教程:http://dblab.xmu.edu.cn/blog/1327
安装IntelliJ IDEA
官网:https://www.jetbrains.com/idea/download/#section=linux

cd ~/下载 sudo tar -zxvf ideaIC-2019.3.2.tar.gz sudo mv idea-IC-193.6015.39 /usr/local/Intellij
打开程序
cd /usr/local/Intellij/bin
./idea.sh
弹出以下界面
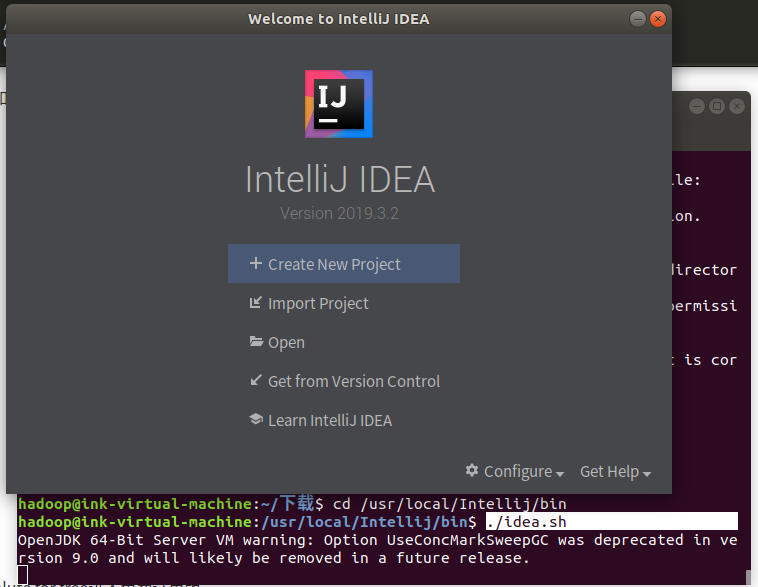
在IntelliJ IDEA里安装scala插件
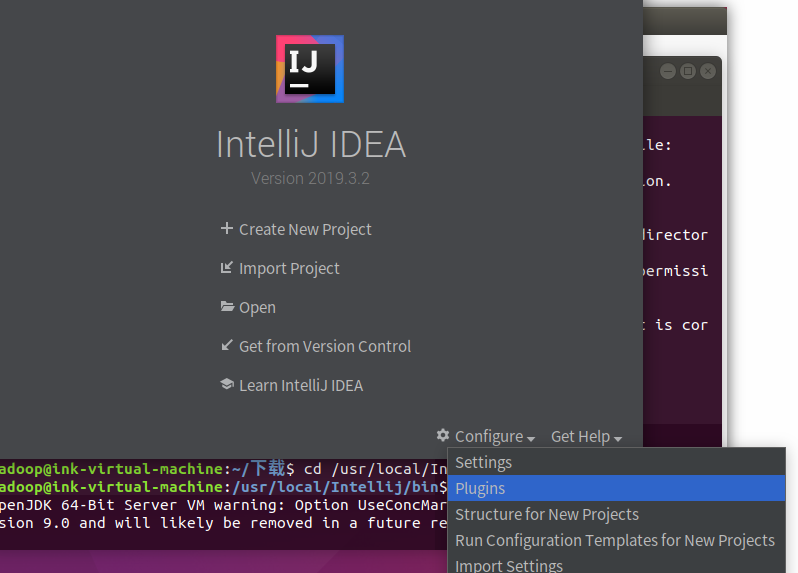
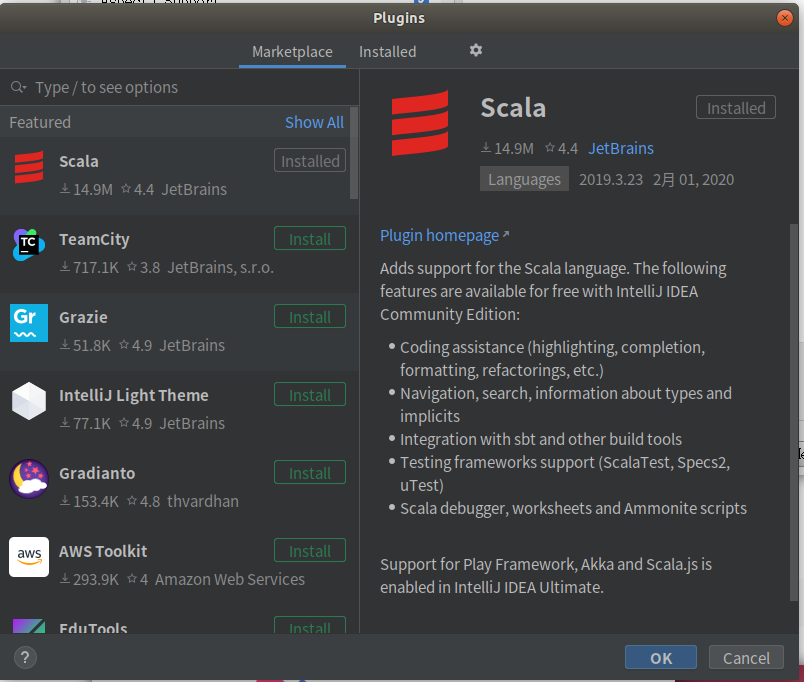
可以看到它已经自动安装了
配置JDK
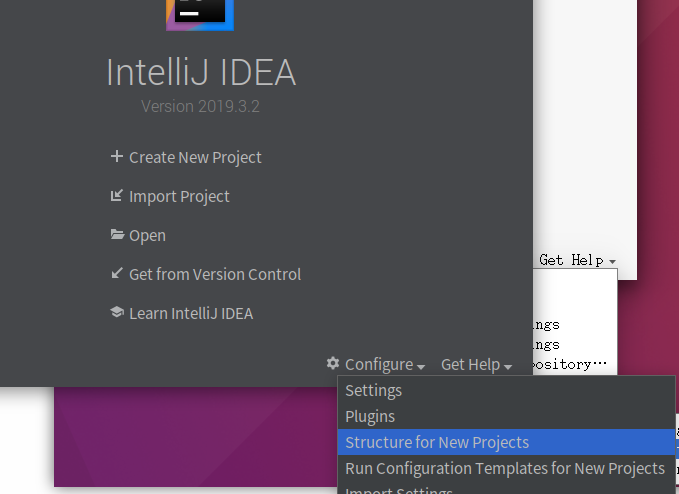
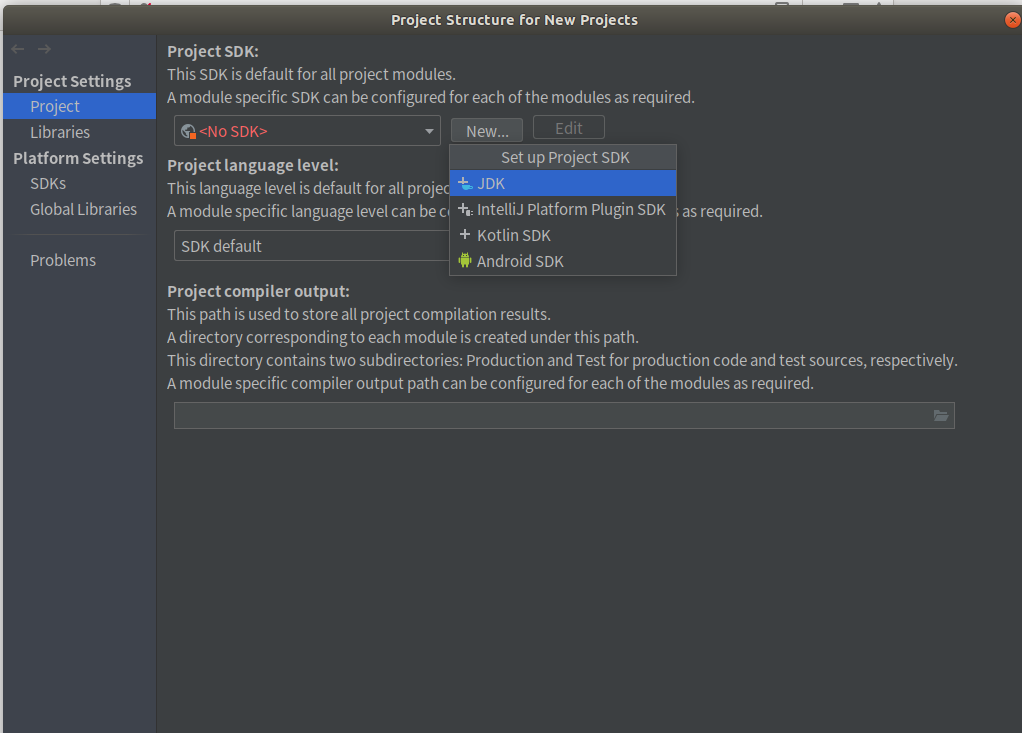
(补:这边后来发现有点问题,我的jdk版本是1.8,当时是1.11默认选中,而且和教程中看着挺像的,但是还是应该选自己的版本)

配置全局scala sdk

(补:上面jdk选对了后会出来maven的选项)

右键刚添加的SDK
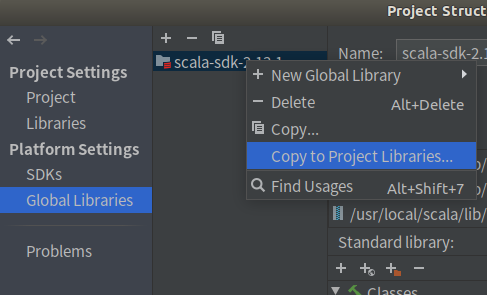


创建maven工程文件

maven -> next
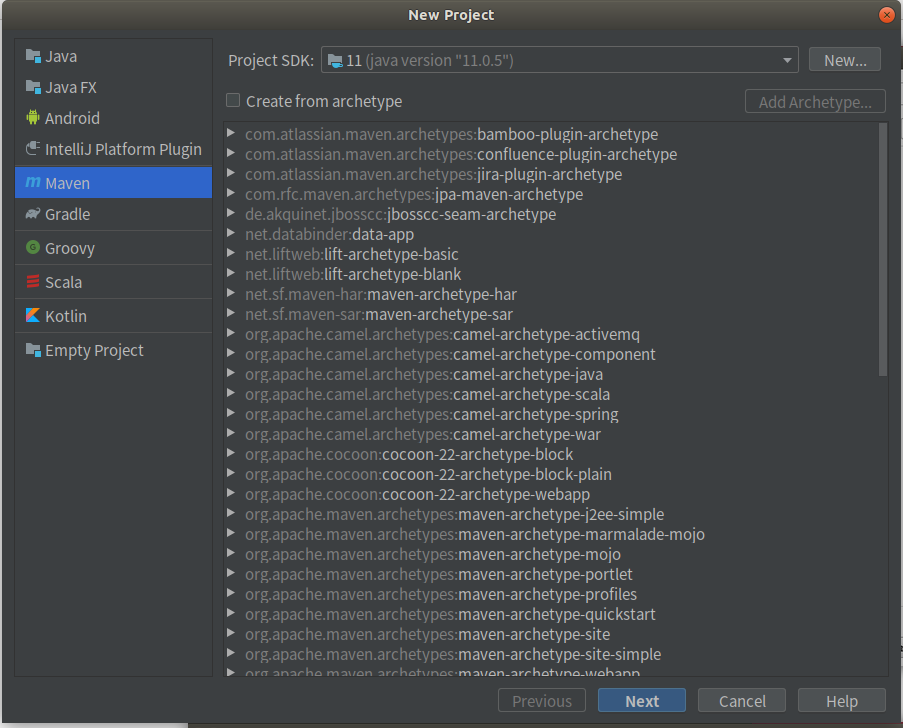
填写Name、Location、Groupld、ArtifactId -> finish

将scala框架添加到项目
在启动后进入的项目中,点击Project,就可以看到名称为WordCount的工程。
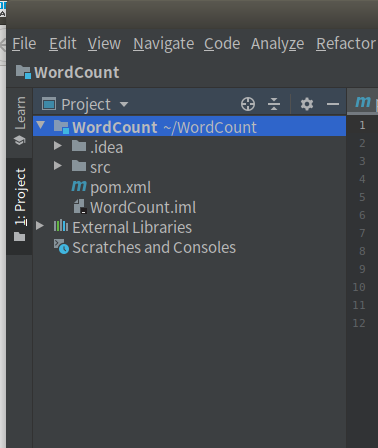
右键工程名称WordCount
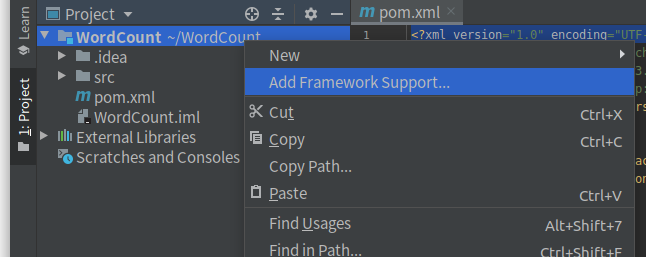
勾选scala

运行
在src下新建WordCount文件夹
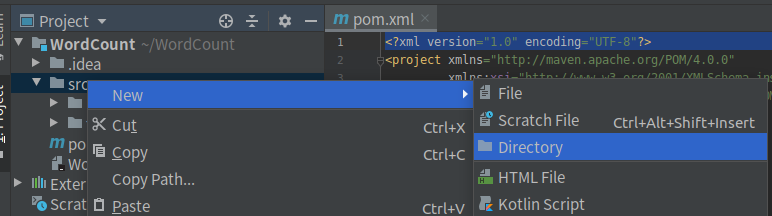
右键新建的文件夹

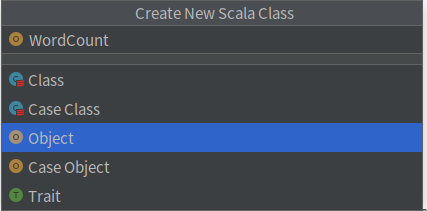
右键WordCount文件夹,新建scala slass

命名为WordCount,object类型
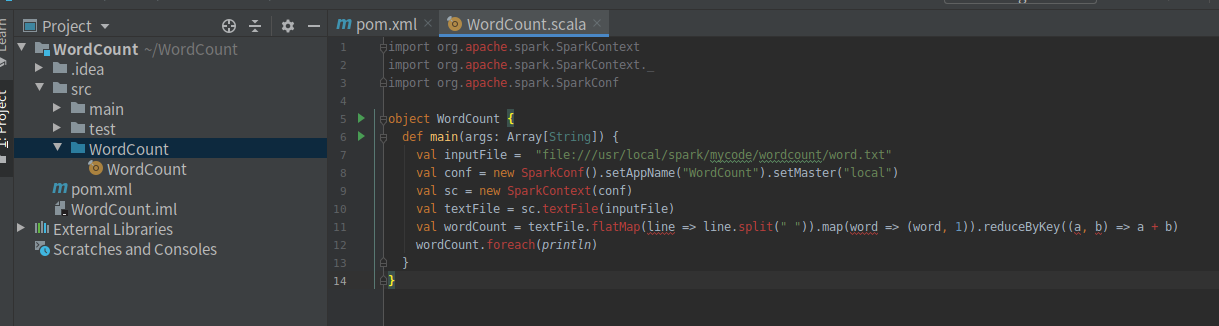
打开WordCount.scala,清空并粘贴代码(代码是从文件里提取内容进行词频统计,请确保路径存在)
import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf object WordCount { def main(args: Array[String]) { val inputFile = "file:///usr/local/spark/mycode/wordcount/word.txt" val conf = new SparkConf().setAppName("WordCount").setMaster("local") val sc = new SparkContext(conf) val textFile = sc.textFile(inputFile) val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b) wordCount.foreach(println) } }
清空pom.xml并粘贴代码(根据个人的spark版本修改)
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>dblab</groupId> <artifactId>WordCount</artifactId> <version>1.0-SNAPSHOT</version> <properties> <spark.version>2.1.0</spark.version> <scala.version>2.11</scala.version> </properties> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <version>2.15.2</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.6.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-surefire-plugin</artifactId> <version>2.19</version> <configuration> <skip>true</skip> </configuration> </plugin> </plugins> </build> </project>
右键WordCount工程文件夹

点击右下角的Enable Auto-import
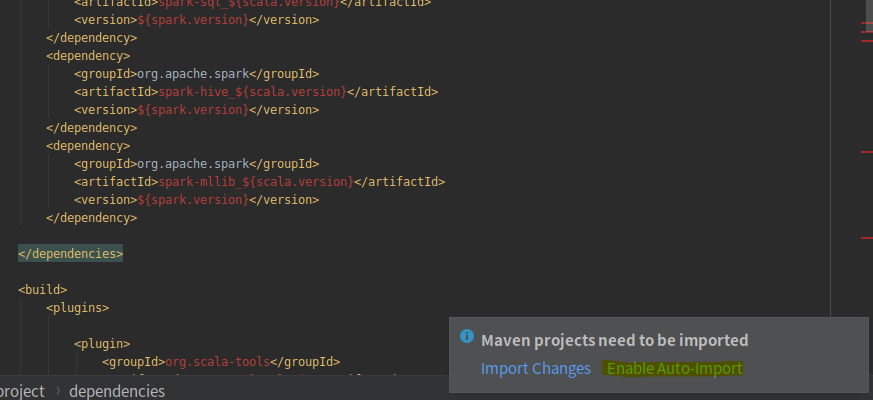
等待底部进度条

……
在WordCount.scala窗口内任意位置右键选择run
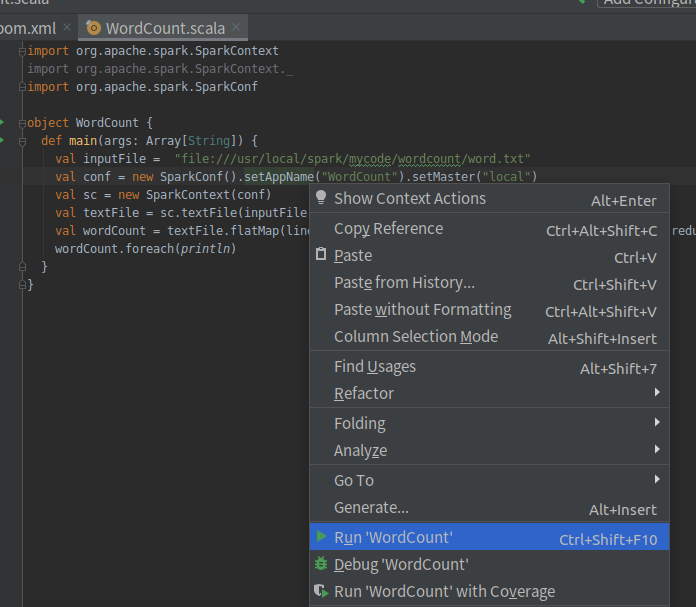
注意根据代码,必须有/usr/local/spark/mycode/wordcount/word.txt这个文件

报错
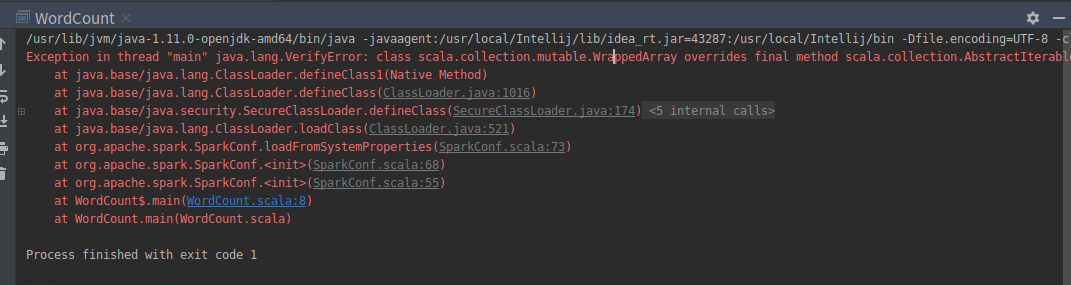
正在解决……
目前正就着版本不对的方向尝试解决...