爬虫工具:webmagic
爬取百度图片,不能通过获取html然后通过匹配标签的形式,而是要找到对应的提供json数据的请求,最初自信满满的按官方文档注解形式写了model,pipeline,然后就运行时就发现问题很大。
开始是获取不到html,然后通过调试发现可以获得rayText,但是只有简单的外层标签和数据,并没有图片相关数据。
我将代码放到下面,processor中定义了一个静态变量Set,用来保存图片url,剩下的就根据需求自己扩展了。
下面是pageProcessor的实现方法

接着是开启线程
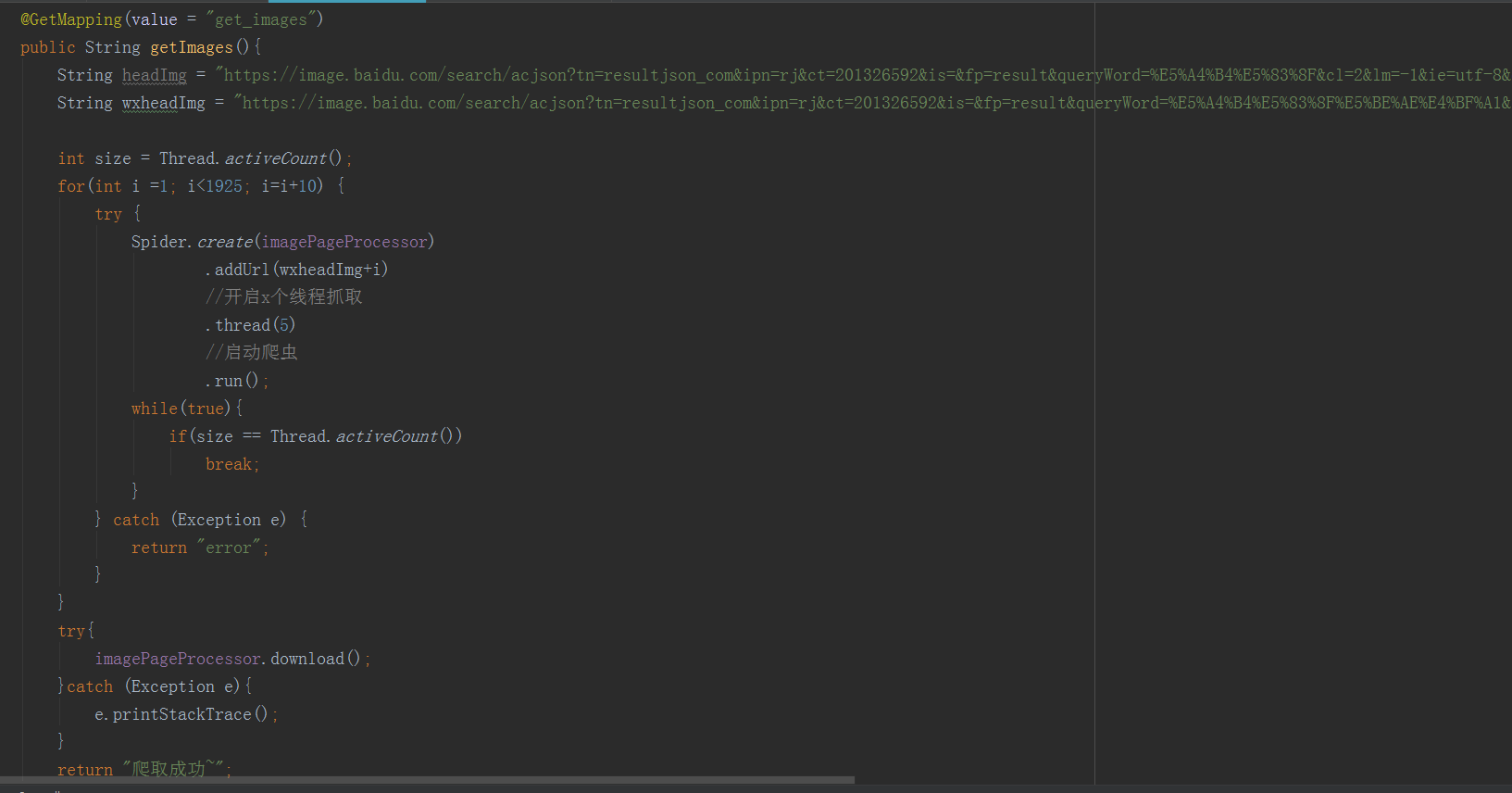
将图片通过io保存到本地文件夹中
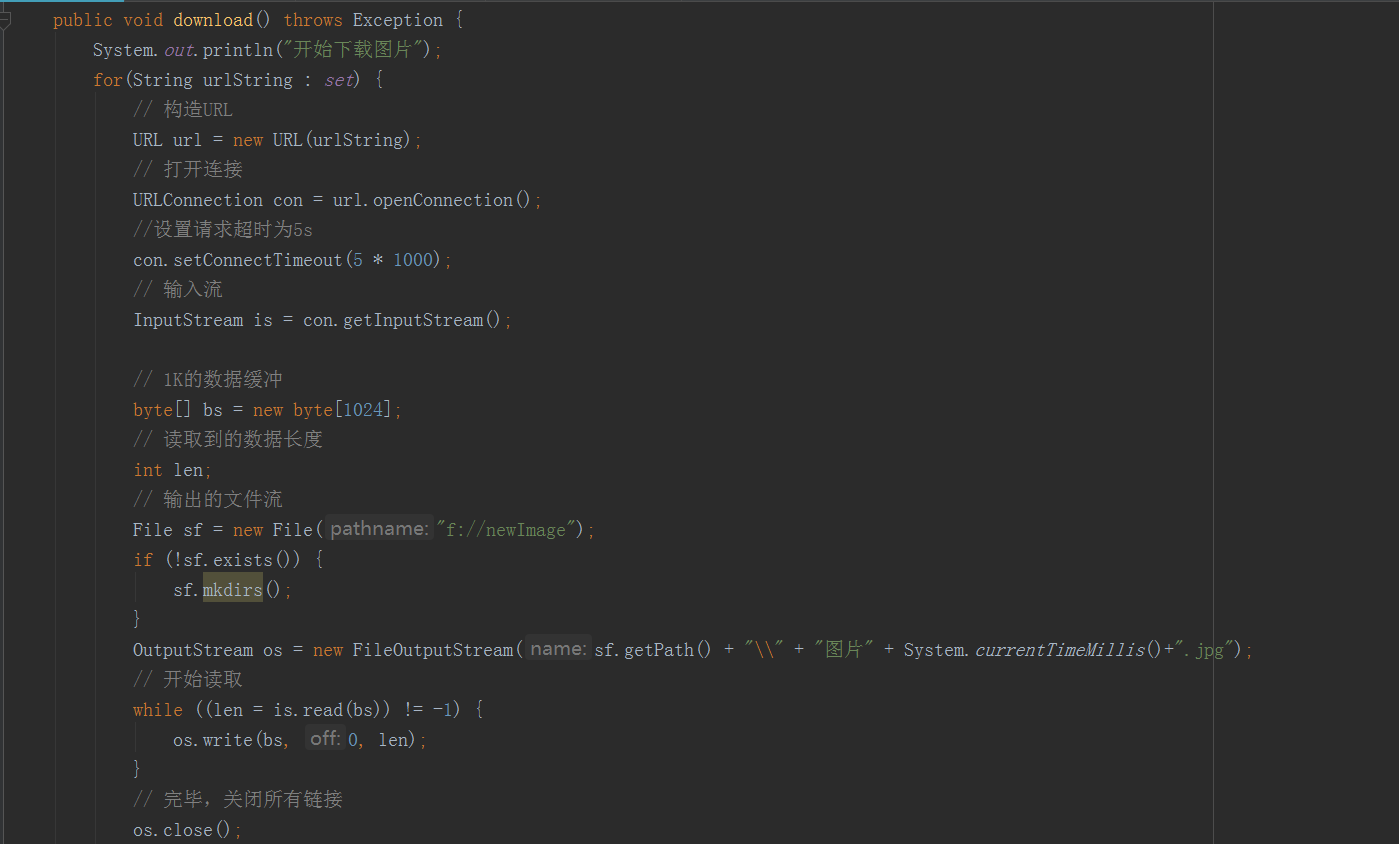
最后,头像成功的保存到本地了
