OpenCL
一、 CUDA vs OpenCL
1. 简介
OpenCL: Open Computing Language,开放计算语言。
OpenCL和CUDA是两种异构计算(此异构平台可由CPU,GPU或其他类型的处理器组成。)的编程模型。
- CUDA只支持NVIDIA自家的GPU。
- OpenCL最早是由Apple提出,后来交给了Khronos这个开放标准组织。OpenCL 1.0 在2008年底正式由Khronos发布,比CUDA晚了整整一年。
2012年移动图形处理器市场份额,imagenation失去苹果后一落千丈,已被别的公司收购:

2. 操作步骤
CUDA C加速步骤:
- 在device (也就是GPU) 上申请内存
- 将host (也就是CPU) 上的数据拷贝到device
- 执行CUDA kernel function
- 将device上的计算结果传回host
- 释放device上的内存
OpenCL操作步骤:
- 检测申请计算资源
- 检测platform, clGetPlatformIDs
- 检测platform对应的device, clGetDeviceInfo
- 建立context, clCreateContextFromType
- 建立command queue, clCreateCommandQueue
- 在context内申请存储空间, clCreateBuffer
- 将host (也就是CPU) 上的数据拷贝到device, clCreateBuffer
- OpenCL代码编译
- 读入OpenCL (kernel function) 源代码,创立program 句柄, clCreateProgramWithSource
- 编译program, clBuildProgram
- 创立一个 OpenCL kernel 句柄, clCreateKernel
- 申明设置 kernel 的 参数, clSetKernelArg
- 设置NDRange
- 运行kernel , clEnqueueNDRangeKernel
- 将device上的计算结果传回host, clEnqueueReadBuffer
- 释放计算资源
- 释放kernel, clReleaseKernel
- 释放program, clReleaseProgram
- 释放device memory, clReleaseMemObject
- 释放command queue, clReleaseCommandQueue
- 释放context, clReleaseContext

整体架构如下:

CUDA C语言与OpenCL的定位不同,或者说是使用人群不同。CUDA C是一种高级语言,那些对硬件了解不多的非专业人士也能轻松上手;而OpenCL则是针对硬件的应用程序开发接口,它能给程序员更多对硬件的控制权,相应的上手及开发会比较难一些。

3. 名词比较
Block: 相当于opencl 中的work-group
Thread:相当于opencl 中的work-item
SP: 相当于opencl 中的PE
SM: 相当于opencl 中的CU
warp: 相当于opencl 中的wavefront(简称wave),基本的调试单位
4. system tradeoff
各种硬件形态的开发效率与执行效率,而opencl在FPGA上作用就是绿色箭头的方向,可以有效提高FPGA开发效率。

二、常用API
1. clEnqueueNDRangeKernel

参数:
- command_queue,
- kernel,
- work_dim,使用多少维的NDRange,可以设为1, 2, 3, ..., CL_DEVICE_MAX_WORK_ITEM_DIMENSIONS。
- global_work_offset(GWO), 每个维度的偏移,如果不设置默认为0
- global_work_size(GWS),每个维度的索引长度,GWS(1) * GWS(2) * ... * GWS(N) 应该大于等于需要处理的数据量
- local_work_size(LWS), 每个维度work-group的大小,如果不设置,系统会自己选择一个合适的大小
- num_events_in_wait_list: 执行kernel前需要等待的event个数
- event_wait_list: 需要等待的event列表
- event: 当前这个命令会返回一个event,以供后面的命令进行同步
返回:
函数返回执行状态。如果成功, 返回CL_SUCCESS
2. clCreateBuffer

-
context
-
flags参数共有9种:
device权限,默认为可读写:
CL_MEM_READ_WRITE: kernel可读写
CL_MEM_WRITE_ONLY: kernel 只写
CL_MEM_READ_ONLY: kernel 只读创建方式:
CL_MEM_USE_HOST_PTR: device端会对host_ptr位置内存进行缓存,如果有多个命令同时使用操作这块内存的行为是未定义的
CL_MEM_ALLOC_HOST_PTR: 新开辟一段host端可以访问的内存
CL_MEM_COPY_HOST_PTR: 在devices新开辟一段内存供device使用,并将host上的一段内存内容copy到新内存上host权限,默认为可读写:
CL_MEM_HOST_WRITE_ONLY:host 只写
CL_MEM_HOST_READ_ONLY: host只读
CL_MEM_HOST_NO_ACCESS: host没有访问权限 -
size是buffer的大小
-
host_ptr只有在CL_MEM_USE_HOST_PTR, CL_MEM_COPY_HOST_PTR时才有效。
一般对于kernel函数的输入参数,使用CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR可以将host memory拷贝到device memory,表示device只读,位置在device上并进行内存复制,host权限为可读写;
对于输出参数,使用CL_MEM_WRITE_ONLY表示device只写,位置在device上,host权限为可读可写。
如果进行host与device之间的内存传递,可以使用clEnqueueReadBuffer读取device上的内存到host上, clEnqueueWriteBuffer可以将host上内存写到device上。
3. clEnqueueWriteBuffer

- command_queue,
- buffer, 将内存写到的位置
- blocking_write, 是否阻塞
- offset, 从buffer的多少偏移处开始写
- size, 写入buffer大小
- ptr, host端buffer地址
- num_events_in_wait_list, 等待事件个数
- event_wait_list, 等待事件列表
- event, 返回的事件
4. clCreateImage
创建一个ImageBuffer:

- context
- flags, 同clCreateBuffer里的flags
- image_format, 图像的属性,包含两个变量: image_channel_order, 指定通道数和形式,通常为RGBA;image_channel_data_type, 定义数据类型, CL_UNORM_INT8表示为unsigned规一化的INT8,CL_UNSIGNED_INT8
表示 为非规一化的unsigned int8 - image_desc, 定义图像的维度大小,
- host_ptr, 输入图像地址
- errorce_ret, 返回状态
5. clEnqueueWriteImage

- command_queue
- image, 目标图像
- block_writing, 是否阻塞,如果TRUE,则阻塞
- origin, 图像的偏移,通常为(0, 0, 0)
- region, 图像的区域,(width, height, depth)
- input_row_pitch,每行字节数,可能有对齐;如果设为0,则程序根据每个像素的字节数 乘以 width 计算
- input_slice_pitch,3D图像的2D slice块,如果是1D或2D图像,这个值必须为0
- ptr, host端输入源图像地址
- num_events_in_wait_list, 需等待事件个数
- evnet_wait_list, 需要等待的事件列表
- event, 返回这个命令的事件,用于后续使用
Map buffer
将cl_mem映射到CPU可访问的指针:

- command_queue
- buffer, cl_mem映射的源地址
- blocking_map, 是否阻塞
- map_flags, CL_MAP_READ,映射的地址为只读;CL_MAP_WRITE,向映射的地址写东西;CL_MAP_WRITE_INVALIDATE_REGION, 向映射的地址为写东西,host不会使用这段地址的内容,这时返回的地址处的内容不保证是最新的
- offset, cl_mem的偏移
- size, 映射的内存大小
- num_events_in_wait_list, 等待事件个数
- event_wait_list, 等待事件列表
- event, 返回事件
- errorcode_ret, 返回状态
返回值是CPU可访问的指针。
注意:
- 当flag为CL_MAP_WRITE时,如果不使用unmap进行解映射,device端无法保证可以获取到最新写的值。
- 如果不用unmap,那么device端无法释放这部分内存
所以写完内容后,要立马解映射。
buffer
clEnqueueCopyBuffer: 从一个cl buffer拷贝到另一个cl buffer
event
cl_int clWaitForEvents(cl_uint num_events, const cl_event *event_list)
等待事件执行完成才返回,否则会阻塞
cl_int clEnqueueWaitForEvents(cl_command_queue command_queue, cl_uint num_events, const cl_event *event_list)
和 clWaitForEvents 不同的是该命令执行后会立即返回,线程可以在不阻塞的情况下接着执行其它任务。而 clWaitForEvents 会进入阻塞状态,直到事件列表 event_list 中对应的事件处于 CL_COMPLETE 状态。
cl_int clFlush(cl_command_queue command_queue)
只保证command_queue中的command被commit到相应的device上,不保证当clFlush返回时这些command已经执行完。
cl_int clFinish(cl_command_queue command_queue)
clFinish直到之前的队列命令都执行完才返回。clFinish is also a synchronization point.
cl_int clEnqueueBarrier(cl_command_queue command_queue)
屏障命令保证在后面的命令执行之前,它前面提交到命令队列的命令已经执行完成。
和 clFinish 不同的是该命令会异步执行,在 clEnqueueBarrier 返回后,线程可以执行其它任务,例如分配内存、创建内核等。而 clFinish 会阻塞当前线程,直到命令队列为空(所有的内核执行/数据对象操作已完成)。
cl_int clEnqueueMarker(cl_command_queue command_queue, cl_event *event)
将标记命令提交到命令队列 command_queue 中。当标记命令执行后,在它之前提交到命令队列的命令也执行完成。该函数返回一个事件对象 event,在它后面提交到命令队列的命令可以等待该事件。例如,随后的命令可以等待该事件以确保标记之前的命令已经执行完成。如果函数成功执行返回 CL_SUCCESS。
三、架构
1. Platform Model
1个host加上1个或多个device,1个device由多个compute unit组成,1个compute unit又由多个Processing Elemnet组成。

2. Execution Model
执行模型:
一个主机要使得内核运行在设备上,必须要有一个上下文来与设备进行交互。 一个上下文就是一个抽象的容器,管理在设备上的内存对象,跟踪在设备上 创建的程序和内核。
主机程序使用命令队列向设备提交命令,一个设备有一个命令队列,且与上下文 相关。命令队列对在设备上执行的命令进行调度。这些命令在主机程序和设备上 异步执行。执行时,命令间的关系有两种模式:(1)顺序执行,(2)乱序执行。
内核的执行和提交给一个队列的内存命令会生成事件对象,可以用来控制命令的执行、协调宿主机和设备的运行。
有3种命令类型:
• Kernel-enqueue commands: Enqueue a kernel for execution on a device.(执行kernel函数)
• Memory commands: Transfer data between the host and device memory, between memory objects, or map and unmap memory objects from the host address space.(内存传输)
• Synchronization commands: Explicit synchronization points that define order constraints between commands.(同步点)
命令执行经历6个状态:
- Queued: 将command放到CommandQueue
- Submitted: 将command从CommandQueue提交到Device
- Ready: 当所有运行条件满足,放到Device的WorkPool里
- Running: 命令开始执行
- Ended: 命令执行结束
- Complete: command以及其子command都结束执行,并设置相关的事件状态为CL_COMPLETE

Mapping work-items onto an NDRange:
与CUDA里的grid, block, thread类似,OpenCL也有自己的work组织方式NDRange。NDRange是一个N维的索引空间(N为1, 2, 3...),一个NDRange由三个长度为N的数组定义,与clEnqueueNDRangeKernel几个参数对应:
- global_work_size(GWS),每个维度的索引长度,GWS(1) * GWS(2) * ... * GWS(N) 应该大于等于需要处理的数据量
- global_work_offset(GWO), 每个维度的偏移,如果不设置默认为0
- local_work_size(LWS), 每个维度work-group的大小,如果不设置,系统会自己选择较好的结果
如下图所示,整个索引空间的大小为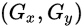 ,每个work-group大小为
,每个work-group大小为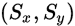 ,全局偏移为
,全局偏移为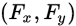 。
。
对于一个work-item,有两种方式可以索引:
- 直接使用global id
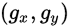
- 或者使用work-group进行相关计算,设当前group索引为
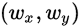 ,group里的local id分别为(s_x, s_y),那么便有
,group里的local id分别为(s_x, s_y),那么便有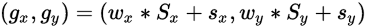

3. Memory Model
不同平台的内存模型不一样,为了可移植性,OpenCL定义了一个抽象模型,程序的实现只需要关注抽象模型,而具体的向硬件的映射由驱动来完成。

主要分为host memory和device memory。而device memory 一共有4种内存:
private memory:是每个work-item各自私有
local memory: 在work-group里的work-item共享该内存
global memory: 所有memory可访问
constant memory: 所有memory可访问,只读,host负责初始化

4. Program Model
OpenCL支持数据并行,任务并行编程,同时支持两种模式的混合。
分散收集(scatter-gather):数据被分为子集,发送到不同的并行资源中,然后对结果进行组合,也就是数据并行;如两个向量相加,对于每个数据的+操作应该都可以并行完成。
分而治之(divide-and-conquer):问题被分为子问题,在并行资源中运行,也就是任务并行;比如多CPU系统,每个CPU执行不同的线程。还有一类流水线并行,也属于任务并行。流水线并行,数据从一个任务传送到另外一个任务中,同时前一个任务又处理新的数据,即同一时刻,每个任务都在同时运行。

并行编程就要考虑到数据的同步与共享问题。
in-order vs out-of-order:
创建命令队列时,如果没有为命令队列设置 CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE 属性,提交到命令队列的命令将按照 in-order 的方式执行。
OpenCL支持两种同步:
同一工作组内(work-group)工作项(work-item)的同步(实现方式barrier):
reduction的实现中,需要进行数据同步,所谓reduction就是使用多个数据生成一个数据,如tensorflow中的reduce_mean, reduce_sum等。在执行reduce之前,必须保证这些数据已经是有效的,执行过的,
命令队列中处于同一个上下文中的命令的同步(使用clWaitForEvents,clEnqueueMarker, clEnqueueBarrier 或者执行kernel时加入等待事件列表)。
有2种方式同步:
锁(Locks):在一个资源被访问的时候,禁止其他访问;
栅栏(Barriers):在一个运行点中进行等待,直到所有运行任务都完成;(典型的BSP编程模型就是这样)
数据共享:
(1)shared memory
当任务要访问同一个数据时,最简单的方法就是共享存储shared memory(很多不同层面与功能的系统都有用到这个方法),大部分多核系统都支持这一模型。shared memory可以用于任务间通信,可以用flag或者互斥锁等方法进行数据保护,它的优缺点:
优点:易于实现,编程人员不用管理数据搬移;
缺点:多个任务访问同一个存储器,控制起来就会比较复杂,降低了互联速度,扩展性也比较不好。
(2)message passing
数据同步的另外一种模型是消息传递模型,可以在同一器件中,或者多个数量的器件中进行并发任务通信,且只在需要同步时才启动。
优点:理论上可以在任意多的设备中运行,扩展性好;
缺点:程序员需要显示地控制通信,开发有一定的难度;发送和接受数据依赖于库方法,因此可移植性差。
Experiment
1. 向量相加
guru_ge@dl:~/opencl/test$ ./cuda_vector_add
SUCCESS
copy input time: 15438.000000
CUDA time: 23.000000
copy output time: 17053.000000
CPU time: 16259.000000
result is right!
guru_ge@dl:~/opencl/test$ ./main
Device: GeForce GTX 1080 Ti
create input buffer time: 7
create output buffer time: 1
write buffer time: 4017
OpenCL time: 639
read buffer time: 30337
CPU time: 16197
result is right!
guru_ge@dl:~/opencl/test$ ./cuda_vector_add
SUCCESS
copy input time: 59825.000000
CUDA time: 36.000000
copy output time: 67750.000000
CPU time: 64550.000000
result is right!
guru_ge@dl:~/opencl/test$ ./main
Device: GeForce GTX 1080 Ti
create input buffer time: 7
create output buffer time: 1
write buffer time: 52640
OpenCL time: 1634
read buffer time: 80206
CPU time: 66502
result is right!
guru_ge@dl:~/opencl/test$
Reference
- https://www.cnblogs.com/wangshide/archive/2012/01/07/2315830.html
- https://www.cnblogs.com/hlwfirst/p/5003504.html
- http://blog.csdn.net/leonwei/article/details/8909897
- https://blog.csdn.net/babyfacer/article/details/6863572
- https://blog.csdn.net/xbinworld/article/details/45949629
- https://blog.csdn.net/Bob_Dong/article/details/70172165?locationNum=11&fps=1