ado.net EF是微软的一个ORM框架,使用过EF的同学都知道EF有一个延迟加载的技术。
如果你是一个老鸟,你可能了解一些,如果下面的学习过程中哪些方面讲解的不对,欢迎批评指教。如果一个菜鸟,那我们就一起开始今天的学习。
首先,提出以下几个问题。
何为延迟加载呢?
我们该如何使用呢?
我们为什么要使用延迟加载技术呢?
延迟加载技术有什么优、缺点呢?
好,带着上面的问题我们开始今天的学习。
1.何为延迟加载
EF的延迟加载,就是使用Lambda表达式或者Linq 从 EF实体对象中查询数据时,EF并不是直接将数据查询出来,而是在用到具体数据的时候才会加载到内存。说白了就是按需加载。
2.如何使用延迟加载技术
在这里,我们添加一个实体数据模型,对应的是数据库中的Flower、Indicator两个表。具体表的定义如下所示。
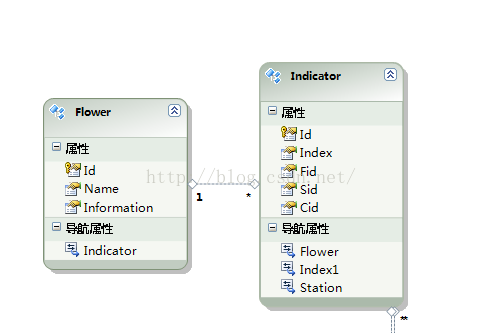
下面我们就根据上面的数据模型编写一个具体的延迟加载,我们到里面一探究竟。
编写代码,截图如下所示。

看到我上面代码截图中标注的内容了吗?
通过上面的Lambda表达式查询出来的数据是一个实现了IQueryable接口的类,在这里是ObjectSet<Folwer>,实体集。
不相信是吗?那好,我们继续查看源码。

上面的代码说明我们通过entity.Flower查询出来的是一个ObjectSet<Flower>类型的数据。
而接下来的代码有说明,这个ObjectSet<T>类型的数据实现了IQueryable接口,按照面向接口编程的原则,当然可以使用接口对象来接收查询出来的实体集。同时也实现了IEnumable接口,也就可以使用foreach()遍历集合。

上面的都是对代码进行的解释,那么真正的延迟加载又是体现在哪里呢?
完整代码如下所示

为了方便观察,在上面的查询代码处添加断点,打开sql server profiler监视工具,运行程序,开始观察
程序在断点处停下来
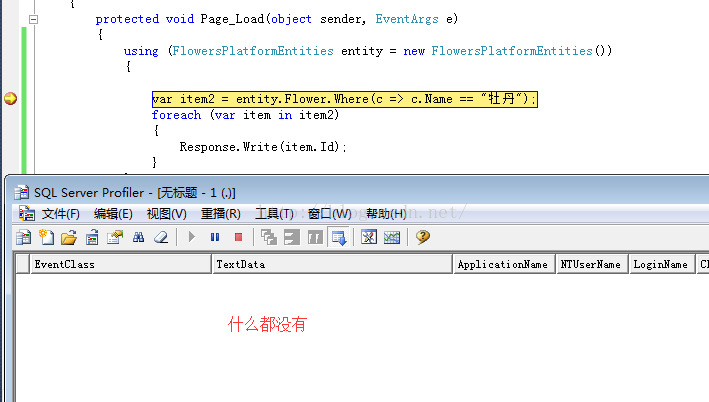
继续单步调试

通过监视工具我们知道,此时并没有sql语句的查询操作。
OK,继续单步调试
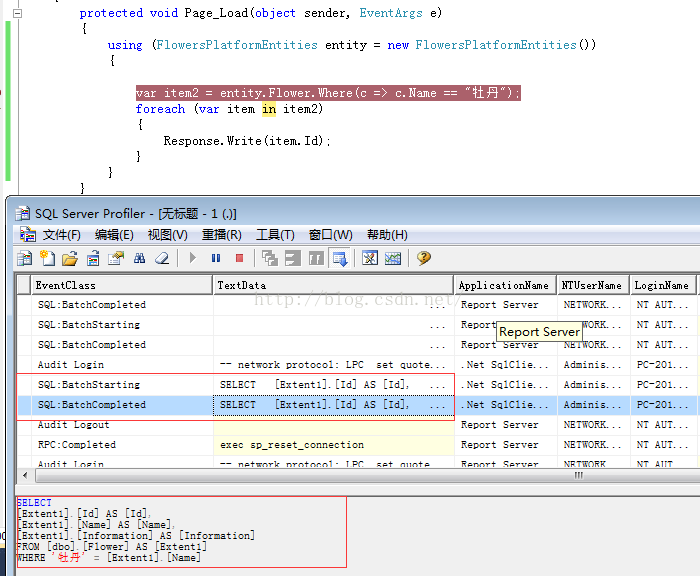
Ok,当我们走到item2的时候发现sql语句执行了,数据查询出来了。
对上面的过程解释一下entity.Flower.where()的时候sql语句并没执行,当我们在下面需要用到上面查询语句的结果集item2的时候sql语句真正执行了。
没错,这就是EF的延迟加载技术,只有在数据真正用到的时候才会去数据库中查询。
顺便说一下,EF实现延迟加载的核心就是因为IQueryable接口的使用。如果我们把上面的代码修改一下,如下所示。

看到上面查询的返回值了吗?是一个Flower变量。如果你再添加断点,打开监视工具可以发现,这个时候已经没有延迟加载了。
上面只是延迟加载技术的一种,我们接下来学习另一种延迟加载技术。
上面我们定义的两个表Flower和Indicator表两者之间是一对多的关系,如果我们想要查询某个Flower下的所有Indicator数据,我们应该怎么做呢?
如果放在以前,你可能会说,我们使用表之间的连接查询不就行了吗?
不错,这确实是一种方法。不过你有没有想过连接查询就是笛卡尔积查询,如果查询Flower表下的所有对应Indicator数据,这个查询量又是多少呢?
Flower表有1万条记录,Indicator表也有1万条记录,那么他们的笛卡尔积就是一亿条数据,这样的查询肯定不是高效的。
解决方法就可以操作EF的另一种延迟加载技术,实现的核心就是实体类的导航属性。
在开始之前,我们再看一下上面Flower和Indicator两个表的导航属性

编写具体代码如下所示。

在上面的代码foreach循环出添加断点,运行程序,打开监视工具,观察
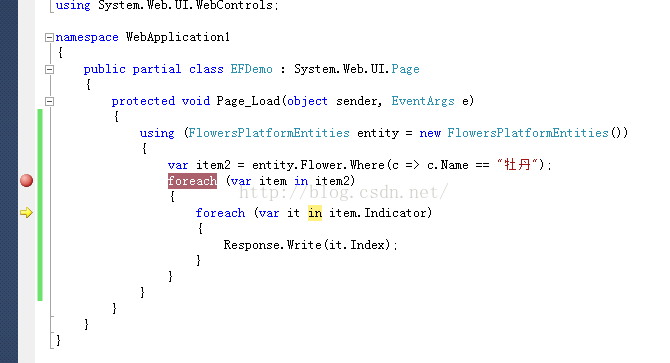
执行到第一个foreach()循环的时候会执行一个查询,上面已经说得很清楚了。
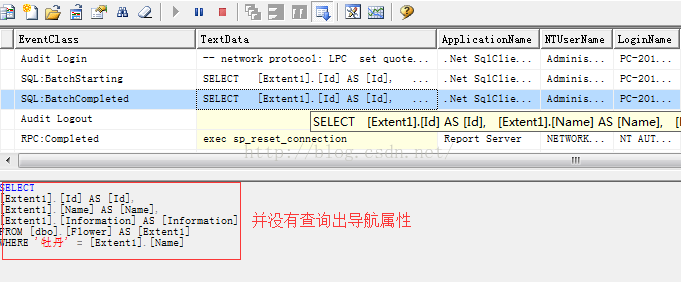
但是一定要注意,此时并没有查询出导航属性。
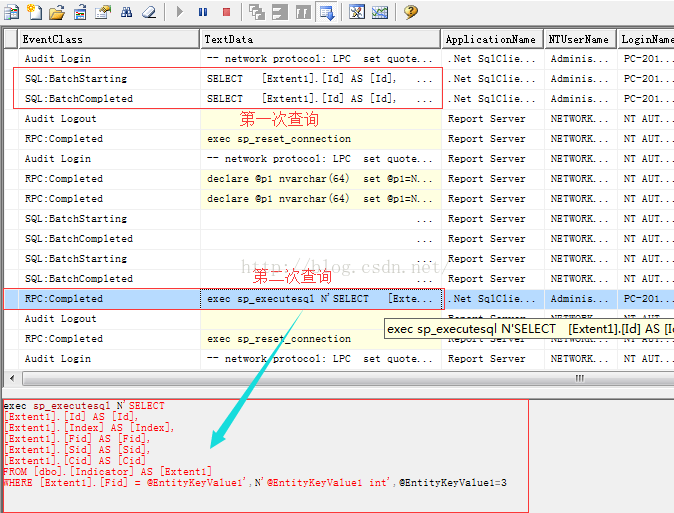
执行到第二个foreach()循环的时候,我们看到又执行了一条查询语句。
这个时候你可能就疑惑了,我们并没有要求查询啊,其实,这个查询是根据导航属性自动帮助我们查询的。
这就是第二种延迟加载技术,当我们需要用到导航属性的时候,如果导航属性不存在内存中,EF会自动帮助我们把导航属性查询出来加载到内存中。此种延迟加载技术,现在应用的非常广泛。
在此总结一下,只要查询结果是实现了IQueryable接口的类,查询的结果都是延迟加载的。(不知道这句话说的准确不准确)
Ok,上面介绍了为何要使用延迟加载技术,那么我们为何要使用这种技术呢?
3.为何要使用延迟加载技术
上面的长篇大论简要的解释了一下EF的延迟加载机制,说了那么多,那到底为什么需要延迟加载呢?直接取直接用不就好了?
确实,从上面的简单例子来看延迟加载貌似很多余,但是通常我们操作数据库不可能只是这么简单的。
就拿很常用的分页来说,一般是先对数据进行排序,然后按照要求跳过几行数据,在取几行数。这就不是一个简单的where方法可以实现的了
至少需要先调用order进行排序,然后skip跳过几行数据,最后take取几行数据。如果where/order/skip/take等等方法每次使用的时候就马上提交sql语句到数据库,那做一个分页查询至少要发送4次请求,也就是说要和数据库交互4次。如果使用延迟加载的话上面的where/order/skip/take方法调用的时候可以看做只是在拼凑条件,当条件满足的时候(一般就是要用数据的时候,比如说FirstOrDefault方法),在将整个拼凑好的sql语句一起提交到数据库,这样一来和数据库的交互次数由4降到了1。是不是很高效了?
确实,从上面的简单例子来看延迟加载貌似很多余,但是通常我们操作数据库不可能只是这么简单的。
就拿很常用的分页来说,一般是先对数据进行排序,然后按照要求跳过几行数据,在取几行数。这就不是一个简单的where方法可以实现的了
至少需要先调用order进行排序,然后skip跳过几行数据,最后take取几行数据。如果where/order/skip/take等等方法每次使用的时候就马上提交sql语句到数据库,那做一个分页查询至少要发送4次请求,也就是说要和数据库交互4次。如果使用延迟加载的话上面的where/order/skip/take方法调用的时候可以看做只是在拼凑条件,当条件满足的时候(一般就是要用数据的时候,比如说FirstOrDefault方法),在将整个拼凑好的sql语句一起提交到数据库,这样一来和数据库的交互次数由4降到了1。是不是很高效了?
当然还有其他的例子,在这里就不列举了。
4.延迟加载技术的优缺点
优点在上面讲解第二类延迟加载技术和为何要使用延迟加载技术的时候已经说过了,下面我们主要来说一下EF延迟加载技术的缺点。
缺点:
(1)每次使用的时候都会去查询数据库
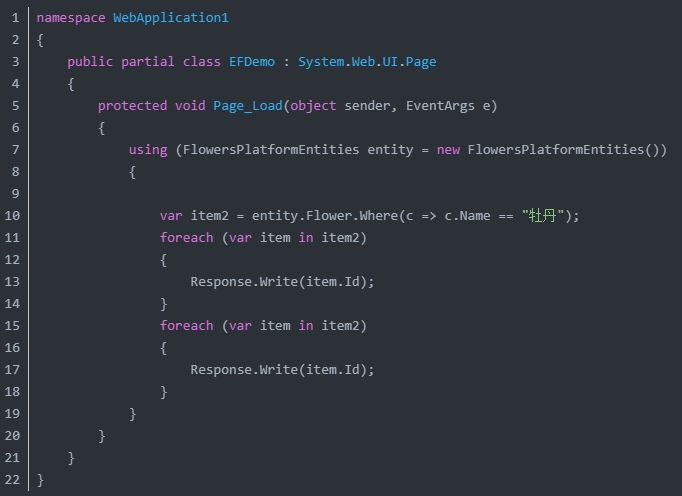
上面的代码在程序执行的时候,你认为会执行几次的数据库查询操作?一次?两次?
我们通过监视工具来说明问题
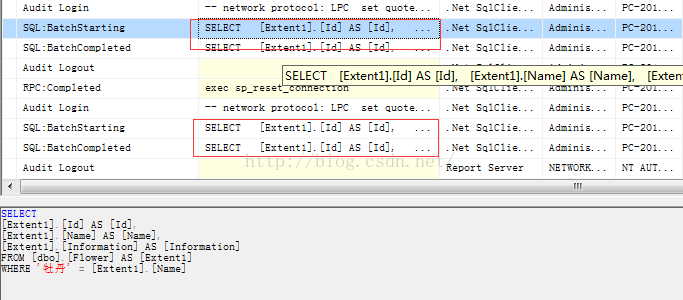
OK,看到了吗?其实是执行了两次。每次需要使用到数据的时候都要执行查询操作。
当然,这个缺点也是可以使用缓存技术解决的