讲解: Mike Lewis
编辑:
Jiayu Qiu, Yuhong Zhu, Lyuang Fu, Ian Leefmans ,2020年4月20日
翻译:
Yibing Ran, 2020年12月30日
原文阅读
概述
- 近年来取得了惊人的进步:
- 对于某些语言,人们更喜欢机器翻译而不是人工翻译
- 在许多问答数据集上的超人性能、
- 语言模型生成流畅的段落(如Radford等,2019)
- 最每个任务所需要的最小专业技术,可以用相当通用的模型实现
语言模型
- 语言模型为文本分配概率:(p(x_0,cdots,x_n))
- 有许多可能的句子,因此我们不能仅仅训练一个分类器
- 最为流行的方法是使用链式法则对分布进行分解:
神经语言模型
我们把文本输入到神经网络,神经网络将所有上下文映射为一个向量,这个向量表示下一个单词。我们有一个大的词嵌入矩阵,该词嵌入矩阵包含模型可能输出的每个单词的向量。然后我们通过背景向量和每个单词向量的点积计算相似度。我们将得到预测下一个词的概率,然后通过最大化似然训练这个模型。这里关键的细节是我们不直接处理单词,而是处理子词或字符。
(注:原文为$p(x_0|x_{0,cdots,n-1}) $,应该是笔误)
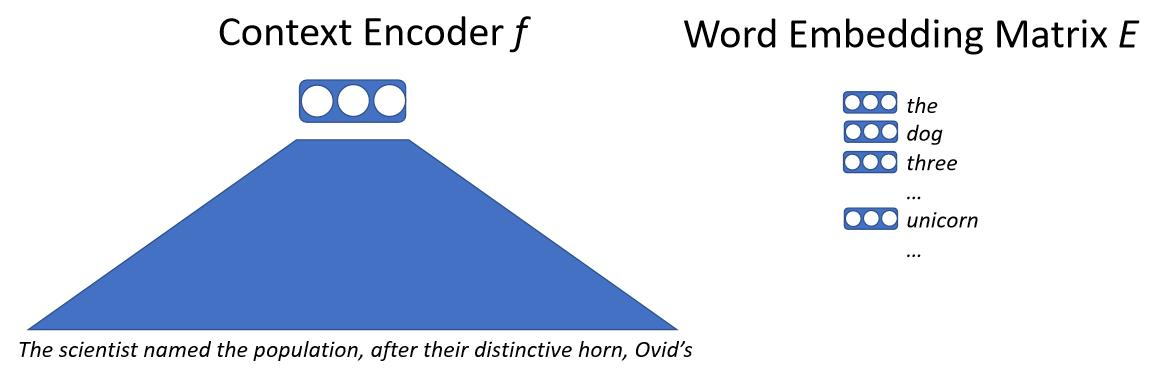
卷积语言模型
- 第一个神经网络语言模型
- 每个单词以向量形式嵌入,是一个指向嵌入矩阵的查找表,如此,无论单词在什么上下文中出现,它将得到相同的向量
- 在每个时间步使用相同的前馈神经网络
- 不幸的是,固定长度的历史意味着它将只能以有界上下文为条件
- 这些模型确有非常快的特点
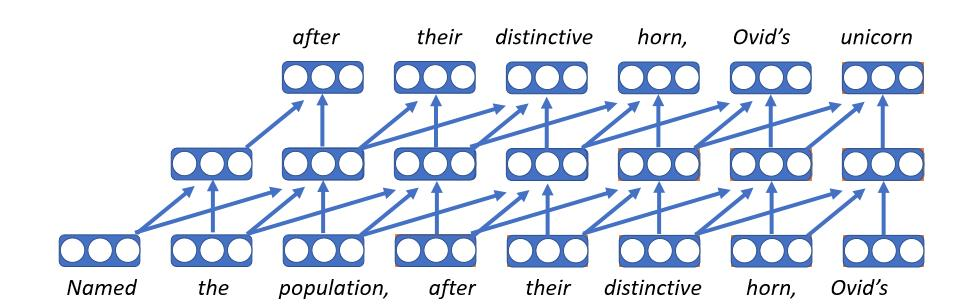
循环神经网络模型
- 这是直到前几年最为流行的方法
- 概念简单明了:每个时间步都维护一些状态(从上一个时间步接收到的),这些状态表示到目前为止我们所读到的内容。这将与当前正在读的单词结合起来,并在以后的状态下使用。然后我们按照我们需要的时间步骤重复这个过程。
- 使用无界的上下文:原理上,一本书的标题会影响书中最后一个字的隐藏状态。
- 弊端:
- 整个文档读取的历史在每个时间步都被压缩成一个固定大小的向量,这是该模型的瓶颈。
- 梯度在长上下文中消失
- 不可能在时间步上并行化,所以训练很慢
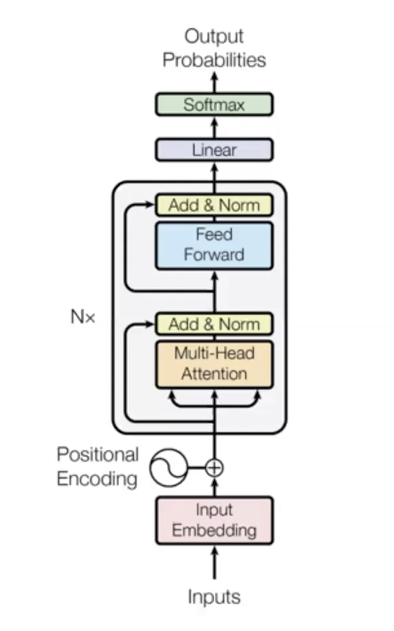
Transformer语言模型
- 在自然语言处理中使用的最新模型
- 革命性的点球Revolutionized penalty
- 三大主要阶段
- 输入阶段
- (N imes)不同参数的transformer块(编码层)
- 输出阶段
- 示例:在原论文中的6个变换器模组(编码层)
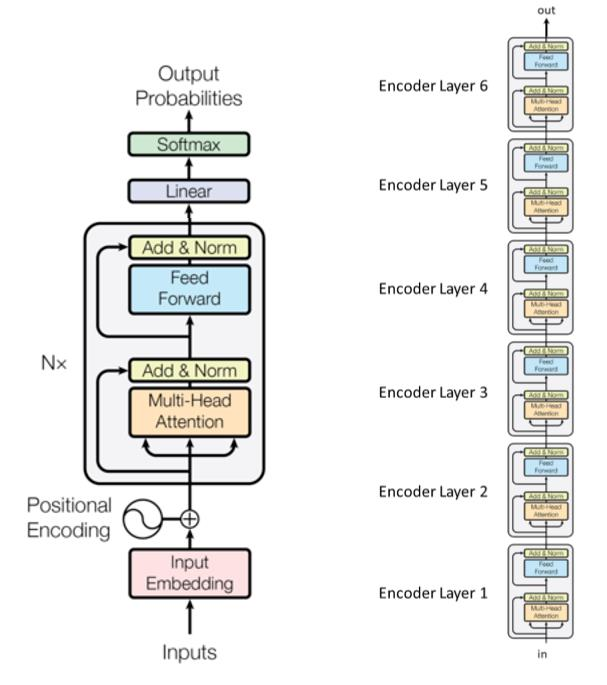
子层由标记为“Add&Norm”的框连接,这里“Add”意味着这是一个残差连接,有助于阻止梯度消失,这里“Norm”表示层的归一化normalization。
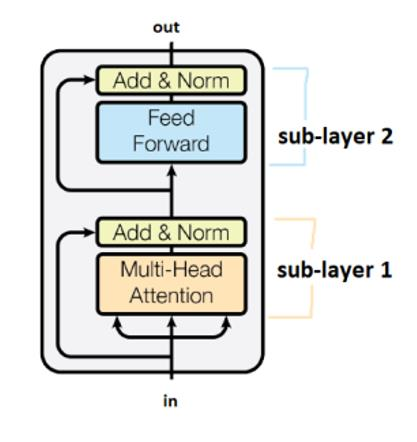
多头注意力
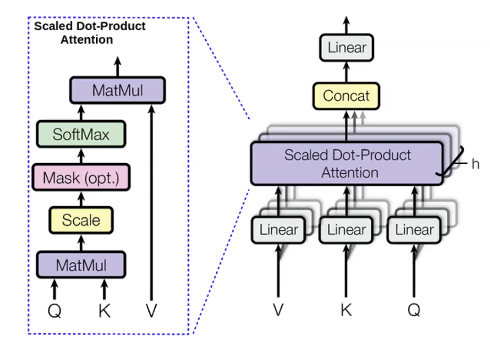
然后,我们还为前面单词计算被称为值(v)的量。值表示单词的内容。
一旦我们有了这些值,我们就可以通过最大化注意力分布来计算隐藏状态:
我们用多个不同的(lfloor查询 ceil)、(lfloor值 ceil)和(lfloor键 ceil)并行计算相同的东西。理由是我们想使用不同的东西预测下一个词。例如,当我们预测单词“unicorns”时,使用前面三个单词“These”、“horned”、“silver-white”。我们通过“horned”和“silver-white”知道它是一个独角兽。然而,我们通过“These”知道它是复数。因此,我们可能想要使用这三个词来知道下一个单词应该是什么。多头注意力是一种让每一个单词看到前面多个单词的方法。
多头注意力的一大优点就是它具有很强的并行性。与循环神经网络不同的是,它一次计算多头注意力模块的所有头和所有时间步。一次计算所有时间步的一个问题是,它还可以看到未来的单词,而我们只希望它以其前面的单词为条件。一个解决办法就是所谓的自我注意遮掩。掩码是一个下三角元素为0,上三角元素为负无穷的上三角矩阵。在注意模块的输出中添加这个掩码的效果是,左边的每一个单词都比右边的单词有更高的注意分数,所以在实践中模型只关注前面的单词。掩码的应用在语言模型中非常关键,因为这使得它在数学上正确,然而,在文本编码器中,双向上下文可能会有帮助。
使得transformer语言模型工作的一个细节是向输入中添加位置嵌入。在语言中,一些像顺序这样的属性对解释是非常重要的。这里使用的技术是学习不同时间步长的独立嵌入,并将这些添加到输入中,所以现在的输入是词向量和位置向量的总和。这将顺序信息。
为什么这个模型这么好:
- 它给出了每个单词对之间的直接联系。每个单词可以直接访问前面单词的隐层状态,减轻了梯度消失。它很容易学习非常昂贵的的函数。
- 所有时间步并行
- 自我注意力是二次的(所有时间步可以注意所有其他),(破除了?)极限最大序列长度。
一些技巧(特别是对于多头注意力和位置编码)和解码语言模型
技巧1:大量使用层归一化稳定训练是很有帮助的
- 对于transformer很重要
技巧2:热启动+反平方根训练计划
- 使用学习率计划:为了使transformer工作的更好,你必须使你的学习率从0到第1千步线性地衰减
技巧3:小心初始化
- 对于像机器翻译这样的任务很有用
技巧4:平滑标签
- 对于机器翻译这样的任务很有帮助
以下是上述几种方法的结果。在这些测试中,右边的指标是困惑度(perplexity,ppl)(ppl越低越好)。
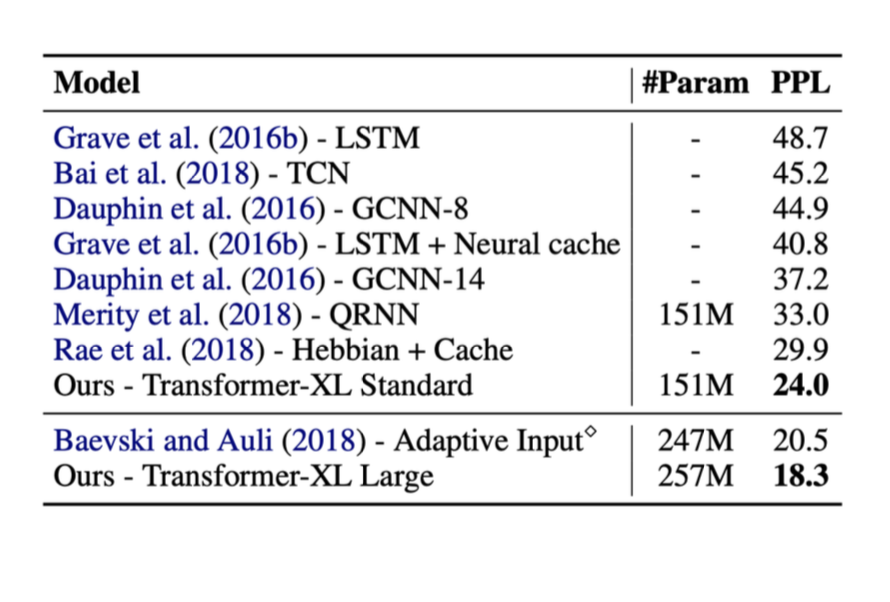
Transformer语言模型一些重要的事实
- 最小的inductive bias
- 所有单词直接连接,这将减轻梯度消失
- 所有时间步并行计算
- 自我注意力是二次的(所有时间步可以注意所有其他),(破除了?)极限最大序列长度。

Transformer很容易放大
- 无限的训练数据,甚至远远超过你需要的
- 2019年,GPT-2使用了20亿个参数
- 最近的模型在2020年使用了170亿个参数
解码语言模型
我们现在可以在文本上训练概率分布——现在我们可以得到指数级的多种可能输出,所以我们不能计算最大的(输出可能)。无论你对第一个单词做出什么选择,都会影响到其他所有的决定。因此,在此基础上,引入贪心解码如下。
贪心解码行不通
我们在每一个时间步都使用最有可能的单词。但是,这并不能保证给出最有可能的序列,因为如果您必须在某个点上执行这一步,那么您就无法回溯搜索以撤消以前的任何会话。
穷举搜索也不可能
它需要计算所有可能的序列因为复杂度为(O(V^T)),这太昂贵了。
理解问题和答案
- 与单头注意力相比,多都注意力模型的好处是什么?
- 要预测下一个单词,你需要观察多个独立的内容,换句话说,在试图理解预测下一个单词所需的上下文时,可以将注意力放在之前的多个单词,。
- Transformer如何解决CNN和RNN的信息瓶颈?
- 注意力模型允许所有单词之间的直接连接,允许每个单词以之前的所有单词为条件,有效地消除了这个瓶颈。
- Transformer与RNN在利用GPU并行化方面有何不同?
- Transformer中多头注意力模块是高度可并行的,然而RNN不是的,因此不能够充分利用GPU技术。事实上Transformer在一次前馈过程中计算所有时间步。