一、group_concat函数的功能
将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
group_concat函数首先根据group by指定的列进行分组,将同一组的列显示出来,并且用分隔符分隔。由函数参数(字段名)决定要返回的列。例如:
create table emp(
emp_id int primary key auto_increment comment '编号',
emp_name char(20) not null default '' comment '姓名',
salary decimal(10,2) not null default 0 comment '工资',
department char(20) not null default '' comment '部门'
);
insert into emp(emp_name,salary,department)
values('张晶晶',5000,'财务部'),('王飞飞',5800,'财务部'),('赵刚',6200,'财务部'),('刘小贝',5700,'人事部'),
('王大鹏',6700,'人事部'),('张小斐',5200,'人事部'),('刘云云',7500,'销售部'),('刘云鹏',7200,'销售部'),
('刘云鹏',7800,'销售部');
执行如下查询及结果:
select group_concat(emp_name) from emp;
+----------------------------------------------------------------------------------------+
| group_concat(emp_name) |
+----------------------------------------------------------------------------------------+
| 张晶晶,王飞飞,赵刚,刘小贝,王大鹏,张小斐,刘云云,刘云鹏,刘云鹏 |
+----------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> select department,group_concat(emp_name) from emp group by department;
+------------+-------------------------------+
| department | group_concat(emp_name) |
+------------+-------------------------------+
| 人事部 | 刘小贝,王大鹏,张小斐 |
| 财务部 | 张晶晶,王飞飞,赵刚 |
| 销售部 | 刘云云,刘云鹏,刘云鹏 |
+------------+-------------------------------+
3 rows in set (0.00 sec)
二、函数语法:
group_concat( [DISTINCT] 要连接的字段 [Order BY 排序字段 ASC/DESC] [Separator ‘分隔符’] )
group_concat([distinct] 字段名 [order by 排序字段 asc/desc] [separator '分隔符'])
说明:
(1)使用distinct可以排除重复值;
(2)如果需要对结果中的值进行排序,可以使用order by子句;
(3)separator是一个字符串值,默认为逗号。
下面举例说明:select id,price from goods;
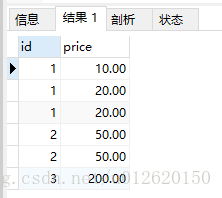
以id分组,把price字段的值在同一行打印出来,逗号分隔(默认):select id, group_concat(price) from goods group by id;
以id分组,把price字段的值在一行打印出来,分号分隔:select id,group_concat(price separator ';') from goods group by id;

以id分组,把去除重复冗余的price字段的值打印在一行,逗号分隔:select id,group_concat(distinct price) from goods group by id;

以id分组,把price字段的值去重打印在一行,逗号分隔,按照price倒序排列:select id,group_concat(DISTINCT price order by price desc) from goods group by id;

三、示例代码
select t1.foodId, t2.name, sum(t1.foodNum) as foodsNum, GROUP_CONCAT(t3.orderCode order by t3.orderCode desc SEPARATOR ',') orderlist
from foods_order t1, foods_info t2, order_info t3
where t1.orderId = t3.id and t1.foodId = t2.id
and t3.createTime >= '2020-11-07 00:00:00' and t3.createTime <= '2020-11-07 18:30:00'
and t3.orderState in ('2','3','4','5')
group by t1.foodId, t2.name
其中2个方法:sum():取某字段的总数;group_concat:就是上面介绍的用法
