一.索引介绍
1.什么是索引
1)索引就好比一本书的目录,它能让你更快的找到自己想要的内容。
2)让获取的数据更有目的性,从而提高数据库检索数据的性能。
2.索引类型介绍
1)BTREE:B+树索引 ( Btree B+tree B*tree)
2)HASH:HASH索引 (hash key)
3)FULLTEXT:全文索引
4)RTREE:R树索引
1.Btree :

2.Btree索引(优化了查询范围,在叶子节点添加了相邻节点的指针)

3·B*tree索引(在枝节点添加了指针)
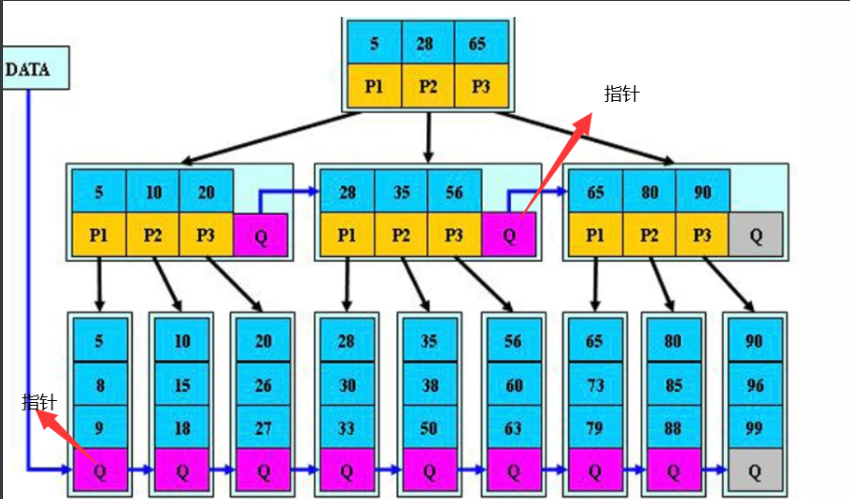
3.索引管理
索引建立在表的列上(字段)的。
在where后面的列建立索引才会加快查询速度。
pages<---索引(属性)<----查数据。
- 1、索引分类:
主键索引(primary key)
普通索引 ( key)
唯一索引(unique key)
- 2、添加索引:
4.实例(参考)
CREATE TABLE `test_table` (
`ID` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`DOMAIN_CODE` varchar(20) NOT NULL COMMENT '考试单位编号',
`EXAM_NAME` varchar(300) NOT NULL COMMENT '考试名称',
`EXAM_TYPE` int(1) NOT NULL COMMENT '考试类型(正式考试,补考)',
`TARGET_EXAM_ID` bigint(20) DEFAULT NULL COMMENT '关联正式考试的ID(如果是补考,该处是必填)',
`EXAM_PICTURE_PATH` varchar(100) DEFAULT NULL COMMENT '图示路径',
`EXAM_BEGIN_TIME` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '考试开始时间',
`EXAM_END_TIME` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '考试结束时间',
`EXAM_TIME` int(3) NOT NULL COMMENT '考试时长',
`EXAM_NEED_SCORE` int(5) NOT NULL COMMENT '考试所需积分',
`EXAM_PAPER_TYPE` int(1) DEFAULT NULL COMMENT '考试试卷类型(0固定、1随机)',
`EXAM_SCORE` double(6,2) DEFAULT NULL COMMENT '考试总分(关联试卷后回填)',
`EXAM_PASS_SCORE` double(6,2) NOT NULL COMMENT '考试及格分',
`EXAM_COMMIT_NUM` int(2) NOT NULL COMMENT '参考最大次数',
`EXAM_STATUS` int(1) NOT NULL COMMENT '发布状态0未发布,1已发布',
`EXAM_YEAR` varchar(5) NOT NULL COMMENT '年份',
`EXAM_PAPER_ID` bigint(20) DEFAULT NULL COMMENT '关联试卷ID',
`EXAM_DISCRIPTION` varchar(1000) DEFAULT NULL COMMENT '考试备注',
`OPERATOR_USER_ACCOUNT` varchar(20) NOT NULL COMMENT '修改人',
`OPERATOR_TIME` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '修改时间',
`TARGET_DOMAIN_CODE` varchar(20) DEFAULT NULL COMMENT '发布目标单位编号(发布时回填)',
`RANK` varchar(100) DEFAULT NULL COMMENT '职务级别(发布时回填)',
`EXAM_DIPLOMA_ID` bigint(20) DEFAULT NULL COMMENT '关联证书',
`DIPLOMA_NAME` varchar(200) DEFAULT NULL COMMENT '证书标题(关联证书后回填',
`DIPLOMA_PICTURE_PATH` varchar(200) DEFAULT NULL COMMENT '证书背景图片保存位置(关联证书后回填)',
`INDUSTRY_CODES` varchar(1000) DEFAULT NULL,
`LANGUAGE` int(2) NOT NULL DEFAULT '1' COMMENT 'è¯è¨€ï¼ˆ0:全部,1:汉è¯,2:ç»´è¯,3:è’è¯,4:哈è¯ï¼‰',
`EXT1` int(1) NOT NULL DEFAULT '1' COMMENT '成绩计入学分的字段标识(0 是,1否)',
`EXT2` int(3) DEFAULT NULL COMMENT '成绩所占比例',
`EXT3` varchar(1) DEFAULT NULL,
`EXT4` varchar(1) DEFAULT NULL,
`EXT5` varchar(1) DEFAULT NULL,
#索引
PRIMARY KEY (`ID`),
KEY `DOMAIN_CODE` (`DOMAIN_CODE`),
KEY `EXAM_PAPER_ID` (`EXAM_PAPER_ID`)
) ENGINE=InnoDB AUTO_INCREMENT=365 DEFAULT CHARSET=utf8;
5.索引操作
#创建普通索引
mysql> alter table student4 add index idx_sname(sname);
#创建主键索引
mysql> alter table st add primary key pri_id(id);
#创建索引
create index index_name on test(name);
#删除索引
alter table test drop key index_name;
# 如何判断,该列是否能创建唯一键
#统计行数
mysql> select count(sgender) from student2;
#统计去重后的行数
mysql> select count(distinct(sgender)) from student2;
#添加唯一性索引
alter table student add unique key uni_xxx(xxx);
#查看表中数据行数
select count(*) from city;
#查看去重数据行数
select count(distinct name) from city;
#查看索引三种方式
mysql> desc student4;
mysql> show index from student4;
mysql> show create table student4;


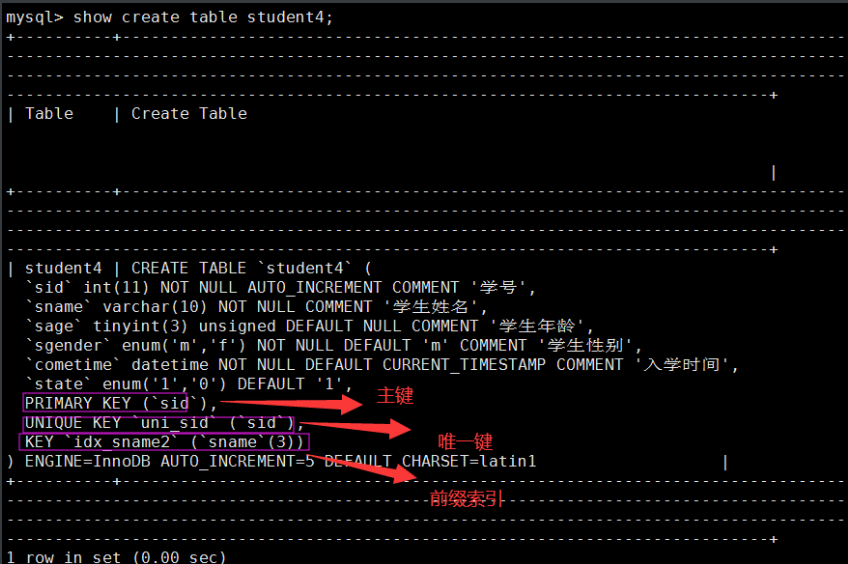
6.前缀索引
根据字段的前N个字符建立索引
#创建前缀索引
mysql> alter table student2 add index idx_sname2(sname(3));
1.避免对大列 建索引
2.如果有,就使用前缀索引
7.联合索引
多个字段建立一个索引
例:
where a.女生 and b.身高 and c.体重 and d.身材好
index(a,b,c)
特点:前缀生效特性
a,ab,ac,abc,abcd 可以走索引或部分走索引
b bc bcd cd c d ba ... 不走索引
原则:把最常用来做为条件查询的列放在最前面
例如:想亲网站 sex money body age hight weight face name phone QQ wechat
会一般把sex 性别放在第一位。
#创建people表
create table xiangqin( id, name varchar(10), age int, money bigint, body varchar(10), hight int, weight int, face varchar(10), phone varchar(11), sex enum('f','m'));
#创建联合索引
mysql> alter table xiangqin add index idx_all(sex,money,body,face);
insert into xiangqin values('ly',30,999999999,'perfact',158,90,'nice','133','f'), ('qbl',58,1000000,'bad',150,150,'very bad','000','f'), ('wbq',50,9999999,'suibian',170,120,'suiyi',132,'m');
#查询
走索引
mysql> select * from xiangqin where sex='f' and money>10000000 and body='perfact' and face='nice';
不走索引
mysql> select * from xiangqin where money>10000000 and body='perfact' and face='nice'; mysql> select * from xiangqin where money>10000000 and body='perfact' and face='nice' and sex='f';
8.创建索引总结:
1.不要在所有字段上都创建索引
2.如果有需求字段比较多,选择联合索引
3.如果有需求字段数据比较大,选择前缀索引
**4.如果可以创建唯一索引,一定创建唯一索引 **