就像Transformer带火了"XX is all you need"的论文起名大法,最近也看到了好多"Unified XX Framework for XX"的paper,毕竟谁不喜欢写好一套框架然后哪里需要哪里搬凸-凸。这一章让我们来看下如何把NER的序列标注任务转换成阅读理解任务。论文本身把重点放在新的框架可以更好解决嵌套实体问题,但是实际应用中我碰到Nested NER的情况很少,不过在此之外MRC对小样本场景,以及细粒,层次化实体的识别任务也有一些启发意义,代码详见ChineseNER/mrc
Paper: A Unified MRC Framework for Named Entity Recognition
下面我们把MRC的模型框架分开成两部分来看。第一部分是阅读理解任务主要处理模型的输入,第二部分是entity Span抽取任务针对模型的输出。因为他们其实是针对不同问题的改良,可以在不同的场景下分开使用
阅读理解:Tag -> Q&A
样本生成
在之前的NER任务中,对不同的实体类型的处理就是在label中使用不同的tag,地点就是LOC,人物就是PER,机构就是ORG。这种标注方式的问题在于
- label本身没有任何先验信息(这里的先验信息既包括label本身的含义,也包括label之间关联性)
- 以及output层的复杂度会随着实体类别的增加呈线性增长
- label和文本的交互只发生在输出层
MRC的改良方式是把label信息用Query进行编码,然后用Query和文本间的交互提取对应的实体信息。针对MSRA数据集中LOC,ORG,PER三类实体,作者分别用了如下的Query作为三类实体的先验信息
Tag2Query = {
'LOC': '按照地理位置划分的国家,城市,乡镇,大洲',
'PER': '人名和虚构的人物形象',
'ORG': '组织包括公司,政府党派,学校,政府,新闻机构'
}
Bert模型的输入和QA任务相同是\([CLS]query[SEP]text\), 以PER为例,每个样本都被构建为以下形式。
[CLS]人名和虚构的人物形象[SEP]这是中国领导人首次在哈佛大学发表演讲
如果NER任务有N个实体,训练样本有M个,按以上QA样本的构建方式会得到N*M个样本。
Query构建
因为这里Query是对label先验信息的刻画,所以如何构建query对最终的模型效果有很大的影响,作者在paper中对比了不同的Query生成方式,已ORG为例,作者尝试了
- position: tag的数值编码1/2/3
- keyword: 组织
- Rule-based template filling: 文中提到了哪些组织?
- wikipedia:组织的百科描述
- synonyms: 组织的同义词
- keyword+synonyms: 组织+组织的同义词
- Annotation guide: 组织包括公司,政府党派,学校,政府,新闻机构

对比结果如上,position因为没啥信息所以效果最差,keyword+synonyms显著优于只使用关键词/同义词,所以编码信息其实是越全面越好。wiki因为包含一些无效信息所以效果不如Annotation。在实际应用时,其实可以进一步在query中引入结构化信息,帮助更细粒度的实体标注,例如[综艺节目]音乐综艺,[综艺节目]搞笑综艺,对同一领域的实体加上领域信息,帮助模型学习实体间的关联关系
总结
QA模型结构的优点
- 加入了label的先验信息,会在few-shot/zero-shot场景中有更好的效果,对于新实体的冷启会是个不错的选择
- Query里可以加入label之间的关联信息,例如同一领域内的细分实体,对细粒度实体识别可能会有帮助
- QA的模型结构增加了实体类型和文本的交互
- 增加新的实体类型,只会增加对应的训练样本,不会增加模型复杂度
哈哈天上从来不会掉馅饼,有优点肯定有缺点滴~这个paper中没有提,不过在使用中感觉有几点需要填坑
- QA的样本构建方式加剧了Data Imbalance,原先有实体/无实体的比例如果是1:10,3类实体的QA样本可能就是1:30,会出现大量无实体的sample
- QA的构建方式导致一次推理只能提取1种实体类型,会增加线上推理耗时。当然你可以加机器加并发。在github上看到有另一种操作是把query拼在一起\([cls1]q1[cls2]q2[cls3]q3[seq]text\),不过这个需要同时修改训练方式,有试过效果的小伙伴欢迎comment下效果~
- Query的构建有时候会需要多次尝试,因为如果先验信息有错或者不完整,反而会影响到模型效果。
Span抽取
span抽取部分paper中写的很简单,真的是读完觉得简单明了!结果噼里啪啦一通写,跑起来发现模型span F1不收敛。。。于是默默去读了MRC的源码,感觉paper中省略了几个对模型效果会有影响的细节,下面来聊聊踩过的坑~
Start/End Index
为了同时抽取nested Entitty,作者使用了start index+end index的方式来标记实体位置。举个例子,样本如下
样本:{"title": "我 会 邀 请 许 惠 佑 一 同 来 访 ",
"label": [{"span": "许惠佑", "tag": "PER", "start_pos": 4, "end_pos": 6}]}
start index:[0,0,0,0,1,0,0,0,0,0,0]
end index:[0,0,0,0,0,0,1,0,0,0,0]
span index: [11,11] matrix,[(4,6)]=1
start index标记实体开始的位置,end index标记实体结束的位置。这里和序列标注的方式相同,会在Bert模型输出后面接一个classifier,预测每个位置是否start/end=1
Span Index
因为是nested entity,所以开始位置和结束位置可能会存在交叉,并不能唯一确定实体位置,所以需要一个span index。span index第i行第j列如果是1,就意味着i->j之间存在一个实体。
下面是paper中的公式,看公式我以为是把start end的logits进行了拼接,然后做一层线性变换,从start/end logits里面判断哪些是正确的组合。
结果看到下面的源码发现是直接对Bert的embedding输出copy了两份进行拼接后,又加了一层非线性变换。。。大哥这公式写的是不是有些抽象???所以span logits的计算空间复杂度比较高,因为span本身是seq_len * seq_len二维的,所以embedding空间是O(seq_len * seq_len * emb_size)。
span_embedding = MultiNonLinearClassifier(config.hidden_size * 2, 1, config.mrc_dropout, intermediate_hidden_size=config.classifier_intermediate_hidden_size)
sequence_heatmap = bert_outputs[0] # [batch, seq_len, hidden]
# [batch, seq_len, seq_len, hidden]
start_extend = sequence_heatmap.unsqueeze(2).expand(-1, -1, seq_len, -1)
end_extend = sequence_heatmap.unsqueeze(1).expand(-1, seq_len, -1, -1)
# [batch, seq_len, seq_len, hidden*2]
span_matrix = torch.cat([start_extend, end_extend], 3)
# [batch, seq_len, seq_len]
span_logits = span_embedding(span_matrix).squeeze(-1)
计算Span Loss的时候,作者先做了个一个下半矩阵的MASK,这一步只是把所有start_index>end_index的位置直接MASK掉。但只有这一个MASK并不够,因为span logits存在很严重的Data-Imbalance的问题,就像上面在Query构造时就提到过的,QA的样本会成倍的提高正负样本比,这里的Span Loss也是同样的问题。1个实体在start index中的正负比是1:Seq_len,在span index中就是1:(Seq_len * Seq_len)。
考虑到Span Index只是为了对Start/End Index的输出结果进一步筛选,所以作者在计算Span Loss的时候加了Candidate Mask。Mask有几种构建方式,最终作者选择的主要是‘pred_and_gold’ MASK,也就是只针对Span Label=1 or Start/End预测=1的位置计算Span Loss。。。(*≧ω≦)
Loss & Inference
最终的模型loss是start loss, end loss, span loss的加权求和。看作者的参数设定span的权重一般是0.1,start&end的权重是1。感觉这里的trick可能在于差异化梯度更新,因为span的loss计算依赖上面提到的使用start/end的预测结果作为MASK。所以需要start/end先行更快的收敛,再来帮助span进行收敛。直接差异化learning rate可能也阔以??
模型的预测结果,需要分别对start,end, span index进行预测,然后取三个Index的交集作为实体预测的结果。
评估
实际应用中到我还没碰到必须使用嵌套实体的场景,所以还是更倾向于适配Flat NER的解决方案,所以在使用MRC的时候,我只使用了前半部分的Query构建,后面的start/end/span的抽取方式直接替换成了BIO的序列标注方式。
在MSRA上进行实验,因为这里没加CRF层,所以直接和第一章时提到的Bert+CrossEntropy的模型结构进行对比。(这里用的是google Bert Base,测试过和WWM Bert Base没啥差别,作者paper中用的是WWM Bert Large,然我并跑不动。。。所以结果没法比)上面是MRC的结果下面是Bert-CE的结果。会发现PER的预测结果两个模型差不多,但是ORG/LOC的结果中,MRC反而要略差一些,指标主要差在召回率都是显著低于Bert-CE的
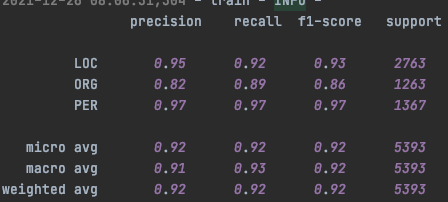
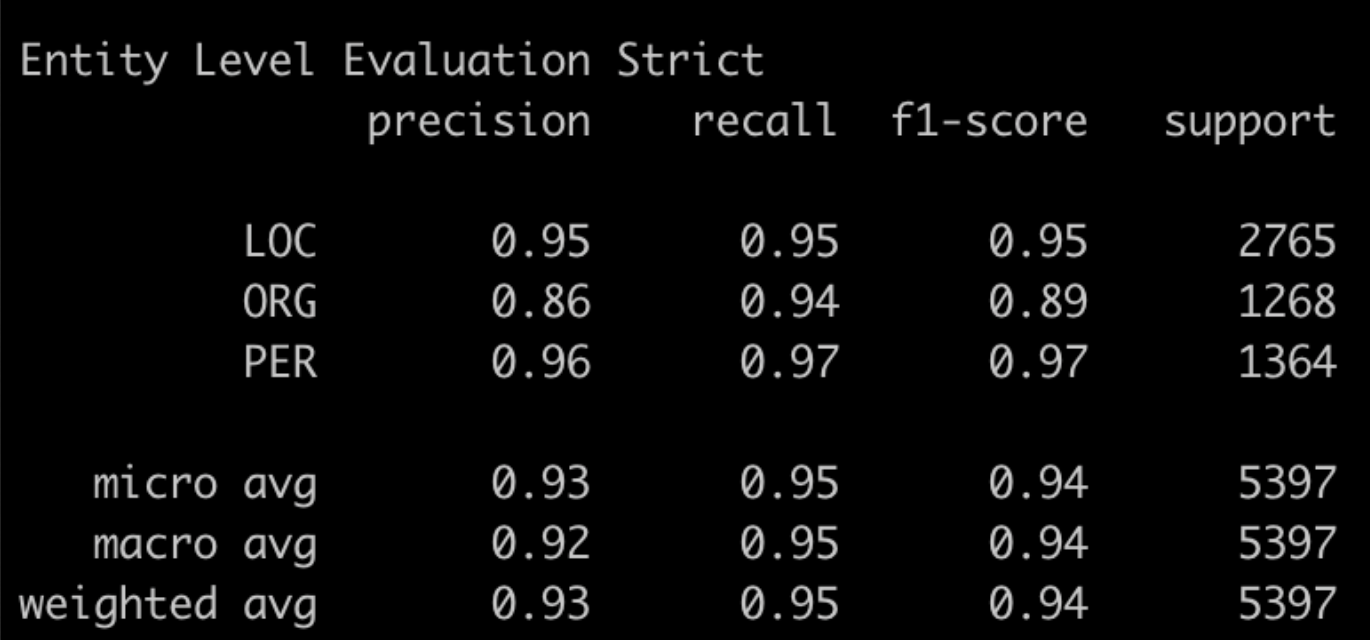
搂了一眼MRC的召回结果,发现个比较有意思的点就是不太符合Query定义的存在一些争议的case,一般都没被召回。不确定这是否是由于query引入了较强的先验信息带来的效果~
- ORG中会议类的多数都没有召回,会议类是否属于ORG其实有一些模糊,但至少是不包含在ORG的Query定义里的
{"text": "致公党第十一次全国代表大会是致公党历史上一次重要的会议。", "tag": "ORG",
"pred_entity_list": ["致公党", "致公党"],
"true_entity_list": ["致公党第十一次全国代表大会", "致公党"]}
{"text": "不久前,召开了举世瞩目的第十五次全国代表大会。", "tag": "ORG",
"pred_entity_list": [],
"true_entity_list": [ "第十五次全国代表大会"]}
{"text": "不久前成功召开的第十五次全国代表大会最重要的历史贡献是。。。", "tag": "ORG",
"pred_entity_list": [],
"true_entity_list": ["第十五次全国代表大会"]}
- 同样LOC中存在争议的case,例如月亮,太阳啥的是不是LOC(; ̄ェ ̄),MRC同样没有召回
{'text': '东方月正圆绍武圆,可是个绝妙好词!', 'tag': 'LOC',
'pred_entity_list': [],
'true_entity_list': ['月']}
{'text': '窗台前花圃的那丛玫瑰正痴情地吻着如水的月辉,摇曳着美丽的花影。', 'tag': 'LOC',
'pred_entity_list': [],
'true_entity_list': ['月']}
{'text': '此刻,我不知道彭丹是否也在月下徘徊,是否也在做着自己飞翔的梦?', 'tag': 'LOC',
'pred_entity_list': [],
'true_entity_list': ['月']}
{'text': '“人有悲欢离合,月有阴晴圆缺,此事古难全!', 'tag': 'LOC',
'pred_entity_list': [],
'true_entity_list': ['月']}
{'text': '”没什么,月亮碎了,心并没有碎!', 'tag': 'LOC',
'pred_entity_list': [],
'true_entity_list': ['月亮']}
{'text': '从圆明园破碎那天起,炼石补月的工程,就启动了。', 'tag': 'LOC',
'pred_entity_list': ['圆明园'],
'true_entity_list': ['圆明园', '月']}
{'text': '月碎了有什么?', 'tag': 'LOC',
'pred_entity_list': [],
'true_entity_list': ['月']}
{'text': '月碎了,只能造就出一批又一批、一代又一代的补月能手罢了!', 'tag': 'LOC',
'pred_entity_list': [],
'true_entity_list': ['月', '月']}
{'text': '二十一世纪的月亮,正从东方升起来,圆不圆?', 'tag': 'LOC',
'pred_entity_list': [],
'true_entity_list': ['月亮']}
{'text': '让人类撕碎撒谎者遮羞的破布,让历史记住战争的创伤,让孩子和鸽群一起起飞,在蓝天托起和平的太阳。', 'tag': 'LOC',
'pred_entity_list': [],
'true_entity_list': ['太阳']}
除了Query先验信息的影响之外,不确定这里Data Imbalance的影响有多少,下一章我们试下调整Loss Function看看会不会有进一步的提升~
Reference