什么是神经网络?
神经网络是一个受大脑工作方式开发出来的强力学习算法
我的理解是类比Spring框架中 mvc的 DAO层,Service层,和 Controller层。
只不过Service层是可以学习 并且自己开发的的。
符号介绍:
x 输入 y输出
假设将3个64x64的矩阵提取出来放入特征向量。
总值为
64x64x3 = 12288 这时我们就用n = nx = 12288标识 来表示输入的特征向量的维度。
训练的目标是要训练出一个分类器,来进行图像识别
以图片的特征向量x作为输入来预测输出的结果是1还是0
(x,y)来标识一个单独的样本
x是nx维的特征向量
标签y值为0或1
训练集由m个训练样本构成
而(x^(1),y^(1))表示样本一的输入和输出
这些一起就代表整个训练集
m = m_train
X = [x(1),x(2)]行着为m个样本数量,而竖着为N个样本
总结:维度就是有多少特征,样本数就是横着的那个。
Logistic回归的介绍(logistic regression)
logistic回归是一个用于二分分类的算法
因为我们目标的y值需要0<=y<=1 所以我们需要将sigmoid函数作用到这个量上
sigmoid函数是这样的
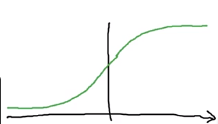
一个光滑的从0~1的函数 与y轴交点为0.5 sigmoid本身的含义为S型
其中sigmoid(Z)的表示为
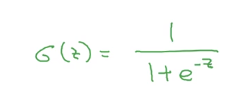
如果Z的函数非常大,那么e^-z接近于0 相反则接近于1
所以sigmoid(z)是一个大于0小于1的函数
至此我们可以用 y = sigmoid(wx+b)来训练出 0<=y<=1的结果
我们期望让训练出的y值趋近实际y值
Loss function : 我们通过定义这个损失函数L来衡量你得预测输出值y 和 实际的y值有多接近
误差平方看起来似乎是一个合理的选择,但用这个的话,梯度下降法就不太好用,在logistic回归中,我们会定义一个不同的损失函数,它起着与差方相似的作用这些会给我们一个凸的优化问题。
即Loss function 用来衡量期望的输出与Y之间的差异,换句话说,Loss函数用来计算单个训练实例的错误。
我们在此用的是这个函数

Cost function:
成本函数指的是整个训练集损失函数的平均值。
我们要寻找的参数w和b是损失最小的Cost值
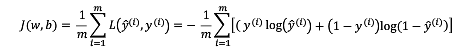
梯度下降法训练:

使用 repeat{
w = w - a J()的导数
}
通过优化成本函数,来不断地使w和b的值能拟合到实际值。