模型召回之DSSM
双塔模型
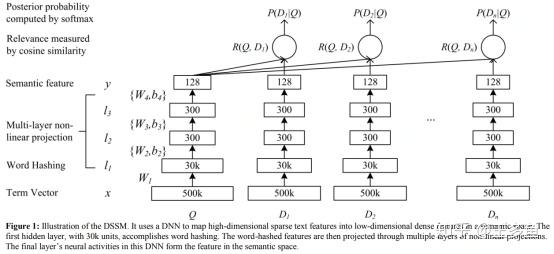
负样本构造:训练前构造或训练时批内构造
实现
model
from transformers import AutoConfig,AutoTokenizer,TFAutoModel
MODEL_NAME = "hfl/chinese-roberta-wwm-ext"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
config = AutoConfig.from_pretrained(MODEL_NAME)
# backbone = TFAutoModel.from_pretrained(MODEL_NAME)
# tokenizer.save_pretrained('model')
# config.save_pretrained('model')
# backbone.save_pretrained('model')
class baseModel(tf.keras.Model):
def __init__(self,MODEL_NAME,finetune=False,pooler="avg"):
super().__init__()
self.pooler = pooler
self.backbone = TFAutoModel.from_pretrained(MODEL_NAME)
if not finetune:
self.backbone.trainable = False
print("bert close")
self.dense_layer = tf.keras.layers.Dense(128)
def call(self,inputs):
x = self.backbone(inputs)
if self.pooler == "cls":
x = x[1]
elif self.pooler == "avg":
x = tf.reduce_mean(x[0],axis=1)
elif self.pooler == "max":
x = tf.reduce_max(x[0],axis=1)
x = self.dense_layer(x)
return x
class DSSMBert(tf.keras.Model):
def __init__(self,MODEL_NAME,finetune=False):
super().__init__()
self.basemodel = baseModel(MODEL_NAME,finetune)
self.softmax = tf.keras.layers.Activation("softmax")
self.dot = tf.keras.layers.Dot(axes=1, normalize=True)
def call(self,query_inputs,pos_inputs,neg_inputs):
query_x = self.basemodel(query_inputs)
pos_x = self.basemodel(pos_inputs)
neg_xs = [self.basemodel(neg_input) for neg_input in neg_inputs]
neg_cosines = [self.dot([query_x,neg_x]) for neg_x in neg_xs]
x = tf.concat([self.dot([query_x,pos_x])] + neg_cosines,axis=1)
x = self.softmax(x)
return x
dataset
def data_generator(low,size,batch_size,train_data,neg_nums=5):
train_data = train_data.sample(frac=1)
for k in range(low,size,batch_size):
querys = train_data.query_content[k:k+batch_size].values.tolist()
pos_docs = train_data.doc_content[k:k+batch_size].values.tolist()
query_inputs = tokenizer(querys, max_length=15, padding=True,truncation=True,return_tensors="tf")
pos_doc_inputs = tokenizer(pos_docs, max_length=50, padding=True,truncation=True,return_tensors="tf")
neg_doc_inputs = []
for i in range(neg_nums):
ix = np.random.randint(0,train_data.shape[0],batch_size)
neg_docs = train_data.doc_content[ix].values.tolist()
neg_doc_input = tokenizer(neg_docs, max_length=50, padding=True,truncation=True,return_tensors="tf")
neg_doc_inputs.append(neg_doc_input)
neg_label = [0]*neg_nums
labels = [[1]+neg_label]*batch_size
labels = tf.convert_to_tensor(labels)
yield query_inputs,pos_doc_inputs,neg_doc_inputs,labels
train
loss_func = tf.keras.losses.CategoricalCrossentropy()
accuracy = tf.keras.metrics.CategoricalAccuracy()
optimizer = tf.keras.optimizers.Adam(1e-4)
acc_metric = tf.keras.metrics.CategoricalAccuracy()
#(experimental_relax_shapes=True)
@tf.function
def train_step(query, pos_doc, neg_doc, labels):
with tf.GradientTape() as tape:
y_pred = model(query, pos_doc, neg_doc,training=True)
loss = loss_func(labels, y_pred)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
acc_metric.update_state(labels, y_pred)
return loss, y_pred
epochs = 5
batch_size = 128
t0 = time.time()
for i in range(epochs):
ds = data_generator(0,train_data.shape[0]-batch_size, batch_size, train_data)
print(f"epoch {i}, training ")
for step, (query, pos_doc, neg_doc, labels) in enumerate(ds):
loss, y_ = train_step(query, pos_doc, neg_doc, labels)
if step % 50 == 0:
print("Iteration step: {}; Loss: {:.3f}, Accuracy: {:.3%}, spend time: {:.3f}".format(step,loss,acc_metric.result(),time.time()-t0))
# Reset metrics every epoch
acc_metric.reset_states()
print("save model")
model.save_weights(workdir+f"checkpoints/dssm_robert/dssm_bert_{i}")