Collection接口和Map接口

|
Collection |
集合类的父类 |
|
HashSet |
无序,不重复 |
|
TreeSet |
从小到大的顺序 |
|
LinkedHashSet |
按照插入的顺序 |
|
LinkedList |
有序,链表结构,插入快,查询慢 |
|
ArrayList |
有序,顺序结构,插入慢,查询快 |
|
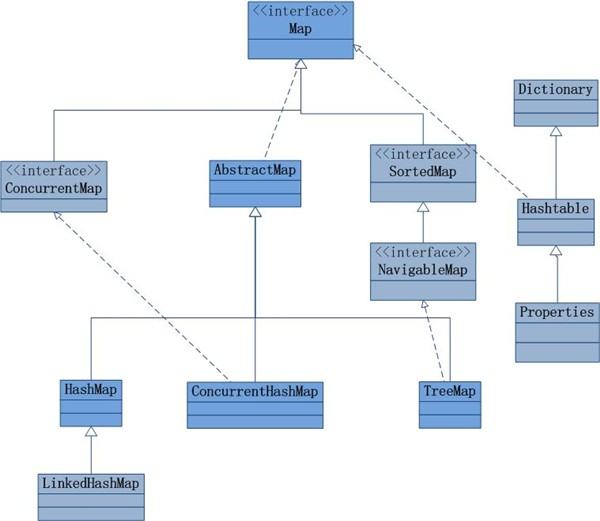
Map |
Map是一个接口,HashMap,ConcurrentHashMap,TreeMap,HashTable都实现了该接口。 |
|
HashMap |
HashMap线程不安全,HashMap的键和值都允许有null存在 |
|
ConcurrentHashMap |
ConcurrentHashMap是线程安全的HashMap的实现,键和值都不允许有null存在 |
|
TreeMap |
TreeMap基于二叉树实现,多用于排序 |
|
HashTable |
HashTable线程安全,HashTable的键和值都不允许有null存在 |
|
效率 |
HashMap>ConcurrentHashMap>HashTable |
JVM的内存结构,JVM的算法
JVM内存结构主要有三大块:堆内存、方法区和栈。
堆内存是JVM中最大的一块由年轻代和老年代组成,而年轻代内存又被分成三部分,Eden空间、From Survivor空间、To Survivor空间,默认情况下年轻代按照8:1:1的比例来分配;
方法区存储类信息、常量、静态变量等数据,是线程共享的区域,为与Java堆区分,方法区还有一个别名Non-Heap(非堆);栈又分为java虚拟机栈和本地方法栈主要用于方法的执行。
bio,nio,aio的区别
同步阻塞IO(JAVA BIO):
同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
同步非阻塞IO(Java NIO) :
同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。用户进程也需要时不时的询问IO操作是否就绪,这就要求用户进程不停的去询问。
异步阻塞IO(Java NIO):
此种方式下是指应用发起一个IO操作以后,不等待内核IO操作的完成,等内核完成IO操作以后会通知应用程序,这其实就是同步和异步最关键的区别,同步必须等待或者主动的去询问IO是否完成,那么为什么说是阻塞的呢?因为此时是通过select系统调用来完成的,而select函数本身的实现方式是阻塞的,而采用select函数有个好处就是它可以同时监听多个文件句柄(如果从UNP的角度看,select属于同步操作。因为select之后,进程还需要读写数据),从而提高系统的并发性!
(Java AIO(NIO.2))异步非阻塞IO:
在此种模式下,用户进程只需要发起一个IO操作然后立即返回,等IO操作真正的完成以后,应用程序会得到IO操作完成的通知,此时用户进程只需要对数据进行处理就好了,不需要进行实际的IO读写操作,因为真正的IO读取或者写入操作已经由内核完成了。
阻塞队列的实现 参考ArrayBlockingQueue的底层实现
ArrayBlockingQueue:基于数组实现的一个阻塞队列,在创建ArrayBlockingQueue对象时必须制定容量大小。并且可以指定公平性与非公平性,默认情况下为非公平的,即不保证等待时间最长的队列最优先能够访问队列。
LinkedBlockingQueue:基于链表实现的一个阻塞队列,在创建LinkedBlockingQueue对象时如果不指定容量大小,则默认大小为Integer.MAX_VALUE。
ArrayBlockingQueue基于数组的阻塞队列实现,在ArrayBlockingQueue内部,维护了一个定长数组,以便缓存队列中的数据对象,这是一个常用的阻塞队列,除了一个定长数组外,ArrayBlockingQueue内部还保存着两个整形变量,分别标识着队列的头部和尾部在数组中的位置。 ArrayBlockingQueue在生产者放入数据和消费者获取数据,都是共用同一个锁对象,由此也意味着两者无法真正并行运行,这点尤其不同于LinkedBlockingQueue;按照实现原理来分析,ArrayBlockingQueue完全可以采用分离锁,从而实现生产者和消费者操作的完全并行运行。Doug Lea之所以没这样去做,也许是因为ArrayBlockingQueue的数据写入和获取操作已经足够轻巧,以至于引入独立的锁机制,除了给代码带来额外的复杂性外,其在性能上完全占不到任何便宜。 ArrayBlockingQueue和LinkedBlockingQueue间还有一个明显的不同之处在于,前者在插入或删除元素时不会产生或销毁任何额外的对象实例,而后者则会生成一个额外的Node对象。这在长时间内需要高效并发地处理大批量数据的系统中,其对于GC的影响还是存在一定的区别。而在创建ArrayBlockingQueue时,我们还可以控制对象的内部锁是否采用公平锁,默认采用非公平锁。
为什么要用线程池
线程的执行过程:
创建(t1) 运行(t2) 销毁(t3)
线程运行的总时间 T= t1+t2+t3;
假如,有些业务逻辑需要频繁的使用线程执行某些简单的任务,那么很多时间都会浪费t1和t3上。
为了避免这种问题,JAVA提供了线程池
在线程池中的线程可以复用,当线程运行完任务之后,不被销毁。
因为创建线程开销比较大,当你的程序需要频繁地创建销毁一些相同的线程时,就可以先创建一定数量的线程,让他们睡眠,当需要线程的时候,就从里面拿一个出来跑,跑完了再放回去,这样就增加了效率
volatile关键字的用法
使多线程中的变量可见
更多多线程面试题参考(https://www.cnblogs.com/Jansens520/p/8624708.html)
更多类加载机制参考(https://mp.weixin.qq.com/s/ofb_a1_KSaET70lVFSI7PQ)
