arrays.binarySearch(data, 9));
System.out.println("-1对应的下标是:" + Arrays.binarySearch(data, -1));
System.out.println("11对应的下标是:" + Arrays.binarySearch(data, 11));
输出的结果为
数组是: [0, 1, 2, 5, 6, 7, 8, 9] 6对应的下标是:4 3对应的下标是:-4 4对应的下标是:-4 9对应的下标是:7 -1对应的下标是:-1 11对应的下标是:-9
对于元素6和9的下标为4和7是没有疑问的,可是为什么对于数组中没有的元素会返回不同的负数呢?想解决这个问题我们就要去看一看Arrays.binarySearch() 方法的源码了。
public static int binarySearch(int[] a, int key) {
return binarySearch0(a, 0, a.length, key);
}
private static int binarySearch0(int[] a, int fromIndex, int toIndex,
int key) {
int low = fromIndex;
int high = toIndex - 1;
while (low <= high) {
int mid = (low + high) >>> 1;
int midVal = a[mid];
if (midVal < key)
low = mid + 1;
else if (midVal > key)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found.
}
可以看到Arrays.binarySearch0()方法是利用二分法来查找数据的,最后对于不存在于数组中的数据的下标返回值是 return -(low + 1)
它对于非数组中的值的返回是这样的:假设该数据存在于数组中,并按照大小顺序排列,此时的low值是假设该数据在数组中的下标,所以上面的例子中当查找3和4时,就认为数组是[0, 1, 2, 3, 5, 6, 7, 8, 9]和[0, 1, 2, 4, 5, 6, 7, 8, 9],故返回值都是-4,当查找-1时,此时认为数组是[-1,0, 1, 2, 5, 6, 7, 8, 9],故返回值是-1,同样的,查找11时,认为数组是[0, 1, 2, 5, 6, 7, 8, 9, 11],返回值是-9。总结以下四点
[1] 该搜索键在范围内,但不是数组元素,由1开始计数,得“ - 插入点索引值”;
[2] 该搜索键在范围内,且是数组元素,由0开始计数,得搜索值的索引值;
[3] 该搜索键不在范围内,且小于范围(数组)内元素,返回–(fromIndex + 1);
[4] 该搜索键不在范围内,且大于范围(数组)内元素,返回 –(toIndex + 1)。
6、copyof(array,length):把数组array复制成一个长度为length的新数组。
//copyOf:把一个原有的数组内容复制到一个新数组中
int[] a={1,2,3};
//参数1:原数组 参数2:新数组的长度
int[] b=Arrays.copyOf(a, a.length);
System.out.println(Arrays.toString(b));
//a和b的地址码不同