背景交代
团队做大学英语四六级考试相关服务。业务中有一个care服务,购买了care服务考试不过可以全额退款,不过有一个前提是要完成care服务的任务,比如坚持背单词N天,完成指定的试卷。
在这个背景下,接到一个需求,需求本身比较复杂,简化出与本篇主题相关的需求是:当2021年6月的四六级考试完成之后,要统计出两种用户数据:
- 完成care服务的用户
- 没有完成care的用户
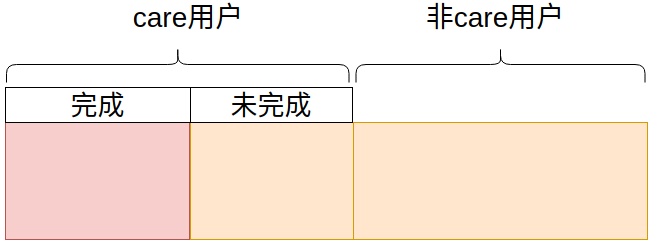
所以简化的逻辑就是要在所有的用户中区分出care完成用户和care未完成用户。
- 目标1:完成care服务
- 目标2:未完成care服务
所有目标用户的数量在2.7w左右,care完成用户在0.4w左右。所以我需要做的是在从数据库中查询出的 2.7w 所有用户,去另一个表区分出care完成用户和care未完成用户。
说明: 需求本身逻辑有点绕,为了能让读者看明白就最大程度的做了简化,所以看起来就是一个简单的数据库查询问题。同时数据库多表操作首选是连表操作,当时做需求因为逻辑比较复杂并没有想到。感谢读者212的s提醒,我接受批评。所以将本篇当着python数据结构使用来看就可以,数据库查询优化水很深,显然我没把握住。
第一版
第一版:纯粹使用数据库查询。首先查询出所有目标,然后遍历所有用户,在遍历中使用user id从另一张表中查询出care完成用户。
总量在2.7w 左右,所以数据库就查询了2.7w次。
耗时统计:144.7 s
def remind_repurchase():
# 查询出所有用户
all_users = cm.UserPlan.select().where(cm.UserPlan.plan_id.in_([15, 16]))
plan_15_16_not_refund_users = []
plan_15_16_can_refund_users = []
for user in all_users:
# 从另一张表查询用户是否完成care
user_insurance = cm.UserInsurance.select().where(
cm.UserInsurance.user_id == user.user_id,
cm.UserInsurance.plan_id == user.plan_id,
cm.UserInsurance.status == cm.UserInsurance.STATUS_SUCCESS,
)
# care 完成
if len(user_insurance) == 1:
# 其他逻辑
plan_15_16_can_refund_users.append(user.user_id)
else:
# care未完成用户
plan_15_16_not_refund_users.append(user.user_id)
使用数据查询是能想到的最直接的方法,但是主要的耗时操作就在for循环查询数据库。这种耗时肯定是不被允许的,需要提高效率。
第二版
优化点:增加事务
第二版优化思路:对于 2.7w 次的数据库库查询肯定会有 2.7w 次建立连接、事务、查询语句转SQL等。2.7w次的开销也是一个极大的数字。理所当然的想到了减少事务的开销。将所有的数据库查询都放在一个事务中完成,就能够有效减少查询带来的耗时。
耗时统计:100.6 s
def remind_repurchase():
# 查询出所有用户
all_users = cm.UserPlan.select().where(cm.UserPlan.plan_id.in_([15, 16]))
plan_15_16_not_refund_users = []
plan_15_16_can_refund_users = []
# 增加事务
with pwdb.database.atomic():
for user in all_users:
# 从另一张表查询用户是否完成care
user_insurance = cm.UserInsurance.select().where(
cm.UserInsurance.user_id == user.user_id,
cm.UserInsurance.plan_id == user.plan_id,
cm.UserInsurance.status == cm.UserInsurance.STATUS_SUCCESS,
)
# care 完成
if len(user_insurance) == 1:
# 其他逻辑
plan_15_16_can_refund_users.append(user.user_id)
else:
# care未完成用户
plan_15_16_not_refund_users.append(user.user_id)
增加事务之后减少了44s,相当于缩短了时间30%的时间,由此可以看出事务在数据库中查询是一个比较耗时的操作。
第三版
优化点:将2.7w次的数据库查询转变成对列表的in操作。
第三版提出改进方案:原来的逻辑是循环 2.7w 次,在数据库中查询用户是否完成care服务。2.7w 次的数据库查询是耗时最长的原因,而可以改进的方法是将所有完成care服务的用户先一次性查询出来,放到一个列表中。遍历所有用户时不去查数据库,而是直接使用in操作在列表中查询。这种方法直接将 2.7w 次数据库遍历减少到1次,极大缩短了数据库查询耗时。
耗时统计:11.5 s
def remind_repurchase():
all_users = cm.UserPlan.select().where(cm.UserPlan.plan_id.in_([15, 16]))
plan_15_16_not_refund_users = []
plan_15_16_can_refund_users = []
# 所有care完成用户,先将所有用户查询出来放在一个列表中
user_insurance = cm.UserInsurance.select().where(
cm.UserInsurance.plan_id.in_([15, 16]),
cm.UserInsurance.status == cm.UserInsurance.STATUS_SUCCESS,
)
user_insurance_list = [user.user_id for user in user_insurance]
for user in all_users:
user_id = user.user_id
# care 完成
if user.user_id in user_insurance_list:
# 查分数
plan_15_16_can_refund_users.append(user_id)
else:
# care未完成用户 + 非care用户
plan_15_16_not_refund_users.append(user_id)
这一次优化的效果是非常显著的,可以看出想要提高代码效率要尽量减少数据库查询次数。
第四版
优化点:2.7w 次对列表的in操作变成对字典的in操作
在第三版中已经极大的优化了效率,但是仔细琢磨之后发现还是有提升的空间的。在第三版中 2.7w 次for循环,然后用in操作在列表中查询。众所周知python中对列表的in操作是遍历的,时间复杂度为0(n),所以效率不高,而对字典的in操作时间复杂度为常数级别0(1)。所以在第四版优化中先查询出的数据不保存为列表,而是保存为字典。key就是原来列表中的值,value可自定义。
耗时统计:11.42 s
def remind_repurchase():
all_users = cm.UserPlan.select().where(cm.UserPlan.plan_id.in_([15, 16]))
plan_15_16_not_refund_users = []
plan_15_16_can_refund_users = []
# 所有care完成用户,先将所有用户查询出来放在一个列表中
user_insurance = cm.UserInsurance.select().where(
cm.UserInsurance.plan_id.in_([15, 16]),
cm.UserInsurance.status == cm.UserInsurance.STATUS_SUCCESS,
)
user_insurance_dict = {user.user_id:True for user in user_insurance}
for user in all_users:
user_id = user.user_id
# care 完成
if user.user_id in user_insurance_dict:
# 查分数
plan_15_16_can_refund_users.append(user_id)
else:
# care未完成用户 + 非care用户
plan_15_16_not_refund_users.append(user_id)
由于2.7w次的in操作数据量并不是很大,并且列表的in操作在python中优化的效率也很好,所以这里的对字典的in操作并没有减少时间消耗。
第五版
优化点:将in操作转变成集合操作。
在前四版的优化下已经将耗时缩短了 133s,减少了近 92.1% 的耗时,想着这个数据看起来还不错了。隔天早上在刷牙时脑子里思绪纷飞就想到这个事情了。这时忽然想到既然我能查询全部用户,又将完成care用户的用户查询到一个列表中,这时不就是相当于两个集合吗?既然是集合,那么使用集合之间的交集和差集是不是比循环 2.7w 次要快呢?上班之后马上动手来验证这个想法。果然,还能够减少时间消耗,将第四版中的11.42 直接减少了一半,缩短到5.78,缩短近50%。
耗时统计: 5.78 s
def remind_repurchase():
all_users = cm.UserPlan.select().where(cm.UserPlan.plan_id.in_([15, 16]))
all_users_set = set([user.user_id for user in all_users])
plan_15_16_can_refund_users = []
received_user_count = 0
# 所有care完成用户
user_insurance = cm.UserInsurance.select().where(
cm.UserInsurance.plan_id.in_([15, 16]),
cm.UserInsurance.status == cm.UserInsurance.STATUS_SUCCESS,
)
user_insurance_set = set([user.user_id for user in user_insurance])
temp_can_refund_users = all_users_set.intersection(user_insurance_set)
总结
最终优化的结果:
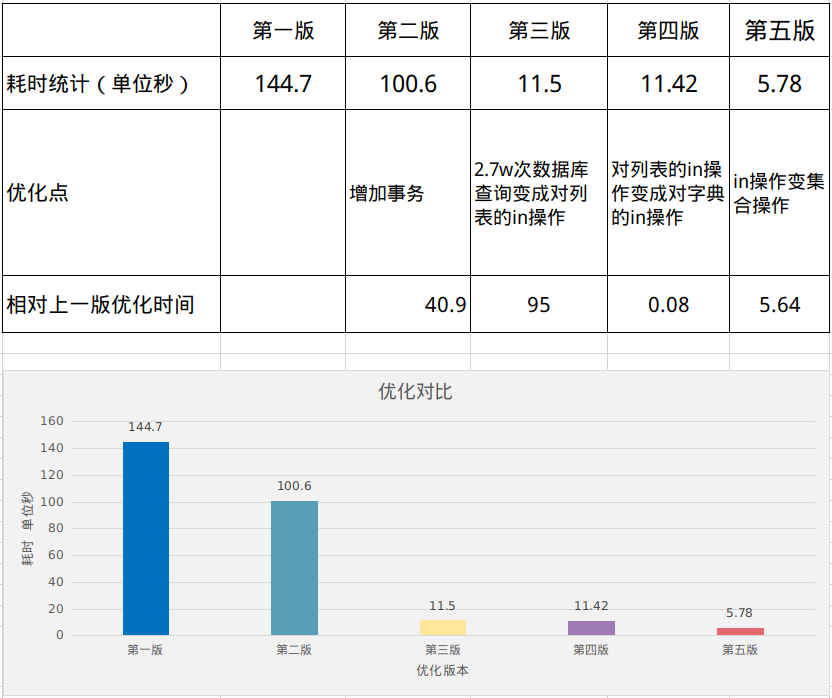
第一版耗时: 144.7 s
最后一版耗时: 5.7 s
优化时间:109 s
优化百分比:95.0%
在各个版本中的优化详细细节如下:
由此可以得出几个结论,帮助减少程序耗时:
结论一:事务不仅能够保证数据原子性,合理使用还能有效减少数据库查询耗时
结论二:集合操作的效率非常高,要善于使用集合减少循环
结论三:字典的查找效率高于列表,但是万次级别的操作无法体验优势
最后的还有一个结论:程序员的灵感似乎在刷牙、上厕所、洗澡、喝水时特别活跃,所以写不出来代码就该去摸摸鱼了。
