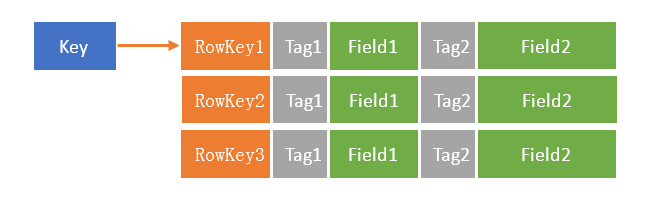
在NoSQL存储系统中,一般都采用Key-Value的数据类型,Key-Value结构简单,易于存储,非常适合分布式NoSQL存储系统。但简单的数据类型对业务存储的数据就有一定的局限性,比如需要存储列表类型的数据。针对这个问题,系统对Key-Value类型的数据做了一些扩展,支持在一个Key下存储多个字段和列表,扩大了数据存储的业务场景。本文主要介绍这个分布式存储系统所支持的数据类型,以及数据在内存中的存储实现。
数据类型
-
Key-Value
Key-Value是最简单的数据类型,Key和Value都不支持结构化数据,业务进行读写的时候需要进行序列化和反序列化,系统并不理解数据结构,都当作二进制序列处理,具有通用性,这样Key和Value就支持任意类型的数据,只要序列化后的数据长度不超过限制。

-
Key-Fields
Key-Fields支持多个字段,使用整型的Tag进行字段标识,每个Tag对应的Field长度可以不一样,Field也是序列化的数据,比较通用。对于需要在一个Key的数据中存储多个字段的场景,Key-Fields相比Key-Value友好了很多。

-
Key-Rows
Key-Rows支持多个行,每一行就是一个Key-Fields,支持多个字段,各行的Field数量、长度都可以不一样,非常灵活。Key-Rows可以用来存储列表,支持更复杂的业务场景,如存放一个用户的购物订单信息。
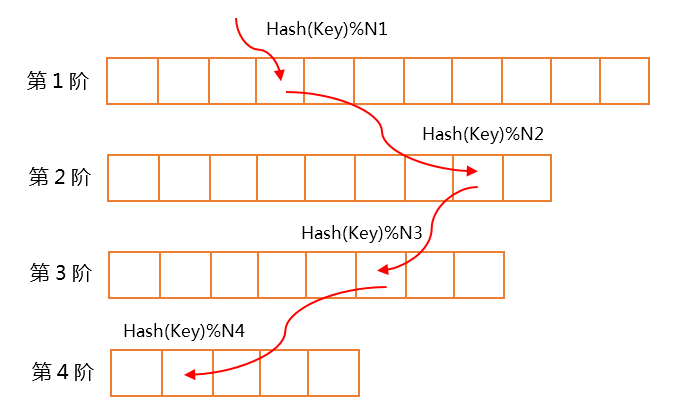
多阶哈希表
由于数据是全内存存储,为了保证进程重启时不丢失数据,使用共享内存的方式,同时也方便了多个进程访问数据。对于Key-Value类型的数据,最高效数据结构自然是哈希表。这里介绍一种多阶哈希表的实现,具有简单、高效、鲁棒等特点,非常适合工程应用。
多阶哈希表采用类似再哈希的思想来解决冲突。如下图所示,把一个线性数组划分为N阶,每一阶的桶大小(元素个数)为Ni(1≤i≤N),插入数据时,通过Hash(Key)%Ni计算在每一阶的位置,从第1阶开始,如果出现冲突,则继续在下一阶查找,只到找到空位为止,如果在N阶都发生了冲突,则插入失败,查找的过程需要类似。需要注意的是,在插入一个新的数据时,需要先在所有阶都查找一遍,对性能会有一定的影响,例如数据1第一次插入在第3阶,随后在其查找路径上第2阶的数据2被删除,在数据1再次插入时,会在第2阶找到空位,如果插入此位置,第3阶的数据2会残留而无法清理,造成空间的浪费。而对于NoSQL数据存储系统来说,新增数据占比比较少,大部分操作是数据更新和读取,所以多阶哈希表在这种场景下可以保持比较好的性能。
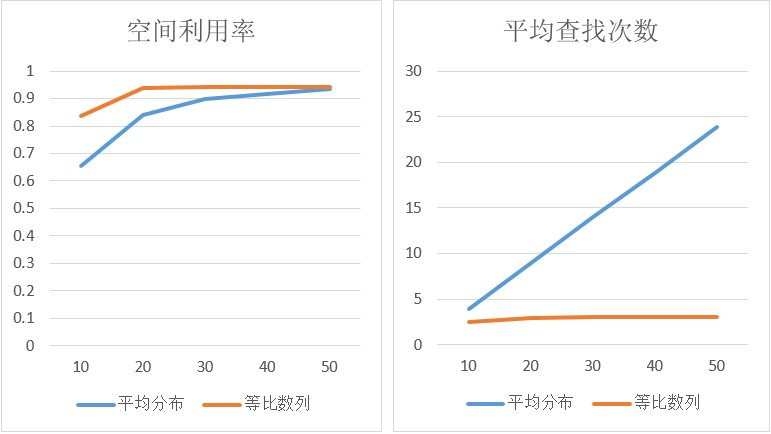
衡量多阶哈希表的好坏主要有2个指标,空间利用率和平均查找次数。通过实验可知,阶数越多,处理冲突的能力越强,空间的利用率也高,但平均查找次数越多,可见空间利用率和平均查找次数相互制约,需要根据实际情况进行权衡。
对于每一阶的桶大小,需要选择不同的质数,可以在数学上证明各阶的桶大小互质时,数据在各阶的分布会更加均匀,从而降低了冲突的概率。最简单的方法是各阶选择连续的质数,那有没有更好的选择,可以在相同阶数下,得到更高的空间利用率和更少的平均查找次数。在每阶桶大小相近的情况下,低阶会分布更多的数据,所以从低阶到高阶桶大小递减的情况下,会提升空间利用率;在阶数不变的条件下,为了降低平均查找次数,应该让低阶桶大小越大越好,同时为了保持高阶对冲突的处理能力,桶大小不能太小。综上所述,桶大小从低阶到高阶依次递减,在低阶递减比较剧烈,在高阶递减比较平缓,而等比数列比较符合这个特征。桶大小采用系数为1.5的等比数列与桶大小平均分布的对比测试结果如下,使用随机数进行插入,第一次出现插入失败时的空间利用率作为最终的结果,可以看出在相同阶数下,桶大小为等比数列时会有更高的空间利用率和更少的平均查找次数,阶数为20阶是比较好的选择,此时多阶哈希表的空间利用率达到93%,平均查找次数约为3次。
在前面所列举的几种数据类型,Key和数据都是变长的,而哈希表的节点是定长的,如果把数据直接存在哈希表节点,是非常浪费空间的。为了提高内存的利用率,这里采用一种哈希表和链表相结合的数据接口,如下图所示,哈希表节点存的是数据索引,Key和数据都存放在一个定长块链表中,这样就可以根据数据大小来分配定长块的数量,即高效又不浪费空间。定长块的大小也需要仔细权衡,太大了会导致无效空洞比较大,太小了又会使得每个数据占用的定长块数量比较多,对性能有一定的影响。

读写冲突
对于一块存储空间,单进程进行读写是最简单的设计,没有读写冲突的问题,但单进程在处理能力上就会成为瓶颈。为了提升处理能力,有必要使用多进程或多线程并发的方式,这样就引入了读写冲突的问题。
如果多个写进程并发操作一块存储空间,需要使用互斥锁机制,由于存储结构使用了链表,需要大粒度的锁才能保证不出现错链,并且锁机制实现起来也比较复杂。在这一系列的上一篇文章中提高一个更好的解决方法,把单机的存储空间划分为多个存储单元,每个存储单元由一个写进程处理,这样在并发的同时也保证了互斥,这种无锁的实现性能也更好。
解决了写进程互斥的问题,读写进程之间还是会存在冲突,如果某个数据在进行写操作的过程中,正好读进程在读取这个数据,就有可能读到的是不完整的数据。这个问题可以通过校验来解决,在数据中记录一个校验值,每次写入就更新校验值,读取数据的时候,对数据进行校验,如果校验失败说明出现了读写冲突,则需要进行重试。为了降低读写冲突的概率,在更新数据的时候,按照下图所示的流程,并不在原来的定长块链上进行覆写进行处理,而是分配新的定长块链写入数据。

大多数使用分布式存储的业务,都是写少读多的场景,在上面的读写冲突处理机制下,一个存储单元是可以同时支持一个写进程和多个读进程,使得读操作有更高的并发能力,非常适合写少读多的情况。