Tensorflow目标检测之yolov3训练自己的模型
原创ZONG_XP 发布于2019-11-26 16:19:18 阅读数 155 收藏
0 背景
Tensorflow官方目标检测给出了SSD、Faster rcnn等预训练模型,但没有给yolov3的预训练模型,但有热心的人已经实现了基于tensorflow来复现yolov3的算法,本文对该代码的训练测试流程做一介绍。
代码起源于YunYang1994的tensorflow-yolov3,后续类似的代码都是基于他进行的修改。我们今天介绍的Byronnar实现的tensorflow-serving-yolov3就是一种改进,相关改进作者这样介绍,本文就是基于后边的代码进行实现。
主要对原tensorflow-yolov3版本做了许多细节上的改进,训练了Visdrone2019数据集,准确率在87%左右, 如果觉得好用记得star一下哦,谢谢! 步骤十分详细,特别适合新手入门serving端部署,有什么问题可以提issues,下面是改进细节:
1 修改了网络结构,支持了tensorflow-serving部署,自己训练的数据集也可以在线部署,并给出了 docker+yolov3-api测试脚本
2 修改了ulits文件,优化了demo展示,可以支持中文展示,添加了字体
3 详细的中文注释,代码更加易读,添加了数据敏感性处理,一定程度避免index的错误
4 修改了训练代码,支持其他数据集使用预训练模型了,模型体积减小二分之一(如果不用指数平滑,可以减小到200多M一个模型,减小三分之二),图片视频demo展示 完都支持保存到本地,十分容易操作
5 借鉴视频检测的原理,添加了批量图片测试脚本,速度特别快(跟处理视频每一帧一样的速度)
6 添加了易使用的Anchors生成脚本以及各步操作完整的操作流程
1 demo测试
1.1 下载及安装
$ git clone https://github.com/byronnar/tensorflow-serving-yolov3.git
$ cd tensorflow-serving-yolov3
$ pip install -r requirements.txt从requirement文件中可以看出代码是基于tensorflow-gpu 1.11.0,如果你的版本与作者的不一致,可能会出现问题,不确定,可以试试
1.2 下载预训练模型
百度网盘链接: https://pan.baidu.com/s/1Il1ASJq0MN59GRXlgJGAIw 密码:vw9x
谷歌云盘链接: https://drive.google.com/open?id=1aVnosAJmZYn1QPGL0iJ7Dnd4PTAukSU4
$ cd checkpoint
$ tar -xvf yolov3_coco.tar.gz
$ cd ..
$ python convert_weight.py
$ python freeze_graph.py1.3 运行demo
$ python image_demo_Chinese.py # 中文显示
$ python image_demo.py # 英文显示
$ python video_demo.py # if use camera, set video_path = 0
运行成功后会显示结果图片

1.4 服务部署
-
# 转化成可部署的 saved model格式 -
$ python save_model.py -
# 将产生的saved model文件夹里面的 yolov3 文件夹复制到 tmp 文件夹下面,再运行 -
$ docker run -p 8501:8501 --mount type=bind,source=/tmp/yolov3/,target=/models/yolov3 -e MODEL_NAME=yolov3 -t tensorflow/serving & -
$ cd serving-yolov3 -
$ python yolov3_api.py
调用成功后显示如下画面
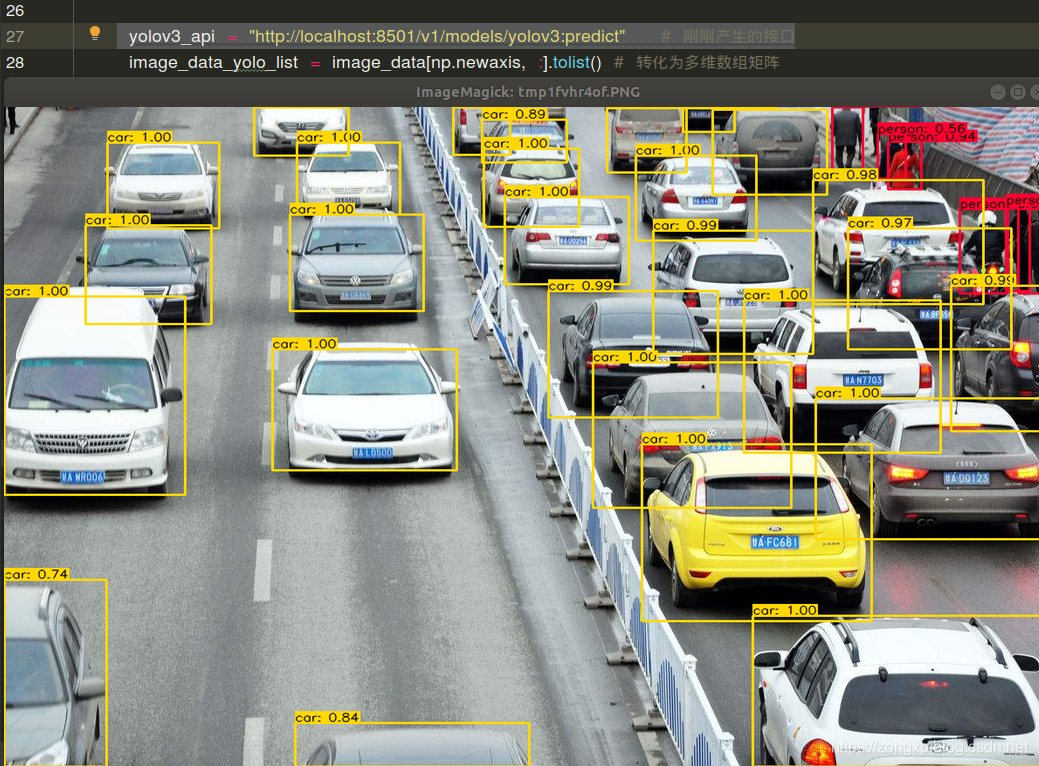
2 训练自己的数据
经过以上步骤,我们把环境都配置好了,接下来开始训练自己的数据
2.1 数据集准备
需要准备VOC格式的数据集,VOC2007的目录结构如下
-
VOC2007 -
├── Annotations -
├── ImageSets -
│ └── Main -
└── JPEGImages
把我们标注的xml文件放到Annotations文件夹下,图片放到JPEGImages文件夹下,然后在VOC2007文件夹下新建一个脚本,用来生成ImageSets文件夹下的数据集结构,如下所示
-
import os -
import random -
trainval_percent = 0.1 -
train_percent = 0.9 -
xmlfilepath = 'Annotations' -
txtsavepath = 'ImageSets/Main' -
# 历遍"Annotations"文件夹然后返回列表 -
total_xml = os.listdir(xmlfilepath) -
# 获取列表的总数 -
num = len(total_xml) -
list = range(num) -
tv = int(num * trainval_percent) -
tr = int(tv * train_percent) -
trainval = random.sample(list, tv) -
train = random.sample(trainval, tr) -
ftrainval = open('ImageSets/Main/trainval.txt', 'w') -
ftest = open('ImageSets/Main/test.txt', 'w') -
ftrain = open('ImageSets/Main/train.txt', 'w') -
fval = open('ImageSets/Main/val.txt', 'w') -
for i in list: -
# 使用切片方法获取文件名(去掉后缀".xml") -
name = total_xml[i][:-4] + ' ' -
if i in trainval: -
ftrainval.write(name) -
if i in train: -
ftest.write(name) -
else: -
fval.write(name) -
else: -
ftrain.write(name) -
ftrainval.close() -
ftrain.close() -
fval.close() -
ftest.close()
运行成功后,会在Main文件夹下生成test rain rainvalval四个文件,至此数据集准备完成
2.2 修改类别名
在data/classes目录下保存了类别名文件,我们修改vis.names的内容,将自己的类别写入保存
在其它地方有用到coco.names文件,所以为了防止出错,我们将这个文件夹下每个names文件都修改为自己的类别,省去其它地方修改
2.3 修改anchors
通过聚类算法,产生我们数据集的anchors,直接运行anchors_generate.py文件,会输出9对坐标值,如下
-
$ python anchors_generate.py -
anchors are: -
45,45, 96,70, 80,112, 157,108, 118,172, 230,154, 169,246, 330,241, 279,358 -
the average iou is: -
0.7574684115499671
将anchors值写入data/anchors/basline_anchors文件中
2.4 生成训练文件
运行split.py文件,会生成2007_test.txt 2007_train.txt 2007_val.txt三个文件,实际训练时从这三个文件中读取数据,文本中的数据格式如下
-
image_path x_min, y_min, x_max, y_max, class_id x_min, y_min ,..., class_id x_min, y_min -
# 例如 -
xxx/xxx.jpg 18.19,6.32,424.13,421.83,20 323.86,2.65,640.0,421.94,20 -
xxx/xxx.jpg 48,240,195,371,11 8,12,352,498,14
2.5 修改配置文件
修改core/config.py文件,主要根据自己显存情况设置BATCH_SIZE值,建议不要太大,否则后续会报内存错误
2.6 开始训练
经过上述步骤,就完成了数据和配置文件的准备,接下来就可以开始训练了,直接运行train.py文件就行
-
$ python train.py -
2019-11-26 15:36:24.311910: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA -
2019-11-26 15:36:24.981981: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1411] Found device 0 with properties: -
name: TITAN V major: 7 minor: 0 memoryClockRate(GHz): 1.455 -
pciBusID: 0000:04:00.0 -
totalMemory: 11.78GiB freeMemory: 10.81GiB -
2019-11-26 15:36:24.982042: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1490] Adding visible gpu devices: 0 -
2019-11-26 15:36:25.509204: I tensorflow/core/common_runtime/gpu/gpu_device.cc:971] Device interconnect StreamExecutor with strength 1 edge matrix: -
2019-11-26 15:36:25.509273: I tensorflow/core/common_runtime/gpu/gpu_device.cc:977] 0 -
2019-11-26 15:36:25.509286: I tensorflow/core/common_runtime/gpu/gpu_device.cc:990] 0: N -
2019-11-26 15:36:25.509692: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1103] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 10435 MB memory) -> physical GPU (device: 0, name: TITAN V, pci bus id: 0000:04:00.0, compute capability: 7.0) -
=> Restoring weights from: ./checkpoint/yolov3_coco_demo.ckpt ... -
train loss: 67.78: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1427/1427 [05:24<00:00, 4.40it/s] -
=> Epoch: 1 Time: 2019-11-26 15:43:56 Train loss: 786.53 Test loss: 93.00 Saving ./checkpoint/yolov3_train_loss=786.5312.ckpt ... -
train loss: 20.86: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1427/1427 [04:58<00:00, 4.79it/s] -
=> Epoch: 2 Time: 2019-11-26 15:49:39 Train loss: 39.11 Test loss: 22.08 Saving ./checkpoint/yolov3_train_loss=39.1093.ckpt ... -
train loss: 20.92: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1427/1427 [04:55<00:00, 4.83it/s] -
=> Epoch: 3 Time: 2019-11-26 15:55:22 Train loss: 16.35 Test loss: 14.92 Saving ./checkpoint/yolov3_train_loss=16.3459.ckpt ... -
train loss: 16.56: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1427/1427 [04:52<00:00, 4.88it/s] -
=> Epoch: 4 Time: 2019-11-26 16:01:02 Train loss: 13.07 Test loss: 13.02 Saving ./checkpoint/yolov3_train_loss=13.0722.ckpt ... -
train loss: 6.54: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1427/1427 [04:52<00:00, 4.89it/s] -
=> Epoch: 5 Time: 2019-11-26 16:06:40 Train loss: 11.71 Test loss: 11.79 Saving ./checkpoint/yolov3_train_loss=11.7074.ckpt ...
运行时会保存最新的权重文件
3 模型验证
经过上边的训练,会在checkpoint文件夹下生成训练文件,训练时我们可以对每个模型进行验证,求mAP值,从而获得最优模型,需要注意的是在config文件中作者设置了两个阶段训练
-
__C.TRAIN.FISRT_STAGE_EPOCHS = 20 -
__C.TRAIN.SECOND_STAGE_EPOCHS = 30
在第一个阶段的时候没必要验证,因为结果会很差,基本全为0;等到了第二阶段的时候再做验证,mAP会逐渐提升。但是如何有效应对过拟合,还没有一个好的解决方法(我能想到的一个解决办法就是观察Train loss和Test loss的变化情况,当两个都在下降时表明还欠拟合,当train loss下降而test loss上升时,表明有过拟合的倾向了,可以提前终止训练)
首先修改config.py文件中TEST部分,主要是将__C.TEST.WEIGHT_FILE的值改为checkpoint中模型文件即可,然后运行以下脚本
-
$ python evaluate.py -
$ cd mAP -
$ python main.py -na
运行后再results文件夹下会生成结果图片,如下:
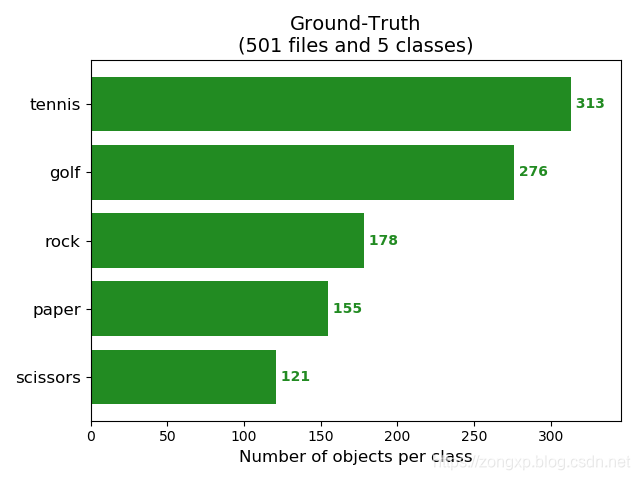
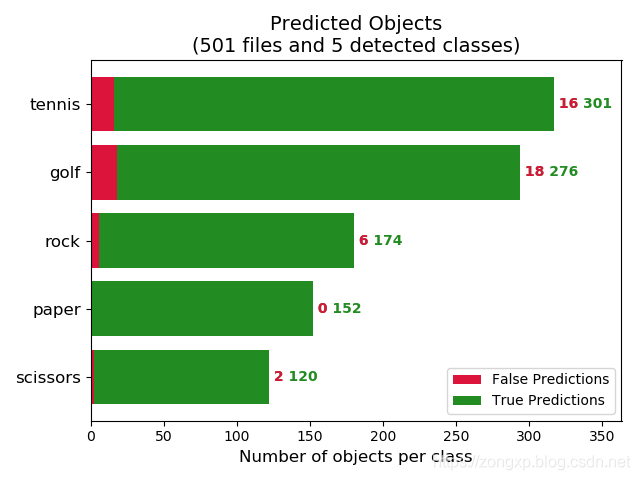
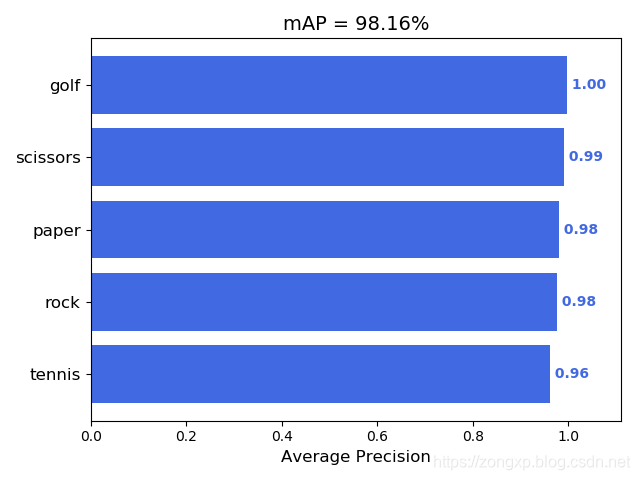
同时,在data/detection文件夹下保存了检测结果图片
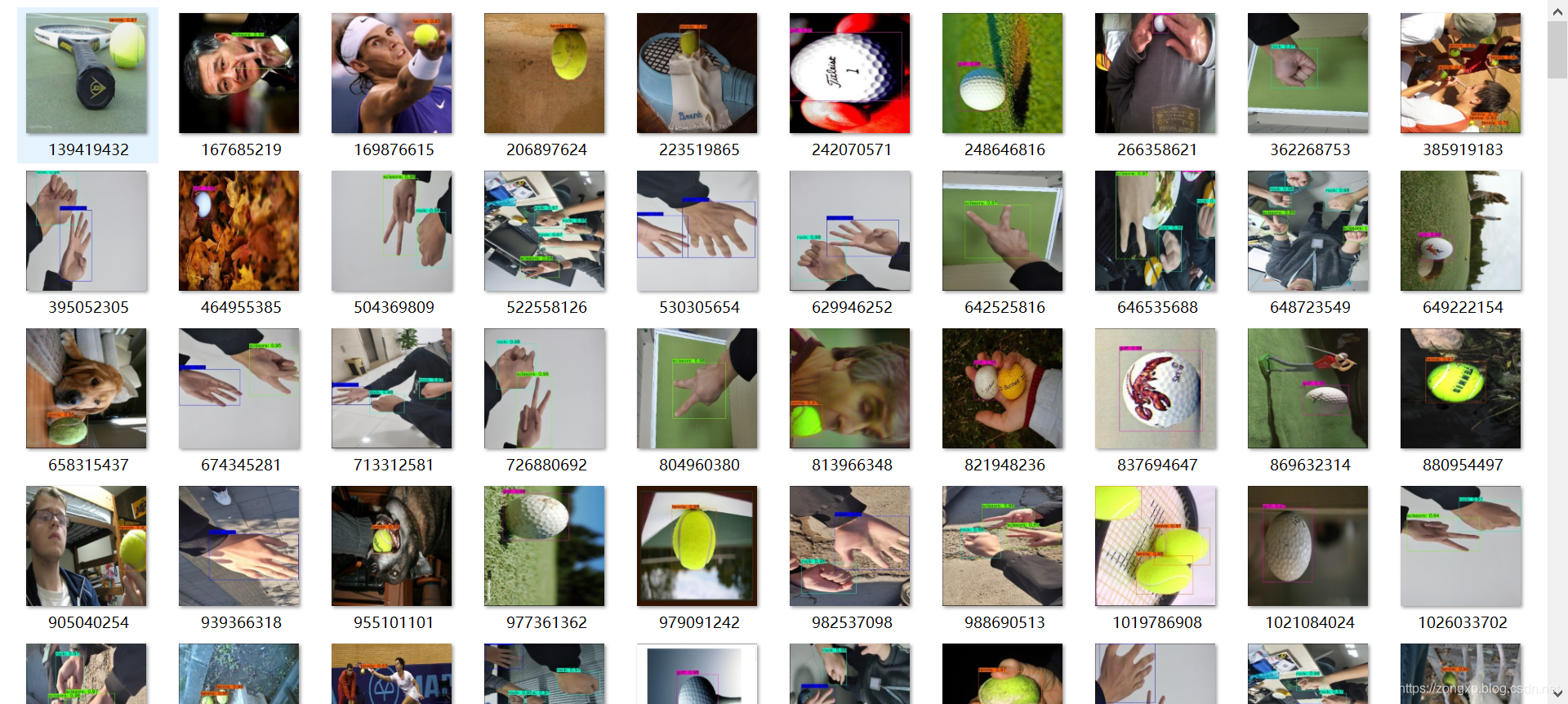
至此完成了模型的训练及测试过程。
4 模型导出
上述步骤训练得到了checkpoint文件,我们在部署时一般会使用pb文件,所以接下来将checkpoint文件转化成pb文件,转化方法很简单,只需要修改freeze_graph.py文件中的pb_file(输出路径)和ckpt_file(输入路径)即可,然后运行该脚本,即可生成。
项目中作者给出了图片测试脚本image_demo.py和视频测试脚本video_demo.py,将pb_file路径改为刚才生成的文件,然后修改num_classes为自己的实际类别数,即可完成测试。
如果是要用tensorflow serving调用模型,则运行save_model.py即可生成服务格式的模型文件,然后按照tensorflow serving的方式进行部署即可,不清楚的可以参考我tensorflow serving系列文章。