YoLo 实践(1)
by lizhen
参考代码:
keras-yolo3 ***
所需环境:
python3 | annconda
keras
tensorflow
configparser
目标:
使用Keras| tensorflow完成基于Yolo的车辆检测的训练;
实施方法:
(1). Yolo是目前使用比较广泛的模型之一, 在github等开源网站中有很多实现方式, 自己找一个比较靠谱的程序,对其改进. 改进方式有以下几点: (a) 训练给予VOC的模型(复现Yolov3) ; (b) 根据论文去阅读yolo
(2). 改进训练方法, 适用雨车辆检测
Step 0. 测试项目是否可以正常运行
wget https://pjreddie.com/media/files/yolov3.weights # 下载yolo的模型
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5 # 将yolo的模型转化成适合Kears加载的格式
python yolo_video.py --image # 指定使用图片检测
运行效果图
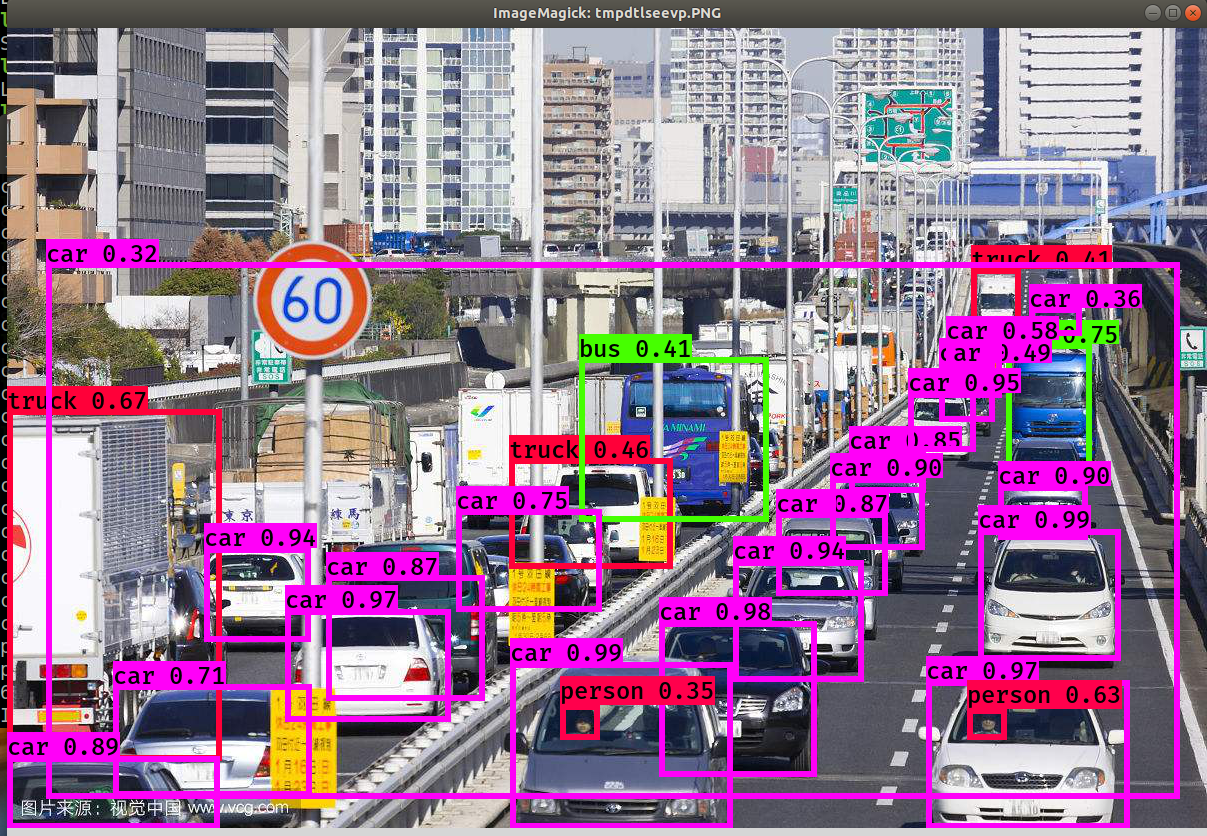
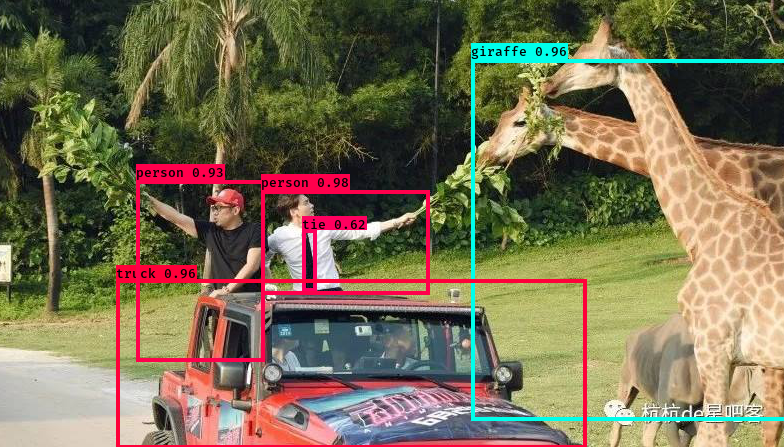
使用VOC数据结构训练模型
Step1: 生成统一格式的标注文件和类别文件
为了方便训练, 针对每一个图片都有一种格式的标注文件:
这两种格式的文件是:
Row format: image_file_path box1 box2 ... boxN
Box 的格式 : x_min,y_min,x_max,y_max,class_id
对于VOC数据集,由于已经有了xml格式的标注文件, 仅需要转换标注的格式即可, 在此提供voc_annotation.py
vim voc_annotation.py # 修改有关VOC2007数据的路径
python voc_annotation.py # 运行有关
通过阅读voc_annotation.py文件, 可以得知:
该脚本可以将VOC2007 中标注修改成上述格式的文本;
转换的过程需要修改VOC数据集的路径;
转换后,会待当前目录(getcwd())创建有关训练和校验的标注文件:
~/workspace/keras-yolo3$ ll
-rw-rw-r-- 1 lizhen lizhen 297885 Oct 23 15:48 2007_train.txt # 产生的新文件
-rw-rw-r-- 1 lizhen lizhen 298595 Oct 23 15:48 2007_val.txt
文件的格式如下:
/keras-yolo3/VOCdevkit/VOC2007/JPEGImages/000064.jpg 1,23,451,500,2
keras-yolo3/VOCdevkit/VOC2007/JPEGImages/000066.jpg 209,187,228,230,14 242,182,274,259,14 269,188,2
95,259,14
keras-yolo3/VOCdevkit/VOC2007/JPEGImages/000073.jpg 121,143,375,460,15 2,154,64,459,15 270,155,375,
331,3 22,143,146,500,14
Step2: 加载预训练模型
为了加快训练的速度和Auc, 可以在已有的模型上进行训练,
在后期的训练中,会冻结yolo模型的前249层, 主要训练后面的高维度的特征
Freeze the first 249 layers of total 252 layers.
cd /home/lizhen/workspace/keras-yolo3 # 切换到工作目录
python convert.py -w yolov3.cfg yolov3.weights model_data/yolo_weights.h5 # 将适用于darknet的模型转换成Keras
....
__________________________________________________________________________________________________
conv2d_67 (Conv2D) (None, None, None, 2 130815 leaky_re_lu_65[0][0]
__________________________________________________________________________________________________
conv2d_75 (Conv2D) (None, None, None, 2 65535 leaky_re_lu_72[0][0]
==================================================================================================
Total params: 62,001,757
Trainable params: 61,949,149
Non-trainable params: 52,608
__________________________________________________________________________________________________
None
Saved Keras model to model_data/yolo.h5
Read 62001757 of 62001757.0 from Darknet weights.
Step3: 训练VOC数据
为了防止在训练过程中出现OOM异常, 根据问题1的提示, 可以将epoch和batch的数量降低;
对 train.py 的读取文件位置进行修改, 替换成上Step1中生成207_train.txt
python train.py # 读取2017_train.txt ,同时运行模型
~/workspace/keras-yolo3$ ls logs/001/
ep003-loss38.801-val_loss35.522.h5 ep009-loss26.373-val_loss27.126.h5 events.out.tfevents.1540299060.BoHong
ep003-loss39.940-val_loss36.366.h5 events.out.tfevents.1540294790.BoHong trained_weights_final.h5
ep006-loss29.750-val_loss28.700.h5 events.out.tfevents.1540296584.BoHong trained_weights_stage_1.h5
通过阅读train.py 可知, 经过训练以后会在./logs/0001下产生模型, 模型是** trained_weights_final.h5**
训练过程中的loss变化如下:
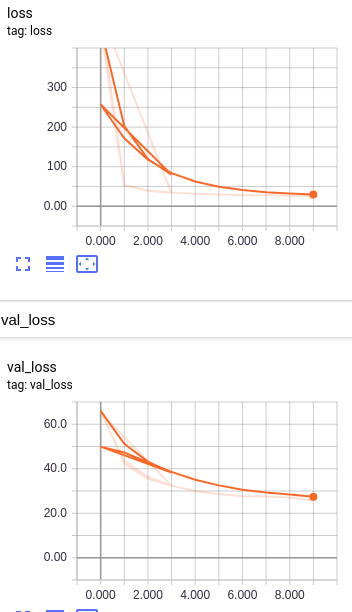
Step4: 测试模型
python yolo_video.py --model logs/0001/trained_weights_final.h5 --image
测试效果:
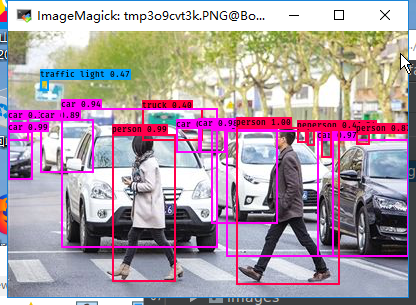
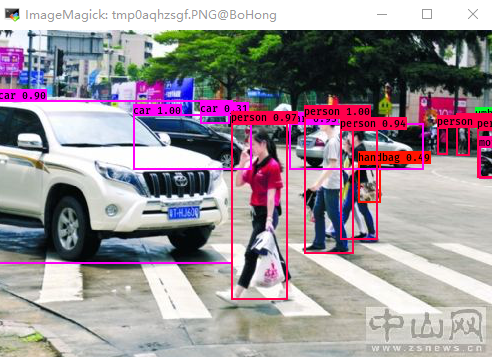
问题集合
1. Out of system memory when unfreeze all of the layers.
在训练数据的过程中(python train.py), 会因为GPU的OOM异常而提前退出训练;
根据
https://github.com/qqwweee/keras-yolo3/issues/122
中提供的信息, 可以尝试一下集中方案:
1 only train 2 classes, car and person, modify model_data/voc_classes.txt
2 batch_size = 2 & epoch = 20
3 set load_pretrained=False
4 update tensorflow to 1.8.0
附录A
ConfigParser
ConfigParser模块在python3中修改为configparser.这个模块定义了一个ConfigParser类,该类的作用是使用配置文件生效,配置文件的格式和windows的INI文件的格式相同
该模块的作用 就是使用模块中的RawConfigParser()、ConfigParser()、 SafeConfigParser()这三个方法,创建一个对象使用对象的方法对指定的配置文件做增删改查 操作。

后期准备解析yolo论文,改代码 敬请期待~