一、添加索引
1、基本概念信息
索引(index):一个用来指向一个或多个分片(shards)的“逻辑命名空间(logical namespace)”.
一个分片(shard)是一个最小级别工作单元,它只是保存了索引中所有数据的一部分。
ElasticSearch 设计的理念就是分布式搜索引擎,底层其实还是基于 lucene 的。核心思想就是在多台机器上启动多个 es 进程实例,组成了一个 es 集群。
es 中存储数据的基本单位是索引,比如说你现在要在 es 中存储一些订单数据,你就应该在 es 中创建一个索引 order_idx,所有的订单数据就都写到这个索引里面去,一个索引差不多就是相当于是 mysql 里的一张表。
index -> type -> mapping -> document -> field。
index相当于mysql中的一张表。一个index中可能包含多个type,或者一个type,每个type字段是差不多的,却有一些略微的差别。假设有一个 index,是订单 index,里面专门是放订单数据的
。就好比说你在 mysql 中建表,有些订单是实物商品的订单,比如一件衣服、一双鞋子;有些订单是虚拟商品的订单,比如游戏点卡,话费充值。就两种订单大部分字段是一样的,但是少部分字段可能有略微的一些差别。
所以就会在订单 index 里,建两个 type,一个是实物商品订单 type,一个是虚拟商品订单 type,这两个 type 大部分字段是一样的,少部分字段是不一样的。
每个 type 有一个 mapping,如果你认为一个 type 是一个具体的一个表,index 代表多个 type 的同属于的一个类型,mapping 就是这个 type 的表结构定义,你在 mysql 中创建一个表,肯定是要定义表结构的,里面有哪些字段,每个字段是什么类型。实际上你往 index 里的一个 type 里面写的一条数据,叫做一条 document,一条 document 就代表了 mysql 中某个表里的一行,每个 document 有多个 field,每个 field 就代表了这个 document 中的一个字段的值。
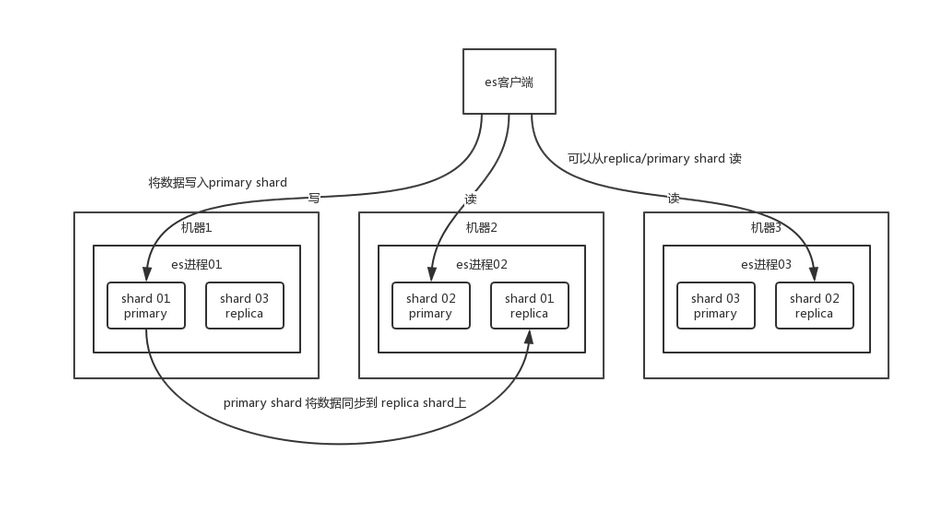
每个索引可以分为多个shard,每个shard存储数据,并且每个shard有多个备份,每个shard有一个 primary shard,负责写入数据,同时包含几个副本(replica),当primary shard写入数据后,数据会同步到replica shard
通过这个 replica 的方案,每个 shard 的数据都有多个备份,实现了高可用
2、工作原理
es 写数据
- 客户端选择一个节点发送请求,该node即协调点
- 协调点对document进行路由,请求最终转发给对应节点
- 节点接收请求后,节点上的 primary shard 处理请求,然后将数据同步到副本
- 数据写入及副本同步成功后,响应结果给客户端
es 读数据
- 客户端选择一个节点发送请求,该node即协调点
- 协调点对doc id进行hash路由,请求转发到对应节点,此时会使用 round-robin 随机轮询算法,在 primary shard 以及其所有副本中随机选择一个,让读请求负载均衡。
- 接收请求的 node 返回 document 给协调点。
- 协调点返回 document 给客户端。