前言
使用数据库一个高效的操作是连表查询,一条查询语句能够查询到多个表的数据。在sqlalchem架构下的数据库连表查询更是十分方便。那么如何连表查询?以及数据库外键对连表查询有没有帮助呢?本篇文章就这两个问题简单解释。
建表
俗话说巧妇难为无米之炊,连表查询肯定要有表,有数据库啊。那有没有数据库是你见了垂涎三尺的呢?中国文化博大精深,饮食文化更是璀璨的明珠。我们就以中国菜系为话题,讲一讲好吃的,顺便再说一说外键和连表查询。

鲁菜 山东菜系,而且在明清两代,宫廷御膳是以鲁菜为主,鲁菜味道浓厚,喜欢葱蒜,以海鲜、汤菜和内脏为主。因为鲁菜对其他菜系的影响颇大,所以鲁菜为八大菜系之首。代表:糖醋鲤鱼

川菜 四川菜系,以成都和重庆两地菜系为主,特点是酸、甜、麻、辣、香,川菜中有五大名菜:回锅肉、水煮肉片、麻婆豆腐、宫保鸡丁、鱼香肉丝。川菜太好吃了,名菜超多。



苏菜 江苏地方风味菜,由扬州、南京、苏州三地的地方菜发展而成,是宫廷第二大菜系,今天国宴仍以苏菜为主。其中扬州菜亦称淮扬菜,因受本地自然资源影响,菜色四季有别,讲究配色以及烹饪技巧。代表作:盐水鸭,松鼠桂鱼


粤菜。就是广东菜系,在国外的中国菜馆是以粤菜为主的。粤菜分为潮汕风味、广府风味以及客家风味,又以广府风味为代表。广东地域物产丰富且新鲜,而且讲究季节性。选材要在食物的最佳的时节,做法追求食材的原汁原味,不像川菜那样破坏了食材原来的鲜味。代表作:白斩鸡

那么就以上面提到的信息来建两张表。
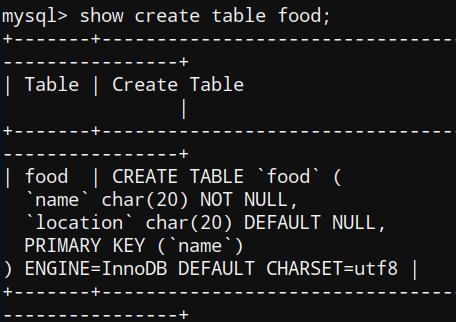
food表:
| 菜系 | 地区 |
| 鲁菜 | 山东 |
| 川菜 | 成都 |
| 苏菜 | 南京 |
| 粤菜 | 珠三角 |
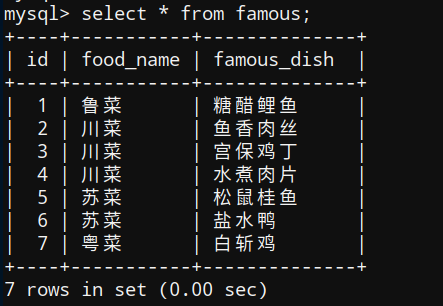
famous表:
| 菜系 | 代表 |
| 鲁菜 | 糖醋鲤鱼 |
| 川菜 | 鱼香肉丝、宫保鸡丁、水煮肉片 |
| 苏菜 | 松鼠桂鱼、盐水鸭 |
| 粤菜 | 白斩鸡 |
不带外键的两张表:
model.py
#coding:utf-8 from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column,Integer,String,DATE,ForeignKey,CHAR #导入外键 from sqlalchemy.orm import relationship #创建关系 engine = create_engine("mysql+mysqldb://root:12345678@localhost:3306/test?charset=utf8", encoding="utf-8") Base = declarative_base() #生成orm基类 class Food(Base): __tablename__ = "food" name = Column(CHAR(20),primary_key = True) location = Column(CHAR(20)) def __repr__(self): return "name:{0} location:{1}".format(self.name,self.location) class Famous(Base): __tablename__ = 'famous' id = Column(Integer,primary_key = True) food_name = Column(CHAR(20)) famous_dish = Column(CHAR(20)) def __repr__(self): return "id:{0} food_name:{1} famous_dish:{2}".format(self.id,self.food_name,self.famous_dish) Base.metadata.create_all(engine) #创建表


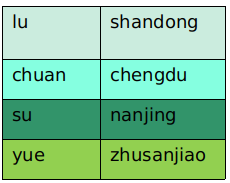
写入数据
写入数据:
#coding:utf-8 from sqlalchemy.orm import sessionmaker from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import create_engine,Column from model import Food,Famous
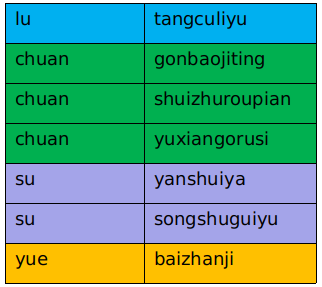
#中文在命令行中显示为16进制编码,所以用拼音代替,懂这个意思就行。 food = { u"lu":u"shandong", u"chuan":u"chengdu", u"su":u"nanjing", u"yue":u"zhusanjiao" } famous = [ {u'lu':u'tangculiyu'}, {u'chuan':u'yuxiangrousi'}, {u'chuan':u'gongbaojiding'}, {u'chuan':u'shuizhuroupian'}, {u'su':u'songshuguiyu'}, {u'su':u'yanshuiya'}, {u'yue':u'baizhanji'} ] engine = create_engine('mysql+mysqldb://root:12345678@localhost:3306/test?charset=utf8') DBSession = sessionmaker(bind=engine) session = DBSession() for key in food: new_food = Food(name=key,location=food[key]) session.add(new_food) session.commit() for dish in famous: new_famous = Famous(food_name=dish.keys()[0],famous_dish=dish.values()[0]) session.add(new_famous) session.commit() session.close()

这里有一点值得注意一下,famous的外键是food_name字段,指向的是food表中主键name字段。并且这里的对应关系是1对多的。在famous表中的food_name字段重复出现了,但值只有4种。这里就是外键的特性之一:
外键对应主表的主键,外键值可以是空,可以多个对1个,但一定要在主表中主键的值里。
有关外键的具体内容可以参考前面一篇 sqlalchemy外键和relationship查询
查询
select.py
#coding:utf-8 from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine from model import * #修改用户名、密码和数据库的名称为自己的 engine = create_engine("mysql+mysqldb://root:12345678@localhost:3306/test",) Session_class = sessionmaker(bind=engine) session = Session_class() query = session.query(Food).join(Famous).all() for x in query: print x
在没有外键关联的情况下对查询是有一定的影响的,没有外键关联的情况下,直接join连表,而不指明连表的字段就会报错,因为sqlalchemy连表查询没有外键自动关联两张表。
query = session.query(Food).join(Famous).all()

这个时候就需要在使用join连表时指明两张表连接的字段。
query = session.query(Food,Famous).join(Famous,Famous.food_name==Food.name).all()

带外键的表
因为不带外键的表查询时没有直接关联,所以下面使用带外键的表来看是否有优化?
#coding:utf-8 from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column,Integer,String,DATE,ForeignKey,CHAR #导入外键 from sqlalchemy.orm import relationship #创建关系 engine = create_engine("mysql+mysqldb://root:12345678@localhost:3306/test?charset=utf8", encoding="utf-8") Base = declarative_base() #生成orm基类 class Food(Base): __tablename__ = "food" name = Column(CHAR(20),primary_key = True) location = Column(CHAR(20)) def __repr__(self): return "name:{0} location:{1}".format(self.name,self.location) class Famous(Base): __tablename__ = 'famous' id = Column(Integer,primary_key = True) food_name = Column(CHAR(20),ForeignKey('food.name')) food = relationship("Food",backref="dish_belong_food") famous_dish = Column(CHAR(20)) def __repr__(self): return "id:{0} food_name:{1} famous_dish:{2}".format(self.id,self.food_name,self.famous_dish) Base.metadata.create_all(engine) #创建表
加了外键的famous表,从其建表的sql来看有一条外键记录,连接到food表中的name字段。

有外键关联的表,能够直接join表,sqlalchemy会自动用外键关联这两张表,这就是sqlalchemy对查询做出的优化。
query = session.query(Food,Famous).join(Famous).all()

连表查询
数据库连表有很多中操作,有全连接,左连接,右连接。在这些连接方式中,最基础的是全连接,看一下全连接的威力。
query = session.query(Food,Famous).all()

直接查询两张表,这时查询结果是返回被连接的两个表的笛卡尔积。将两张表看做是两个列表,全连接的方式类似如下的列表乘积。



在前面使用的join连接则是一种内连接。将两张表里相同的部分连接在一起,内连接的方式如下:
query = session.query(Food,Famous).join(Famous,Famous.food_name==Food.name).all()

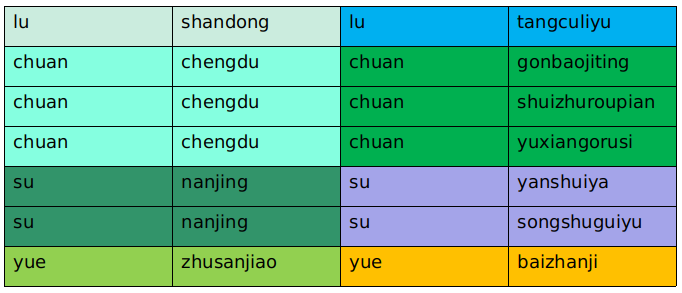
使用join的方式可以将多张表连在一起,不仅限于2张表,如果这里有还有一张介绍每一种美食的做法的一张表叫做Cook的话,将三种表连起来的写法:
query = session.query(Food,Famous,Cook).join(Famous,Famous.food_name==Food.name).join(Cook,Cook.famous_name==Famous.famous).all()
只要表与表之间有关联,那么就能用join的方式将表连接在一起,前提是一定要有字段是有关联的,如果连接两张毫无干系的表,那查询结果肯定是空。
在实际的使用过程中,将想要查询的表关联起来是第一步,还有一步也很重要,那就是过滤,筛选出我们需要的字段。而筛选在sqlalchemy中使用的是filter这个关键字。例如,想要筛选出所有苏菜里的好吃的,可以这么写:
query = session.query(Food,Famous).join(Famous,Famous.food_name==Food.name).filter(Food.name=='su').all()

filter的作用就是从得到连表所有的数据里过滤出我们感兴趣的数据。filte之前,我们得到的数据是这样的:

而使用了filter之后,从上面的结果中将food表中name字段为'su'的数据过滤出来,便是如下的数据:

同时还可以多级过滤,可以在前面的基础上再次过滤。比如说,我就爱吃鸭子,我在南京的美食找一找有没有和鸭子有关的好吃的,写法如下:
query = session.query(Food,Famous).join(Famous,Famous.food_name==Food.name).filter(Food.name=='su').filter(Famous.famous_dish.like('%ya%')).all()
结果如下,真的找到一条记录,盐水鸭,这是南京人民的最爱啊,能把鸭子吃出花来,就像有人调侃说没有一只鸭子能走出南京!('-')

总结
所以总结一下在sqlalchemy中如何得心应手,随心所欲的过滤出自己想要的数据:
1.找到你想要查询的数据的表
2.看看你手里有什么数据
3.确定手里的数据和你要查询的数据之间有直接关系还是有间接关系
4.将有关联的表连接起来(join ,连接相关的表)
5.从得到的数据中过滤出里感兴趣的数据(filter 过滤出你需要的数据)
通用公式

query 负责你要查询的结果的字段信息
join 负责你的连表操作,可以有多个join
filetr 负责过滤你感兴趣的数据,或者符合条件的数据才能被query展示
看到这里可能有好奇宝宝会问,不是还有一个all吗?这是什么意思呢?这个就是sqlalchemy的关键字了,具体参考前面的sqlalchemy关键字使用篇 。