在调度这一步完成后,Kubernetes 就需要负责将这个调度成功的 Pod,在宿主机上创建出来,并把它所定义的各个容器启动起来。这些,都是 kubelet 这个核心组件的主要功能。
kubelet 本身,也是按照“控制器”模式来工作的。它实际的工作原理,可以用如下所示的一幅示意图来表示清楚。
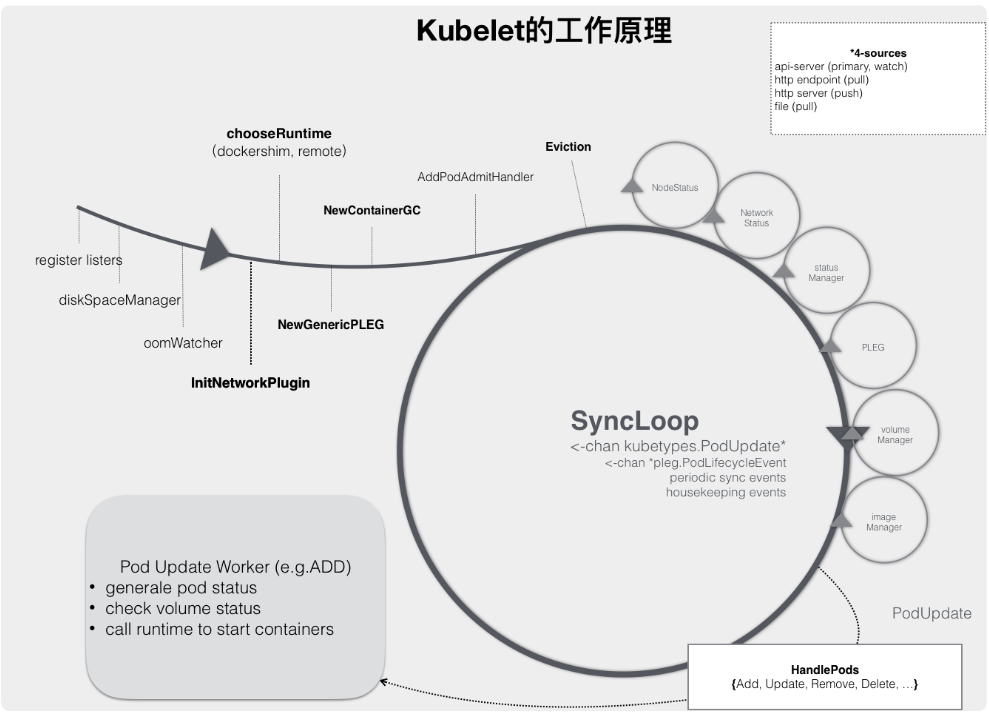
kubelet 的工作核心,就是一个控制循环,即:SyncLoop(图中的大圆圈)。而驱动这个控制循环运行的事件,包括四种:
1、Pod 更新事件;
2、Pod 生命周期变化;
3、kubelet 本身设置的执行周期;
4、定时的清理事件。
kubelet 启动的时候,要做的第一件事情,就是设置 Listers,也就是注册它所关心的各种事件的 Informer。这些 Informer,就是 SyncLoop 需要处理的数据的来源。
此外,kubelet 还负责维护着很多很多其他的子控制循环(也就是图中的小圆圈)。这些控制循环的名字,一般被称作某某 Manager,比如 Volume Manager、Image Manager、Node Status Manager 等等。这些控制循环的责任,就是通过控制器模式,完成 kubelet 的某项具体职责。比如 Node Status Manager,就负责响应 Node 的状态变化,然后将 Node 的状态收集起来,并通过 Heartbeat 的方式上报给 APIServer。再比如 CPU Manager,就负责维护该 Node 的 CPU 核的信息,以便在 Pod 通过 cpuset 的方式请求 CPU 核的时候,能够正确地管理 CPU 核的使用量和可用量。
SyncLoop,又是如何根据 Pod 对象的变化,来进行容器操作的呢?
kubelet 也是通过 Watch 机制,监听了与自己相关的 Pod 对象的变化。当然,这个 Watch 的过滤条件是该 Pod 的 nodeName 字段与自己相同。kubelet 会把这些 Pod 的信息缓存在自己的内存里。
而当一个 Pod 完成调度、与一个 Node 绑定起来之后, 这个 Pod 的变化就会触发 kubelet 在控制循环里注册的 Handler,也就是上图中的 HandlePods 部分。此时,通过检查该 Pod 在 kubelet 内存里的状态,kubelet 就能够判断出这是一个新调度过来的 Pod,从而触发 Handler 里 ADD 事件对应的处理逻辑。
在具体的处理过程当中,kubelet 会启动一个名叫 Pod Update Worker 的、单独的 Goroutine 来完成对 Pod 的处理工作。
比如,如果是 ADD 事件的话,kubelet 就会为这个新的 Pod 生成对应的 Pod Status,检查 Pod 所声明使用的 Volume 是不是已经准备好。然后,调用下层的容器运行时(比如 Docker),开始创建这个 Pod 所定义的容器。
而如果是 UPDATE 事件的话,kubelet 就会根据 Pod 对象具体的变更情况,调用下层容器运行时进行容器的重建工作。
kubelet 调用下层容器运行时的执行过程,并不会直接调用 Docker 的 API,而是通过一组叫作 CRI(Container Runtime Interface,容器运行时接口)的 gRPC 接口来间接执行的。Kubernetes 项目之所以要在 kubelet 中引入这样一层单独的抽象,当然是为了对 Kubernetes 屏蔽下层容器运行时的差异。