数据流(任务并行库 TPL)
TPL 数据流库向具有高吞吐量和低滞后时间的占用大量 CPU 和 I/O 操作的应用程序的并行化和消息传递提供了基础。 它还能显式控制缓存数据的方式以及在系统中移动的方式。 为了更好地了解数据流编程模型,请考虑一个以异步方式从磁盘加载图像并创建复合图像的应用程序。 传统编程模型通常需要使用回调和同步对象(例如锁)来协调任务和访问共享数据。 通过使用数据流编程模型,您可以从磁盘读取时创建处理图像的数据流对象。 在数据流模型下,您可以声明当数据可用时的处理方式,以及数据之间的所有依赖项。 由于运行时管理数据之间的依赖项,因此通常可以避免这种要求来同步访问共享数据。 此外,因为运行时计划基于数据的异步到达,所以数据流可以通过有效管理基础线程提高响应能力和吞吐量。
System.Threading.Tasks.Dataflow 命名空间提供基于角色的编程模型,用以支持粗粒度数据流和流水线操作任务的进程内消息传递。TDP的主要作用就是Buffering Data和Processing Data,在TDF中,有两个非常重要的接口,ISourceBlock<T> 和ITargetBlock<T>接口。继承于ISourceBlock<T>的对象时作为提供数据的数据源对象-生产者,而继承于ITargetBlock<T>接口类主要是扮演目标对象-消费者。在这个类库中,System.Threading.Tasks.Dataflow名称空间下,提供了很多以Block名字结尾的类,ActionBlock,BufferBlock,TransformBlock,BroadcastBlock等9个Block,我们在开发中通常使用单个或多个Block组合的方式来实现一些功能,以下逐个来简单介绍一下。
BufferBlock
BufferBlock是TDF中最基础的Block。BufferBlock提供了一个有界限或没有界限的Buffer,该Buffer中存储T。该Block很像BlockingCollection<T>。可以用过Post往里面添加数据,也可以通过Receive方法阻塞或异步的的获取数据,数据处理的顺序是FIFO的。它也可以通过Link向其他Block输出数据。
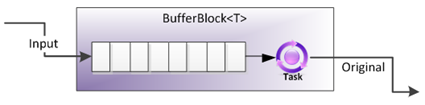
简单的同步的生产者消费者代码示例:
private static BufferBlock<int> m_buffer = new BufferBlock<int>();
// Producer
private static void Producer()
{
while(true)
{
int item = Produce();
m_buffer.Post(item);
}
}
// Consumer
private static void Consumer()
{
while(true)
{
int item = m_buffer.Receive();
Process(item);
}
}
// Main
public static void Main()
{
var p = Task.Factory.StartNew(Producer);
var c = Task.Factory.StartNew(Consumer);
Task.WaitAll(p,c);
}
ActionBlock
ActionBlock实现ITargetBlock,说明它是消费数据的,也就是对输入的一些数据进行处理。它在构造函数中,允许输入一个委托,来对每一个进来的数据进行一些操作。如果使用Action(T)委托,那说明每一个数据的处理完成需要等待这个委托方法结束,如果使用了Func<TInput, Task>)来构造的话,那么数据的结束将不是委托的返回,而是Task的结束。默认情况下,ActionBlock会FIFO的处理每一个数据,而且一次只能处理一个数据,一个处理完了再处理第二个,但也可以通过配置来并行的执行多个数据。
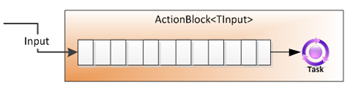
先看一个例子:
public ActionBlock<int> abSync = new ActionBlock<int>((i) =>
{
Thread.Sleep(1000);
Console.WriteLine(i + " ThreadId:" + Thread.CurrentThread.ManagedThreadId + " Execute Time:" + DateTime.Now);
}
);
public void TestSync()
{
for (int i = 0; i < 10; i++)
{
abSync.Post(i);
}
Console.WriteLine("Post finished");
}

可见,ActionBlock是顺序处理数据的,这也是ActionBlock一大特性之一。主线程在往ActionBlock中Post数据以后马上返回,具体数据的处理是另外一个线程来做的。数据是异步处理的,但处理本身是同步的,这样在一定程度上保证数据处理的准确性。下面的例子是使用async和await。
public ActionBlock<int> abSync2 = new ActionBlock<int>(async (i) =>
{
await Task.Delay(1000);
Console.WriteLine(i + " ThreadId:" + Thread.CurrentThread.ManagedThreadId + " Execute Time:" + DateTime.Now);
}
![U55C4LS4`0SY0O)}[5W]{%C](https://images0.cnblogs.com/blog/15700/201303/01161524-ad9e51265ceb4b8781d6798d5ace15d0.jpg)
虽然还是1秒钟处理一个数据,但是处理数据的线程会有不同。
如果你想异步处理多个消息的话,ActionBlock也提供了一些接口,让你轻松实现。在ActionBlock的构造函数中,可以提供一个ExecutionDataflowBlockOptions的类型,让你定义ActionBlock的执行选项,在下面了例子中,我们定义了MaxDegreeOfParallelism选项,设置为3。目的的让ActionBlock中的Item最多可以3个并行处理。
public ActionBlock<int> abAsync = new ActionBlock<int>((i) =>
{
Thread.Sleep(1000);
Console.WriteLine(i + " ThreadId:" + Thread.CurrentThread.ManagedThreadId + " Execute Time:" + DateTime.Now);
}
, new ExecutionDataflowBlockOptions() { MaxDegreeOfParallelism = 3 });
public void TestAsync()
{
for (int i = 0; i < 10; i++)
{
abAsync.Post(i);
}
Console.WriteLine("Post finished");
}
![XVGW}JJK7YY7(%E}])11J7V](https://images0.cnblogs.com/blog/15700/201303/01161529-f4224d307b054026b90872b43764f7e4.jpg)
运行程序,我们看见,每3个数据几乎同时处理,并且他们的线程ID也是不一样的。
ActionBlock也有自己的生命周期,所有继承IDataflowBlock的类型都有Completion属性和Complete方法。调用Complete方法是让ActionBlock停止接收数据,而Completion属性则是一个Task,是在ActionBlock处理完所有数据时候会执行的任务,我们可以使用Completion.Wait()方法来等待ActionBlock完成所有的任务,Completion属性只有在设置了Complete方法后才会有效。
public void TestAsync()
{
for (int i = 0; i < 10; i++)
{
abAsync.Post(i);
}
abAsync.Complete();
Console.WriteLine("Post finished");
abAsync.Completion.Wait();
Console.WriteLine("Process finished");
}

TransformBlock
TransformBlock是TDF提供的另一种Block,顾名思义它常常在数据流中充当数据转换处理的功能。在TransformBlock内部维护了2个Queue,一个InputQueue,一个OutputQueue。InputQueue存储输入的数据,而通过Transform处理以后的数据则放在OutputQueue,OutputQueue就好像是一个BufferBlock。最终我们可以通过Receive方法来阻塞的一个一个获取OutputQueue中的数据。TransformBlock的Completion.Wait()方法只有在OutputQueue中的数据为0的时候才会返回。

举个例子,我们有一组网址的URL,我们需要对每个URL下载它的HTML数据并存储。那我们通过如下的代码来完成:
public TransformBlock<string, string> tbUrl = new TransformBlock<string, string>((url) =>
{
WebClient webClient = new WebClient();
return webClient.DownloadString(new Uri(url));
}
public void TestDownloadHTML()
{
tbUrl.Post("www.baidu.com");
tbUrl.Post("www.sina.com.cn");
string baiduHTML = tbUrl.Receive();
string sinaHTML = tbUrl.Receive();
}
当然,Post操作和Receive操作可以在不同的线程中进行,Receive操作同样也是阻塞操作,在OutputQueue中有可用的数据时,才会返回。
TransformManyBlock
TransformManyBlock和TransformBlock非常类似,关键的不同点是,TransformBlock对应于一个输入数据只有一个输出数据,而TransformManyBlock可以有多个,及可以从InputQueue中取一个数据出来,然后放多个数据放入到OutputQueue中。

TransformManyBlock<int, int> tmb = new TransformManyBlock<int, int>((i) => { return new int[] { i, i + 1 }; });
ActionBlock<int> ab = new ActionBlock<int>((i) => Console.WriteLine(i));
public void TestSync()
{
tmb.LinkTo(ab);
for (int i = 0; i < 4; i++)
{
tmb.Post(i);
}
Console.WriteLine("Finished post");
}
![GC(K]J4DB4UKP$S@8C9ZVMV](https://images0.cnblogs.com/blog/15700/201303/01161541-668da8d8c6dd427099f49a588f10881a.jpg)
BroadcastBlock
BroadcastBlock的作用不像BufferBlock,它是使命是让所有和它相联的目标Block都收到数据的副本,这点从它的命名上面就可以看出来了。还有一点不同的是,BroadcastBlock并不保存数据,在每一个数据被发送到所有接收者以后,这条数据就会被后面最新的一条数据所覆盖。如没有目标Block和BroadcastBlock相连的话,数据将被丢弃。但BroadcastBlock总会保存最后一个数据,不管这个数据是不是被发出去过,如果有一个新的目标Block连上来,那么这个Block将收到这个最后一个数据。

BroadcastBlock<int> bb = new BroadcastBlock<int>((i) => { return i; });
ActionBlock<int> displayBlock = new ActionBlock<int>((i) => Console.WriteLine("Displayed " + i));
ActionBlock<int> saveBlock = new ActionBlock<int>((i) => Console.WriteLine("Saved " + i));
ActionBlock<int> sendBlock = new ActionBlock<int>((i) => Console.WriteLine("Sent " + i));
public void TestSync()
{
bb.LinkTo(displayBlock);
bb.LinkTo(saveBlock);
bb.LinkTo(sendBlock);
for (int i = 0; i < 4; i++)
{
bb.Post(i);
}
Console.WriteLine("Post finished");
}
![A][PVWN1@4UMGZ[YTEV$[E9](https://images0.cnblogs.com/blog/15700/201303/01161544-e0ab399e540b47ed8b0de0f0b05e0a44.jpg)
如果我们在Post以后再添加连接Block的话,那些Block就只会收到最后一个数据了。
public void TestSync()
{
for (int i = 0; i < 4; i++)
{
bb.Post(i);
}
Thread.Sleep(5000);
bb.LinkTo(displayBlock);
bb.LinkTo(saveBlock);
bb.LinkTo(sendBlock);
Console.WriteLine("Post finished");
}

WriteOnceBlock
如果说BufferBlock是最基本的Block,那么WriteOnceBock则是最最简单的Block。它最多只能存储一个数据,一旦这个数据被发送出去以后,这个数据还是会留在Block中,但不会被删除或被新来的数据替换,同样所有的接收者都会收到这个数据的备份。
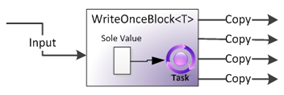
和BroadcastBlock同样的代码,但是结果不一样:
WriteOnceBlock<int> bb = new WriteOnceBlock<int>((i) => { return i; });
ActionBlock<int> displayBlock = new ActionBlock<int>((i) => Console.WriteLine("Displayed " + i));
ActionBlock<int> saveBlock = new ActionBlock<int>((i) => Console.WriteLine("Saved " + i));
ActionBlock<int> sendBlock = new ActionBlock<int>((i) => Console.WriteLine("Sent " + i));
public void TestSync()
{
bb.LinkTo(displayBlock);
bb.LinkTo(saveBlock);
bb.LinkTo(sendBlock);
for (int i = 0; i < 4; i++)
{
bb.Post(i);
}
Console.WriteLine("Post finished");
}

WriteOnceBock只会接收一次数据。而且始终保留那个数据。
同样使用Receive方法来获取数据也是一样的结果,获取到的都是第一个数据:
public void TestReceive()
{
for (int i = 0; i < 4; i++)
{
bb.Post(i);
}
Console.WriteLine("Post finished");
Console.WriteLine("1st Receive:" + bb.Receive());
Console.WriteLine("2nd Receive:" + bb.Receive());
Console.WriteLine("3rd Receive:" + bb.Receive());
}
![7M5Q]MH5K82OVQ}N]E(J8MV](https://images0.cnblogs.com/blog/15700/201303/01161559-81cd4699ae8d42a0974b9b93c67ad47b.jpg)
BatchBlock

BatchBlock提供了能够把多个单个的数据组合起来处理的功能,如上图。应对有些需求需要固定多个数据才能处理的问题。在构造函数中需要制定多少个为一个Batch,一旦它收到了那个数量的数据后,会打包放在它的OutputQueue中。当BatchBlock被调用Complete告知Post数据结束的时候,会把InputQueue中余下的数据打包放入OutputQueue中等待处理,而不管InputQueue中的数据量是不是满足构造函数的数量。
BatchBlock<int> bb = new BatchBlock<int>(3);
ActionBlock<int[]> ab = new ActionBlock<int[]>((i) =>
{
string s = string.Empty;
foreach (int m in i)
{
s += m + " ";
}
Console.WriteLine(s);
});
public void TestSync()
{
bb.LinkTo(ab);
for (int i = 0; i < 10; i++)
{
bb.Post(i);
}
bb.Complete();
Console.WriteLine("Finished post");
}

BatchBlock执行数据有两种模式:贪婪模式和非贪婪模式。贪婪模式是默认的。贪婪模式是指任何Post到BatchBlock,BatchBlock都接收,并等待个数满了以后处理。非贪婪模式是指BatchBlock需要等到构造函数中设置的BatchSize个数的Source都向BatchBlock发数据,Post数据的时候才会处理。不然都会留在Source的Queue中。也就是说BatchBlock可以使用在每次从N个Source那个收一个数据打包处理或从1个Source那里收N个数据打包处理。这里的Source是指其他的继承ISourceBlock的,用LinkTo连接到这个BatchBlock的Block。
在另一个构造参数中GroupingDataflowBlockOptions,可以通过设置Greedy属性来选择是否贪婪模式和MaxNumberOfGroups来设置最大产生Batch的数量,如果到达了这个数量,BatchBlock将不会再接收数据。
JoinBlock

JoinBlock一看名字就知道是需要和两个或两个以上的Source Block相连接的。它的作用就是等待一个数据组合,这个组合需要的数据都到达了,它才会处理数据,并把这个组合作为一个Tuple传递给目标Block。举个例子,如果定义了JoinBlock<int, string>类型,那么JoinBlock内部会有两个ITargetBlock,一个接收int类型的数据,一个接收string类型的数据。那只有当两个ITargetBlock都收到各自的数据后,才会放到JoinBlock的OutputQueue中,输出。
JoinBlock<int, string> jb = new JoinBlock<int, string>();
ActionBlock<Tuple<int, string>> ab = new ActionBlock<Tuple<int, string>>((i) =>
{
Console.WriteLine(i.Item1 + " " + i.Item2);
});
public void TestSync()
{
jb.LinkTo(ab);
for (int i = 0; i < 5; i++)
{
jb.Target1.Post(i);
}
for (int i = 5; i > 0; i--)
{
Thread.Sleep(1000);
jb.Target2.Post(i.ToString());
}
Console.WriteLine("Finished post");
}

BatchedJoinBlock

BatchedJoinBlock一看就是BacthBlock和JoinBlick的组合。JoinBlick是组合目标队列的一个数据,而BatchedJoinBlock是组合目标队列的N个数据,当然这个N可以在构造函数中配置。如果我们定义的是BatchedJoinBlock<int, string>, 那么在最后的OutputQueue中存储的是Tuple<IList<int>, IList<string>>,也就是说最后得到的数据是Tuple<IList<int>, IList<string>>。它的行为是这样的,还是假设上文的定义,BatchedJoinBlock<int, string>, 构造BatchSize输入为3。那么在这个BatchedJoinBlock种会有两个ITargetBlock,会接收Post的数据。那什么时候会生成一个Tuple<IList<int>,IList<string>>到OutputQueue中呢,测试下来并不是我们想的需要有3个int数据和3个string数据,而是只要2个ITargetBlock中的数据个数加起来等于3就可以了。3和0,2和1,1和2或0和3的组合都会生成Tuple<IList<int>,IList<string>>到OutputQueue中。可以参看下面的例子:
BatchedJoinBlock<int, string> bjb = new BatchedJoinBlock<int, string>(3);
ActionBlock<Tuple<IList<int>, IList<string>>> ab = new ActionBlock<Tuple<IList<int>, IList<string>>>((i) =>
{
Console.WriteLine("-----------------------------");
foreach (int m in i.Item1)
{
Console.WriteLine(m);
};
foreach (string s in i.Item2)
{
Console.WriteLine(s);
};
});
public void TestSync()
{
bjb.LinkTo(ab);
for (int i = 0; i < 5; i++)
{
bjb.Target1.Post(i);
}
for (int i = 5; i > 0; i--)
{
bjb.Target2.Post(i.ToString());
}
Console.WriteLine("Finished post");
}
![GZ}X_[]DM}42_()PXL05A(T](https://images0.cnblogs.com/blog/15700/201303/01161627-810333a4e46f4b169db29bf44de8ccc4.jpg)
最后剩下的一个数据1,由于没有满3个,所以一直被保留在Target2中。
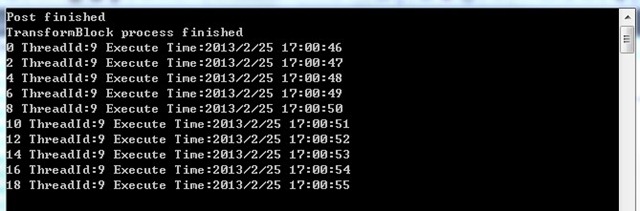
TDF中最有用的功能之一就是多个Block之间可以组合应用。ISourceBlock可以连接ITargetBlock,一对一,一对多,或多对多。下面的例子就是一个TransformBlock和一个ActionBlock的组合。TransformBlock用来把数据*2,并转换成字符串,然后把数据扔到ActionBlock中,而ActionBlock则用来最后的处理数据打印结果。
public ActionBlock<string> abSync = new ActionBlock<string>((i) =>
{
Thread.Sleep(1000);
Console.WriteLine(i + " ThreadId:" + Thread.CurrentThread.ManagedThreadId + " Execute Time:" + DateTime.Now);
}
);
public TransformBlock<int, string> tbSync = new TransformBlock<int, string>((i) =>
{
i = i * 2;
return i.ToString();
}
);
public void TestSync()
{
tbSync.LinkTo(abSync);
for (int i = 0; i < 10; i++)
{
tbSync.Post(i);
}
tbSync.Complete();
Console.WriteLine("Post finished");
tbSync.Completion.Wait();
Console.WriteLine("TransformBlock process finished");
}
TDF提供的一些Block,通过对这些Block配置和组合,可以满足很多的数据处理的场景。这一篇将继续介绍与这些Block配置的相关类,和挖掘一些高级功能。
在一些Block的构造函数中,我们常常可以看见需要你输入DataflowBlockOptions 类型或者它的两个派生类型ExecutionDataflowBlockOptions 和 GroupingDataflowBlockOptions。
DataflowBlockOptions
DataflowBlockOptions有五个属性:BoundedCapacity,CancellationToken,MaxMessagesPerTask,NameFormat和TaskScheduler。
用BoundedCapacity来限定容量
这个属性用来限制一个Block中最多可以缓存数据项的数量,大多数Block都支持这个属性,这个值默认是DataflowBlockOptions.Unbounded = -1,也就是说没有限制。开发人员可以制定这个属性设置数量的上限。那后面的新数据将会延迟。比如说用一个BufferBlock连接一个ActionBlock,如果在ActionBlock上面设置了上限,ActionBlock处理的操作速度比较慢,留在ActionBlock中的数据到达了上限,那么余下的数据将留在BufferBlock中,直到ActionBlock中的数据量低于上限。这种情况常常会发生在生产者生产的速度大于消费者速度的时候,导致的问题是内存越来越大,数据操作越来越延迟。我们可以通过一个BufferBlock连接多个ActionBlock来解决这样的问题,也就是负载均衡。一个ActionBlock满了,就会放到另外一个ActionBlock中去了。
用CancellationToken来取消操作
TPL中常用的类型。在Block的构造函数中放入CancellationToken,Block将在它的整个生命周期中全程监控这个对象,只要在这个Block结束运行(调用Complete方法)前,用CancellationToken发送取消请求,该Block将会停止运行,如果Block中还有没有处理的数据,那么将不会再被处理。
用MaxMessagesPerTask控制公平性
每一个Block内部都是异步处理,都是使用TPL的Task。TDF的设计是在保证性能的情况下,尽量使用最少的任务对象来完成数据的操作,这样效率会高一些,一个任务执行完成一个数据以后,任务对象并不会销毁,而是会保留着去处理下一个数据,直到没有数据处理的时候,Block才会回收掉这个任务对象。但是如果数据来自于多个Source,公平性就很难保证。从其他Source来的数据必须要等到早前的那些Source的数据都处理完了才能被处理。这时我们就可以通过MaxMessagesPerTask来控制。这个属性的默认值还是DataflowBlockOptions.Unbounded=-1,表示没有上限。假如这个数值被设置为1的话,那么单个任务只会处理一个数据。这样就会带来极致的公平性,但是将带来更多的任务对象消耗。
用NameFormat来定义Block名称
MSDN上说属性NameFormat用来获取或设置查询块的名称时要使用的格式字符串。
Block的名字Name=string.format(NameFormat, block.GetType ().Name, block.Completion.Id)。所以当我们输入”{0}”的时候,名字就是block.GetType ().Name,如果我们数据的是”{1}”,那么名字就是block.Completion.Id。如果是“{2}”,那么就会抛出异常。
用TaskScheduler来调度Block行为
TaskScheduler是非常重要的属性。同样这个类型来源于TPL。每个Block里面都使用TaskScheduler来调度行为,无论是源Block和目标Block之间的数据传递,还是用户自定义的执行数据方法委托,都是使用的TaskScheduler。如果没有特别设置的话,将使用TaskScheduler.Default(System.Threading.Tasks.ThreadPoolTaskScheduler)来调度。我们可以使用其他的一些继承于TaskScheduler的类型来设置这个调度器,一旦设置了以后,Block中的所有行为都会使用这个调度器来执行。.Net Framework 4中内建了两个Scheduler,一个是默认的ThreadPoolTaskScheduler,另一个是用于UI线程切换的SynchronizationContextTaskScheduler。如果你使用的Block设计到UI的话,那可以使用后者,这样在UI线程切换上面将更加方便。
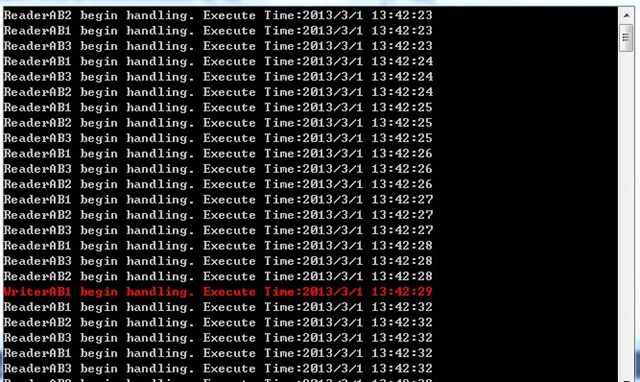
.Net Framework 4.5 中,还有一个类型被加入到System.Threading.Tasks名称空间下:ConcurrentExclusiveSchedulerPair。这个类是两个TaskScheduler的组合。它提供两个TaskScheduler:ConcurrentScheduler和ExclusiveScheduler;我们可以把这两个TaskScheduler构造进要使用的Block中。他们保证了在没有排他任务的时候(使用ExclusiveScheduler的任务),其他任务(使用ConcurrentScheduler)可以同步进行,当有排他任务在运行的时候,其他任务都不能运行。其实它里面就是一个读写锁。这在多个Block操作共享资源的问题上是一个很方便的解决方案。
public ActionBlock<int> readerAB1;
public ActionBlock<int> readerAB2;
public ActionBlock<int> readerAB3;
public ActionBlock<int> writerAB1;
public BroadcastBlock<int> bb = new BroadcastBlock<int>((i) => { return i; });
public void Test()
{
ConcurrentExclusiveSchedulerPair pair = new ConcurrentExclusiveSchedulerPair();
readerAB1 = new ActionBlock<int>((i) =>
{
Console.WriteLine("ReaderAB1 begin handling." + " Execute Time:" + DateTime.Now);
Thread.Sleep(500);
}
, new ExecutionDataflowBlockOptions() { TaskScheduler = pair.ConcurrentScheduler });
readerAB2 = new ActionBlock<int>((i) =>
{
Console.WriteLine("ReaderAB2 begin handling." + " Execute Time:" + DateTime.Now);
Thread.Sleep(500);
}
, new ExecutionDataflowBlockOptions() { TaskScheduler = pair.ConcurrentScheduler });
readerAB3 = new ActionBlock<int>((i) =>
{
Console.WriteLine("ReaderAB3 begin handling." + " Execute Time:" + DateTime.Now);
Thread.Sleep(500);
}
, new ExecutionDataflowBlockOptions() { TaskScheduler = pair.ConcurrentScheduler });
writerAB1 = new ActionBlock<int>((i) =>
{
Console.ForegroundColor = ConsoleColor.Red;
Console.WriteLine("WriterAB1 begin handling." + " Execute Time:" + DateTime.Now);
Console.ResetColor();
Thread.Sleep(3000);
}
, new ExecutionDataflowBlockOptions() { TaskScheduler = pair.ExclusiveScheduler });
bb.LinkTo(readerAB1);
bb.LinkTo(readerAB2);
bb.LinkTo(readerAB3);
Task.Run(() =>
{
while (true)
{
bb.Post(1);
Thread.Sleep(1000);
}
});
Task.Run(() =>
{
while (true)
{
Thread.Sleep(6000);
writerAB1.Post(1);
}
});
}
用MaxDegreeOfParallelism来并行处理
通常,Block中处理数据都是单线程的,一次只能处理一个数据,比如说ActionBlock中自定义的代理。使用MaxDegreeOfParallelism可以让你并行处理这些数据。属性的定义是最大的并行处理个数。如果定义成-1的话,那就是没有限制。用户需要在实际情况中选择这个值的大小,并不是越大越好。如果是平行处理的话,还应该考虑是否有共享资源。
TDF中的负载均衡
我们可以使用Block很方便的构成一个生产者消费者的模式来处理数据。当生产者产生数据的速度快于消费者的时候,消费者Block的Buffer中的数据会越来越多,消耗大量的内存,数据处理也会延时。这时,我们可以用一个生产者Block连接多个消费者Block来解决这个问题。由于多个消费者Block一定是并行处理,所以对共享资源的处理一定要做同步处理。
使用BoundedCapacity属性来实现
当连接多个ActionBlock的时候,可以通过设置ActionBlock的BoundedCapacity属性。当第一个满了,就会放到第二个,第二个满了就会放到第三个。
public BufferBlock<int> bb = new BufferBlock<int>();
public ActionBlock<int> ab1 = new ActionBlock<int>((i) =>
{
Thread.Sleep(1000);
Console.WriteLine("ab1 handle data" + i + " Execute Time:" + DateTime.Now);
}
, new ExecutionDataflowBlockOptions() { BoundedCapacity = 2 });
public ActionBlock<int> ab2 = new ActionBlock<int>((i) =>
{
Thread.Sleep(1000);
Console.WriteLine("ab2 handle data" + i + " Execute Time:" + DateTime.Now);
}
, new ExecutionDataflowBlockOptions() { BoundedCapacity = 2 });
public ActionBlock<int> ab3 = new ActionBlock<int>((i) =>
{
Thread.Sleep(1000);
Console.WriteLine("ab3 handle data:" + i + " Execute Time:" + DateTime.Now);
}
, new ExecutionDataflowBlockOptions() { BoundedCapacity = 2 });
public void Test()
{
bb.LinkTo(ab1);
bb.LinkTo(ab2);
bb.LinkTo(ab3);
for (int i = 0; i < 9; i++)
{
bb.Post(i);
}
}
![PNQFKIK2OK)}SOWA]RF(~$M](https://images0.cnblogs.com/blog/15700/201303/01161459-0b53a87052b845fd91f9b3e7d922e20b.jpg)
感谢您的阅读,如果您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是yswenli 。