递归
递归调用:在调用一个函数的过程中,直接或间接地调用了函数本身
直接 def func(): print('from func') func() func() 间接 def foo(): print('from foo') bar() def bar(): print('from bar') foo() foo()
递归的执行分为两个阶段:
1 递推
2 回溯
递归特性:
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
堆栈扫盲http://www.cnblogs.com/lln7777/archive/2012/03/14/2396164.html
尾递归优化:http://egon09.blog.51cto.com/9161406/1842475
二分查找
data = [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35] def binary_search(dataset,find_num): print(dataset) if len(dataset) >1: mid = int(len(dataset)/2) if dataset[mid] == find_num: #find it print("找到数字",dataset[mid]) elif dataset[mid] > find_num :# 找的数在mid左面 print("�33[31;1m找的数在mid[%s]左面�33[0m" % dataset[mid]) return binary_search(dataset[0:mid], find_num) else:# 找的数在mid右面 print("�33[32;1m找的数在mid[%s]右面�33[0m" % dataset[mid]) return binary_search(dataset[mid+1:],find_num) else: if dataset[0] == find_num: #find it print("找到数字啦",dataset[0]) else: print("没的分了,要找的数字[%s]不在列表里" % find_num) binary_search(data,66)
协程函数
协程函数就是使用了yield表达式形式的生成器
def eater(name): print("%s eat food" %name) while True: food = yield print("done") g = eater("gangdan") print(g)
结果:
<generator object eater at 0x0000026AFE4968E0>
这里就证明了g现在就是生成器函数
1. 2 协程函数赋值过程
用的是yield的表达式形式
要先运行next(),让函数初始化并停在yield,相当于初始化函数,然后再send() ,send会给yield传一个值
** next()和send() 都是让函数在上次暂停的位置继续运行,
next是让函数初始化
send在触发下一次代码的执行时,会给yield赋值
def eater(name): print('%s start to eat food' %name) food_list=[] while True: food=yield food_list print('%s get %s ,to start eat' %(name,food)) food_list.append(food) e=eater('钢蛋') # wrapper('') # print(e) print(next(e)) # 现在是运行函数,让函数初始化 print(e.send('包子')) # print(e.send('韭菜馅包子')) print(e.send('大蒜包子'))
这里的关键是:
要先运行next()函数
用装饰器函数把next()函数先运行一次:
import os def init(func): def wrapper(*args,**kwargs): res=func(*args,**kwargs) next(res) return res return wrapper @init def search(target): while True: search_path=yield g=os.walk(search_path) for par_dir,_,files in files: for file in files: file_abs_path=r'%s\%s' %(par_dir,file) #print(file_abs_path) target.send(file_abs_path)
1.2 协程函数的应用
过滤一个文件下的子文件、字文件夹的内容中的相应的内容,在Linux中的命令就是 grep -rl 'error /dir
#grep -rl 'error' /dir/ import os def init(func): def wrapper(*args,**kwargs): g=func(*args,**kwargs) next(g) return g return wrapper #第一阶段:找到所有文件的绝对路径 @init def search(target): while True: filepath=yield g=os.walk(filepath) for pardir,_,files in g: for file in files: abspath=r'%s\%s' %(pardir,file) target.send(abspath) # search(r'C:UsersAdministratorPycharmProjectspython18期周末班day5aaa') # g=search() # g.send(r'C:Python27') #第二阶段:打开文件 @init def opener(target): while True: abspath=yield with open(abspath,'rb') as f: target.send((abspath,f)) #第三阶段:循环读出每一行内容 @init def cat(target): while True: abspath,f=yield #(abspath,f) for line in f: res=target.send((abspath,line)) if res:break #第四阶段:过滤 @init def grep(pattern,target): tag=False while True: abspath,line=yield tag tag=False if pattern in line: target.send(abspath) tag=True #第五阶段:打印该行属于的文件名 @init def printer(): while True: abspath=yield print(abspath) g = search(opener(cat(grep('os'.encode('utf-8'), printer())))) # g.send(r'C:UsersAdministratorPycharmProjectspython18期周末班day5aaa') g.send(r'C:UsersAdministratorPycharmProjectspython18期周末班') #a1.txt,a2.txt,b1.txt
面向过程的编程思想:流水线式的编程思想,在设计程序时,需要把整个流程设计出来
优点:
1:体系结构更加清晰
2:简化程序的复杂度
缺点:
1:可扩展性极其的差,所以说面向过程的应用场景是:不需要经常变化的软件,如:linux内核,httpd,git等软件
模块
1,什么是模块(python里叫模块,其它叫类库)?
一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀
1 使用python编写的代码(.py文件)
2 已被编译为共享库或DLL的C或C++扩展
3 包好一组模块的包
4 使用C编写并链接到python解释器的内置模块
类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合。而对于一个复杂的功能来,可能需要多个函数才能完成(函数又可以在不同的.py文件中),n个 .py 文件组成的代码集合就称为模块。
2,为何要使用模块?
如果你退出python解释器然后重新进入,那么你之前定义的函数或者变量都将丢失,因此我们通常将程序写到文件中以便永久保存下来,需要时就通过python test.py方式去执行,此时test.py被称为脚本script。
随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结构更清晰,方便管理,这时我们不仅仅可以把这些文件当作脚本去执行,还可以把他们当作模块来导入到其他的模块中,实现了功能的重复利用。
示例文件:spam.py,文件名spam.py,模块名spam
1 #spam.py 2 print('from the spam.py') 3 4 money=1000 5 6 def read1(): 7 print('spam->read1->money',money) 8 9 def read2(): 10 print('spam->read2 calling read') 11 read1() 12 13 def change(): 14 global money 15 money=0
模块分三种:
自定义模块
内置模块
第三方模块
安装:pip3
源码
自定义模块
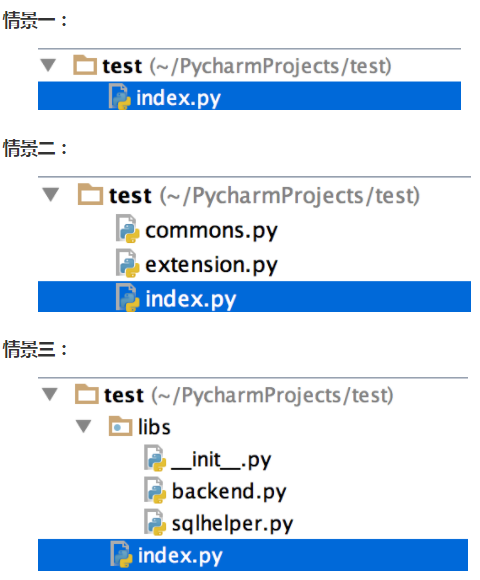
内置模块是Python自带的功能,在使用内置模块相应的功能时,需要【先导入】再【使用】
import
模块可以包含可执行的语句和函数的定义,这些语句的目的是初始化模块,它们只在模块名第一次遇到导入import语句时才执行(import语句是可以在程序中的任意位置使用的,且针对同一个模块很import多次,为了防止你重复导入,python的优化手段是:第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载大内存中的模块对象增加了一次引用,不会重新执行模块内的语句)如下:
import spam #只在第一次导入时才执行spam.py内代码,此处的显式效果是只打印一次'from the spam.py',当然其他的顶级代码也都被执行了,只不过没有显示效果. import spam import spam import spam ''' 执行结果: from the spam.py
导入模块
Python之所以应用越来越广泛,在一定程度上也依赖于其为程序员提供了大量的模块以供使用,如果想要使用模块,则需要导入(导入模块其实就是告诉Python解释器去解释那个py文件)导入模块有一下几种方法:
1,import module 2,from module.xx.xx import xx 3,from module.xx.xx import xx as rename (为模块名起别名,相当于rename=r)
3,1 as示范用法
if file_format == 'xml': import xmlreader as reader elif file_format == 'csv': import csvreader as reader data=reader.read_date(filename)
4,from module.xx.xx import *
在一行导入多个模块
import sys,os,re
我们可以从sys.module中找到当前已经加载的模块,sys.module是一个字典,内部包含模块名与模块对象的映射,该字典决定了导入模块时是否需要重新导入。
导入模块其实就是告诉Python解释器去解释那个py文件
- 导入一个py文件,解释器解释该py文件
- 导入一个包,解释器解释该包下的 __init__.py 文件 【py2.7】
那么问题来了,导入模块时是根据那个路径作为基准来进行的呢?即:sys.path
import sys print(sys.path) 结果: ['C:\Users\Administrator\PycharmProjects\python18\day5', 'C:\Users\Administrator\PycharmProjects\python18', 'C:\Users\Administrator\AppData\Local\Programs\Python\Python36\python36.zip', 'C:\Users\Administrator\AppData\Local\Programs\Python\Python36\DLLs', 'C:\Users\Administrator\AppData\Local\Programs\Python\Python36\lib', 'C:\Users\Administrator\AppData\Local\Programs\Python\Python36', 'C:\Users\Administrator\AppData\Local\Programs\Python\Python36\lib\site-packages']
如果sys.path路径列表没有你想要的路径,可以通过 sys.path.append('路径') 添加。
import sys import os project_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(project_path)
导入模块干的事:
1,产生新的名称空间
2,以新建的名称空间为全局名称空间,执行文件的代码
3,拿到一个模块名spam,指向spam.py产生的名称空间
每个模块都是一个独立的名称空间,定义在这个模块中的函数,把这个模块的名称空间当做全局名称空间,这样我们在编写自己的模块时,就不用担心我们定义在自己模块中全局变量会在被导入时,与使用者的全局变量冲突
money与spam.money不冲突 2 #test.py 3 import spam 4 money=10 5 print(spam.money) 6 7 ''' 8 执行结果: 9 from the spam.py 10 1000 11 '''
from......import......
对比import spam,会将源文件的名称空间'spam'带到当前名称空间中,使用时必须是spam.名字的方式
而from 语句相当于import,也会创建新的名称空间,但是将spam中的名字直接导入到当前的名称空间中,在当前名称空间中,直接使用名字就可以了、
需要注意的是from后import导入的模块,必须是明确的一个不能带点,否则会有语法错误,如:from a import b.c是错误语法
from spam import read1,read2
这样在当前位置直接使用read1和read2就好了,执行时,仍然以spam.py文件全局名称空间
#测试一:导入的函数read1,执行时仍然回到spam.py中寻找全局变量money #test.py from spam import read1 money=1000 read1() ''' 执行结果: from the spam.py spam->read1->money 1000 ''' #测试二:导入的函数read2,执行时需要调用read1(),仍然回到spam.py中找read1() #test.py from spam import read2 def read1(): print('==========') read2() ''' 执行结果: from the spam.py spam->read2 calling read spam->read1->money 1000 '''
如果当前有重名read1或者read2,那么会有覆盖效果。
1 from spam import money,read1 2 money=100 #将当前位置的名字money绑定到了100 3 print(money) #打印当前的名字 4 read1() #读取spam.py中的名字money,仍然为1000 5 6 ''' 7 from the spam.py 8 100 9 spam->read1->money 1000 10 '''
也支持as
from spam import read1 as read
也支持导入多行
1 from spam import (read1, 2 read2, 3 money)
from spam import * 把spam中所有的不是以下划线(_)开头的名字都导入到当前位置,大部分情况下我们的python程序不应该使用这种导入方式,因为*你不知道你导入什么名字,很有可能会覆盖掉你之前已经定义的名字。而且可读性极其的差,在交互式环境中导入时没有问题。
可以使用__all__来控制*(用来发布新版本)
在spam.py中新增一行
__all__=['money','read1'] #这样在另外一个文件中用from spam import *就这能导入列表中规定的两个名字
如果spam.py中的名字前加_,即_money,则from spam import *,则_money不能被导入
把模块当做脚本执行
我们可以通过模块的全局变量__name__来查看模块名:
当做脚本运行:
__name__ 等于'__main__'(系统的内置变量)
当做模块导入:
__name__=
作用:用来控制.py文件在不同的应用场景下执行不同的逻辑
if __name__ == '__main__':
模块搜索路径
python解释器在启动时会自动加载一些模块,可以使用sys.modules查看
在第一次导入某个模块时(比如spam),会先检查该模块是否已经被加载到内存中(当前执行文件的名称空间对应的内存),如果有则直接引用
如果没有,解释器则会查找同名的内建模块,如果还没有找到就从sys.path给出的目录列表中依次寻找spam.py文件。
所以总结模块的查找顺序是:内存中已经加载的模块->内置模块->sys.path路径中包含的模块
搜索路径: 当一个命名为spam的模块被导入时 解释器首先会从内建模块中寻找该名字 找不到,则去sys.path中找该名字 sys.path从以下位置初始化 1 执行文件所在的当前目录 2 PTYHONPATH(包含一系列目录名,与shell变量PATH语法一样) 3 依赖安装时默认指定的 注意:在支持软连接的文件系统中,执行脚本所在的目录是在软连接之后被计算的,换句话说,包含软连接的目录不会被添加到模块的搜索路径中 在初始化后,我们也可以在python程序中修改sys.path,执行文件所在的路径默认是sys.path的第一个目录,在所有标准库路径的前面。这意味着,当前目录是优先于标准库目录的,需要强调的是:我们自定义的模块名不要跟python标准库的模块名重复,除非你是故意的,傻叉。
编译python模块
为了提高加载模块的速度,强调强调强调:提高的是加载速度而绝非运行速度。python解释器会在__pycache__目录中下缓存每个模块编译后的版本,格式为:module.version.pyc。通常会包含python的版本号。例如,在CPython3.3版本下,spam.py模块会被缓存成__pycache__/spam.cpython-33.pyc。这种命名规范保证了编译后的结果多版本共存。
Python检查源文件的修改时间与编译的版本进行对比,如果过期就需要重新编译。这是完全自动的过程。并且编译的模块是平台独立的,所以相同的库可以在不同的架构的系统之间共享,即pyc使一种跨平台的字节码,类似于JAVA火.NET,是由python虚拟机来执行的,但是pyc的内容跟python的版本相关,不同的版本编译后的pyc文件不同,2.5编译的pyc文件不能到3.5上执行,并且pyc文件是可以反编译的,因而它的出现仅仅是用来提升模块的加载速度的。
python解释器在以下两种情况下不检测缓存
1 如果是在命令行中被直接导入模块,则按照这种方式,每次导入都会重新编译,并且不会存储编译后的结果(python3.3以前的版本应该是这样)
2 如果源文件不存在,那么缓存的结果也不会被使用,如果想在没有源文件的情况下来使用编译后的结果,则编译后的结果必须在源目录下
提示:
1.模块名区分大小写,foo.py与FOO.py代表的是两个模块
2.你可以使用-O或者-OO转换python命令来减少编译模块的大小
1 -O转换会帮你去掉assert语句 2 -OO转换会帮你去掉assert语句和__doc__文档字符串 3 由于一些程序可能依赖于assert语句或文档字符串,你应该在在确认需要的情况下使用这些选项。
3.在速度上从.pyc文件中读指令来执行不会比从.py文件中读指令执行更快,只有在模块被加载时,.pyc文件才是更快的
4.只有使用import语句是才将文件自动编译为.pyc文件,在命令行或标准输入中指定运行脚本则不会生成这类文件,因而我们可以使用compieall模块为一个目录中的所有模块创建.pyc文件
1 模块可以作为一个脚本(使用python -m compileall)编译Python源 2 3 python -m compileall /module_directory 递归着编译 4 如果使用python -O -m compileall /module_directory -l则只一层 5 6 命令行里使用compile()函数时,自动使用python -O -m compileall 7 8 详见:https://docs.python.org/3/library/compileall.html#module-compileall
dir函数
内建函数dir是用来查找模块中定义的名字,返回一个有序字符串列表
import spam
dir(spam)
如果没有参数,dir()列举出当前定义的名字
dir()不会列举出内建函数或者变量的名字,它们都被定义到了标准模块builtin中,可以列举出它们,
import builtins
dir(builtins)
一,sys
用于提供对Python解释器相关的操作:
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdin 输入相关
sys.stdout 输出相关
sys.stderror 错误相关
二、os 用于提供系统级别的操作(提供对操作系统进行调用的借口)
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.curdir 返回当前目录: ('.') os.pardir 获取当前目录的父目录字符串名:('..') os.makedirs('dir1/dir2') 可生成多层递归目录 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","new") 重命名文件/目录 os.stat('path/filename') 获取文件/目录信息 os.sep 操作系统特定的路径分隔符,win下为"\",Linux下为"/" os.linesep 当前平台使用的行终止符,win下为" ",Linux下为" " os.pathsep 用于分割文件路径的字符串 os.name 字符串指示当前使用平台。win->'nt'; Linux->'posix' os.system("bash command") 运行shell命令,直接显示 os.environ 获取系统环境变量 os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
2,包是目录级的(文件夹级),文件夹是用来组成py文件(包的本质就是一个包含__init__.py文件的目录)
3,import导入文件时,产生名称空间中的名字来源于文件,import包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件
强调:
1. 在python3中,即使包下没有__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包报错
2. 创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包即模块
注意事项
1.关于包相关的导入语句也分为import和from ... import ...两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如item.subitem.subsubitem,但都必须遵循这个原则。
2.对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。
3.对比import item 和from item import name的应用场景:
如果我们想直接使用name那必须使用后者。
绝对导入和相对导入
我们的最顶级包glance是写给别人用的,然后在glance包内部也会有彼此之间互相导入的需求,这时候就有绝对导入和相对导入两种方式:
绝对导入:以glance作为起始
相对导入:用.或者..的方式最为起始(只能在一个包中使用,不能用于不同目录内)
1 在glance/api/version.py 2 3 #绝对导入 4 from glance.cmd import manage 5 manage.main() 6 7 #相对导入 8 from ..cmd import manage 9 manage.main()
测试结果:注意一定要在于glance同级的文件中测试
from glance.api import versions
注意:在使用pycharm时,有的情况会为你多做一些事情,这是软件相关的东西,会影响你对模块导入的理解,因而在测试时,一定要回到命令行去执行,模拟我们生产环境,你总不能拿着pycharm去上线代码吧!!!
特别需要注意的是:可以用import导入内置或者第三方模块(已经在sys.path中),但是要绝对避免使用import来导入自定义包的子模块(没有在sys.path中),应该使用from... import ...的绝对或者相对导入,且包的相对导入只能用from的形式。
软件开发规范
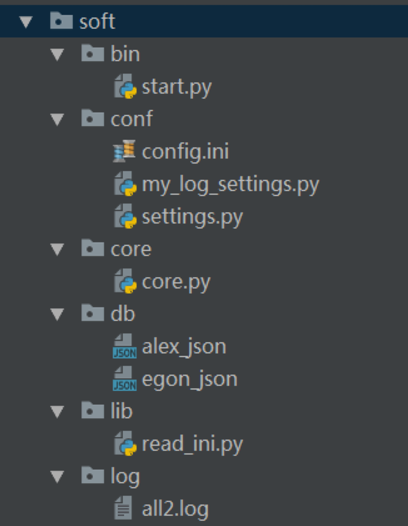
logging日志(日志处理之logging模块)
日志级别:
debug 最详细的调试信息 10
info 就想记录一下 20
warning 出现警告 30
error 出现错误 40
crttcal 非常严重 50
从大至小,级别越高,数字越大!
日志格式
|
%(name)s |
Logger的名字 |
|
%(levelno)s |
数字形式的日志级别 |
|
%(levelname)s |
文本形式的日志级别 |
|
%(pathname)s |
谁调用日志输出该函数的模块的完整路径名,可能没有 |
|
%(filename)s |
谁调用日志输出该函数的模块的文件名(aa.py) |
|
%(module)s |
谁调用日志输出该函数的模块名(aa) |
|
%(funcName)s |
谁调用日志输出该函数的函数名 |
|
%(lineno)d |
谁调用日志输出该函数的语句所在的代码行 |
|
%(created)f |
当前时间,用UNIX标准的表示时间的浮 点数表示 |
|
%(relativeCreated)d |
输出日志信息时的,自Logger创建以 来的毫秒数 |
|
%(asctime)s |
字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 |
|
%(thread)d |
线程ID。可能没有 |
|
%(threadName)s |
线程名。可能没有 |
|
%(process)d |
进程ID。可能没有 |
|
%(message)s |
用户输出的消息 |
Python 使用logging模块记录日志涉及四个主要类,使用官方文档中的概括最为合适:
logger提供了应用程序可以直接使用的接口;
handler将(logger创建的)日志记录发送到合适的目的输出(输出到文件内或屏幕)
filter提供了细度设备来决定输出哪条日志记录(日志内容哪些输出,哪些不输出)
formatter决定日志记录的最终输出格式(日志格式)
logger 每个程序在输出信息之前都要获得一个Logger。Logger通常对应了程序的模块名,比如聊天工具的图形界面模块可以这样获得它的Logger: LOG=logging.getLogger(”chat.gui”) 而核心模块可以这样: LOG=logging.getLogger(”chat.kernel”) Logger.setLevel(lel):指定最低的日志级别,低于lel的级别将被忽略。debug是最低的内置级别,critical为最高 Logger.addFilter(filt)、Logger.removeFilter(filt):添加或删除指定的filter Logger.addHandler(hdlr)、Logger.removeHandler(hdlr):增加或删除指定的handler Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical():可以设置的日志级别
handler
handler对象负责发送相关的信息到指定目的地。Python的日志系统有多种Handler可以使用。有些Handler可以把信息输出到控制台,有些Logger可以把信息输出到文件,还有些 Handler可以把信息发送到网络上。如果觉得不够用,还可以编写自己的Handler。可以通过addHandler()方法添加多个多handler Handler.setLevel(lel):指定被处理的信息级别,低于lel级别的信息将被忽略 Handler.setFormatter():给这个handler选择一个格式 Handler.addFilter(filt)、Handler.removeFilter(filt):新增或删除一个filter对象 每个Logger可以附加多个Handler。接下来我们就来介绍一些常用的Handler: 1) logging.StreamHandler 使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息。它的构造函数是: StreamHandler([strm]) 其中strm参数是一个文件对象。默认是sys.stderr 2) logging.FileHandler 和StreamHandler类似,用于向一个文件输出日志信息。不过FileHandler会帮你打开这个文件。它的构造函数是: FileHandler(filename[,mode]) filename是文件名,必须指定一个文件名。 mode是文件的打开方式。参见Python内置函数open()的用法。默认是’a',即添加到文件末尾。 3) logging.handlers.RotatingFileHandler 这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建 一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把 文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建 chat.log,继续输出日志信息。它的构造函数是: RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]]) 其中filename和mode两个参数和FileHandler一样。 maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。 backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。 4) logging.handlers.TimedRotatingFileHandler 这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就 自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。它的构造函数是: TimedRotatingFileHandler( filename [,when [,interval [,backupCount]]]) 其中filename参数和backupCount参数和RotatingFileHandler具有相同的意义。 interval是时间间隔。
when参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值:
S 秒
M 分
H 小时
D 天
W 每星期(interval==0时代表星期一)
midnight 每天凌晨
import logging logging.basicConfig(filename='example.log', level=logging.WARNING, format='%(asctime)s %(message)s', datefmt='%m/%d/%Y %H:%M:%S %p') #filename='example.log' 指定写入日志文件 #level=logging.WARNING(日志级别必须大写),日志级别达到WARNING级别写入db文件(文件默认生成) #format='%(asctime)s %(message)s'日志格式, asctime当前时间, message当前内容 #datefmt='%m/%d/%Y %H:%M:%S %p' 日期格式logging.debug('This message should go to the log file') logging.info('So should this') logging.warning('And this, too') logging.error("wrong password more than 3 times") logging.critical("server is down") #db文件显示 31/07/2017 14:01:54 AM And this, too06/07/2017 01:01:54 AM wrong password more than 3 times 31/07/2017 14:01:54 AM server is down
日志模式输入到全局日志,db日志文件,终端
import logging#日志输入到全局日志,db日志文件 终端 logger = logging.getLogger('TEST-LOG') #TEST-LOG是日志名 logger.setLevel(logging.DEBUG) #logging.DEBUG 全局的日志级别 # 全局日志基本最高,子logging基本必须比全局高 否则不显示日志输出 ch = logging.StreamHandler() #创建屏幕输出显示 ch.setLevel(logging.INFO) #屏幕输出日志级别 fh = logging.FileHandler("access.log") #文件的hander fh.setLevel(logging.WARNING) #文件的日志级别 formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') ch.setFormatter(formatter) #定义日志格式 fh.setFormatter(formatter) #定义日志格式 logger.addHandler(ch) #屏幕输出绑定到logger接口 logger.addHandler(fh) #文件输出绑定到logger接口#应用程序代码 logger.debug('debug message') logger.info('info message') logger.warning('warn message') logger.error('error message') logger.critical('critical message')
日志输入到全局日志,db日志文件 屏幕 并按照时间切割保留最近3个db文件,每5秒切割1次
import logging from logging import handlers #创建db文件日志切割,不加切割不用写 #日志输入到全局日志,db日志文件 屏幕 并安装时间日志切割保留最近3个文件,每5秒切割1次 logger = logging.getLogger('TEST-LOG') #TEST-LOG是日志名 logger.setLevel(logging.DEBUG) #logging.DEBUG 全局的日志级别
# 全局日志基本最高,子logging基本必须比全局高 否则不显示日志输出 ch = logging.StreamHandler() #创建屏幕输出显示 ch.setLevel(logging.INFO) #屏幕输出日志级别 #fh = logging.FileHandler("access.log") #文件显示(db文件保存日志) 不加日志切割用这个 fh = handlers.TimedRotatingFileHandler("access.log",when="S",interval=5,backupCount=3) #文件显示(db文件保存日志) #TimedRotatingFileHandler 按时间切割保存, when="S",单位是秒(h是小时), interval=5,(5个单位切1次)backupCount=3 (保存最近3次,0是无限制保存) #fh = handlers.RotatingFileHandler("access.log",maxBytes=4,backupCount=3) #RotatingFileHandler 按时间切割保存 maxBytes=4 (文件满4bytes,就生成新文件) backupCount=3 (保存最近3次,0是无限制保存) fh.setLevel(logging.WARNING) #文件的日志级别 formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') ch.setFormatter(formatter) #定义日志格式 fh.setFormatter(formatter) #定义日志格式 logger.addHandler(ch) #屏幕输出绑定到logger接口 logger.addHandler(fh) #文件输出绑定到logger接口 # 应用程序代码 logger.debug('debug message') logger.info('info message') logger.warning('warn message') logger.error('error message') logger.critical('critical message')