字体反爬
字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的。
现在貌似不少网站都有采用这种反爬机制,我们通过猫眼的实际情况来解释一下。
下图的是猫眼网页上的显示:
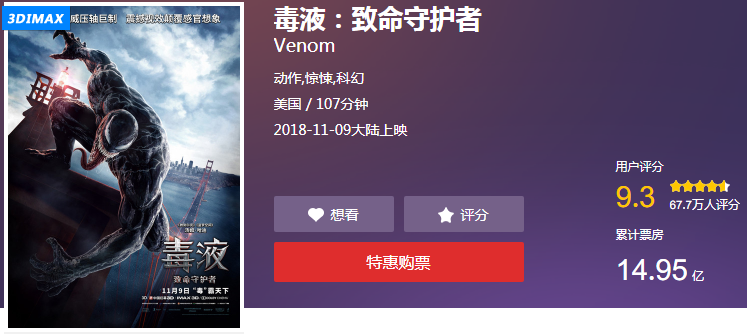
检查元素看一下
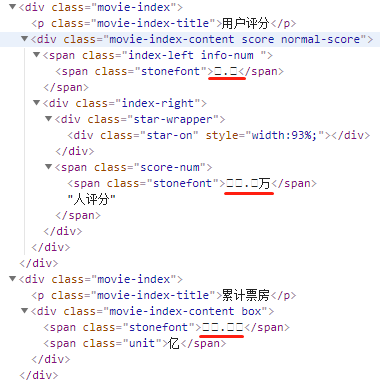
这是什么鬼,关键信息全是乱码。
熟悉 CSS 的同学会知道,CSS 中有一个 @font-face,它允许网页开发者为其网页指定在线字体。原本是用来消除对用户电脑字体的依赖,现在有了新作用——反爬。
汉字光常用字就有好几千,如果全部放到自定义的字体中,那么字体文件就会变得很大,必然影响网页的加载速度,因此一般网站会选取关键内容加以保护,如上图,知道了等于不知道。
这里的乱码是由于 unicode 编码导致的,查看源文件可以看到具体的编码信息。
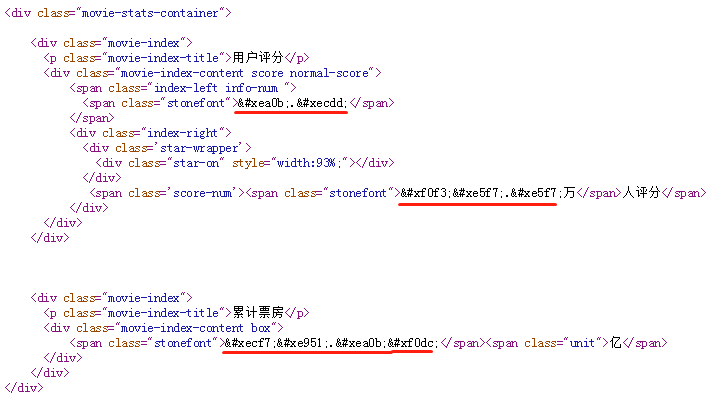
搜索 stonefont,找到 @font-face 的定义:

这里的 .woff 文件就是字体文件,我们将其下载下来,利用 http://fontstore.baidu.com/static/editor/index.html 网页将其打开,显示如下:

网页源码中显示的  跟这里显示的是不是有点像?事实上确实如此,去掉开头的 &#x 和结尾的 ; 后,剩余的4个16进制显示的数字加上 uni 就是字体文件中的编码。所以  对应的就是数字“9”。
知道了原理,我们来看下如何实现。
处理字体文件,我们需要用到 FontTools 库。
先将字体文件转换为 xml 文件看下:
from fontTools.ttLib import TTFont
font = TTFont('bb70be69aaed960fa6ec3549342b87d82084.woff')
font.saveXML('bb70be69aaed960fa6ec3549342b87d82084.xml')
打开 xml 文件
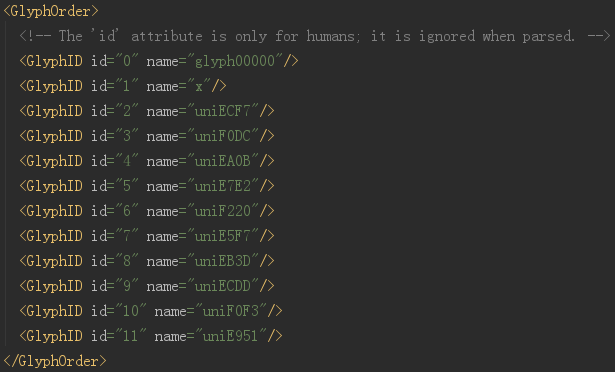
开头显示的就是全部的编码,这里的 id 仅仅是编号而已,千万别当成是对应的真实值。实际上,整个字体文件中,没有任何地方是说明 EA0B 对应的真实值是啥的。
看到下面
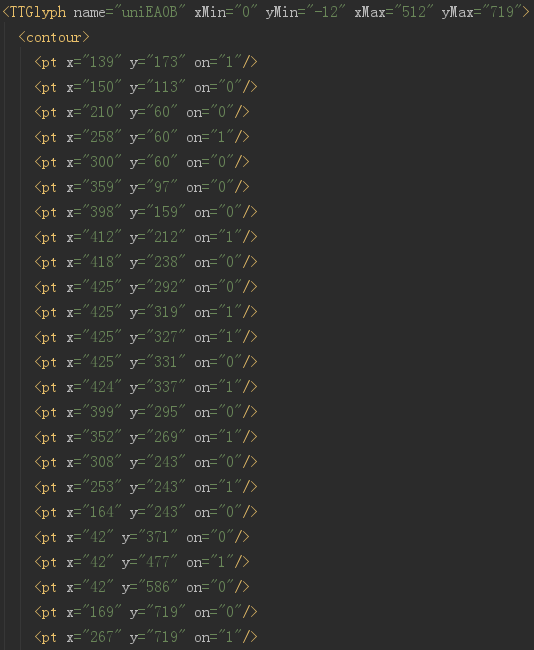
这里就是每个字对应的字体信息,计算机显示的时候,根本不需要知道这个字是啥,只需要知道哪个像素是黑的,哪个像素是白的就可以了。
猫眼的字体文件是动态加载的,每次刷新都会变,虽然字体中定义的只有 0-9 这9个数字,但是编码和顺序都是会变的。就是说,这个字体文件中“EA0B”代表“9”,在别的文件中就不是了。
但是,有一样是不变的,就是这个字的形状,也就是上图中定义的这些点。
我们先随便下载一个字体文件,命名为 base.woff,然后利用 fontstore 网站查看编码和实际值的对应关系,手工做成字典并保存下来。爬虫爬取的时候,下载字体文件,根据网页源码中的编码,在字体文件中找到“字形”,再循环跟 base.woff 文件中的“字形”做比较,“字形”一样那就说明是同一个字了。在 base.woff 中找到“字形”后,获取“字形”的编码,而之前我们已经手工做好了编码跟值的映射表,由此就可以得到我们实际想要的值了。
这里的前提是每个字体文件中所定义的“字形”都是一样的(猫眼目前是这样的,以后也许还会更改策略),如果更复杂一点,每个字体中的“字形”都加一点点的随机形变,那这个方法就没有用了,只能祭出杀手锏“OCR”了。
下面是完整的代码,抓取的是猫眼2018年电影的第一页,由于主要是演示破解字体反爬,所以没有抓取全部的数据。
代码中使用的 base.woff 文件跟上面截图显示的不是同一个,所以会看到编码跟值跟上面是对不上的。
import os
import time
import re
import requests
from fontTools.ttLib import TTFont
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
host = 'http://maoyan.com'
def main():
url = 'http://maoyan.com/films?yearId=13&offset=0'
get_moviescore(url)
os.makedirs('font', exist_ok=True)
regex_woff = re.compile("(?<=url(').*.woff(?='))")
regex_text = re.compile('(?<=<span class="stonefont">).*?(?=</span>)')
regex_font = re.compile('(?<=&#x).{4}(?=;)')
basefont = TTFont('base.woff')
fontdict = {'uniF30D': '0', 'uniE6A2': '8', 'uniEA94': '9', 'uniE9B1': '2', 'uniF620': '6',
'uniEA56': '3', 'uniEF24': '1', 'uniF53E': '4', 'uniF170': '5', 'uniEE37': '7'}
def get_moviescore(url):
# headers = {"User-Agent": UserAgent(verify_ssl=False).random}
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/68.0.3440.106 Safari/537.36'}
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'lxml')
ddlist = soup.find_all('dd')
for dd in ddlist:
a = dd.find('a')
if a is not None:
link = host + a['href']
time.sleep(5)
dhtml = requests.get(link, headers=headers).text
msg = {}
dsoup = BeautifulSoup(dhtml, 'lxml')
msg['name'] = dsoup.find(class_='name').text
ell = dsoup.find_all('li', {'class': 'ellipsis'})
msg['type'] = ell[0].text
msg['country'] = ell[1].text.split('/')[0].strip()
msg['length'] = ell[1].text.split('/')[1].strip()
msg['release-time'] = ell[2].text[:10]
# 下载字体文件
woff = regex_woff.search(dhtml).group()
wofflink = 'http:' + woff
localname = 'font\' + os.path.basename(wofflink)
if not os.path.exists(localname):
downloads(wofflink, localname)
font = TTFont(localname)
# 其中含有 unicode 字符,BeautifulSoup 无法正常显示,只能用原始文本通过正则获取
ms = regex_text.findall(dhtml)
if len(ms) < 3:
msg['score'] = '0'
msg['score-num'] = '0'
msg['box-office'] = '0'
else:
msg['score'] = get_fontnumber(font, ms[0])
msg['score-num'] = get_fontnumber(font, ms[1])
msg['box-office'] = get_fontnumber(font, ms[2]) + dsoup.find('span', class_='unit').text
print(msg)
def get_fontnumber(newfont, text):
ms = regex_font.findall(text)
for m in ms:
text = text.replace(f'&#x{m};', get_num(newfont, f'uni{m.upper()}'))
return text
def get_num(newfont, name):
uni = newfont['glyf'][name]
for k, v in fontdict.items():
if uni == basefont['glyf'][k]:
return v
def downloads(url, localfn):
with open(localfn, 'wb+') as sw:
sw.write(requests.get(url).content)
if __name__ == '__main__':
main()
也可以扫码关注我的个人公众号,后台回复 “猫眼”获取源码,及代码中我使用的 basefont。
相关博文推荐: