01-爬虫介绍
1. 什么是爬虫
网络爬虫是一种按照一定的规则,自动地抓网络信息的程序或者脚本。
2. 爬虫分类
1- 通用爬虫:
通用爬虫是搜索引擎(Baidu、Google、Yahoo等)“抓取系统”的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。简单来讲就是尽可能的;把互联网上的所有的网页下载下来,放到本地服务器里形成备分,在对这些网页做相关处理(提取关键字、去掉广告),最后提供一个用户检索接口。
搜索引擎如何抓取互联网上的网站数据?
门户网站主动向搜索引擎公司提供其网站的url
搜索引擎公司与DNS服务商合作,获取网站的url
门户网站主动挂靠在一些知名网站的友情链接中
2- 聚焦爬虫:
聚焦爬虫是根据指定的需求抓取网络上指定的数据。例如:获取豆瓣上电影的名称和影评,而不是获取整张页面中所有的数据值。
3- 增量爬虫:
通过检测网站数据更新的情况,将最新更新出来的数据进行爬取
3. 爬虫的基本流程
1- 发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
2- 获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3- 解析内容
解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据: 以b的方式写入文件
4- 保存数据
数据库
文件
4. HTTP协议介绍
HTTP协议(HyperText Transfer Protocol,超文本传输协议)是因特网上应用最为广泛的一种网络传输协议,所有的WWW文件都必须遵守这个标准。
HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
TCP/IP协议采取分层管理,下图为HTTP协议的通信传输流
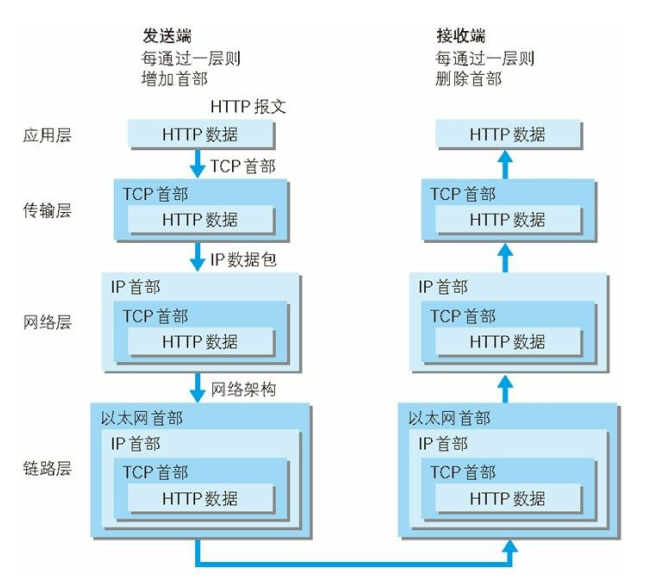
HTTP协议通过请求和响应的交换达成通信
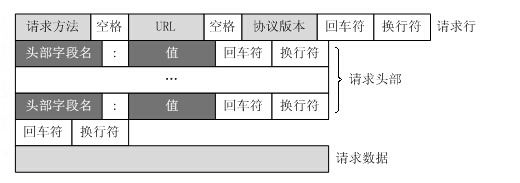
HTTP请求格式
HTTP响应格式