高级数据类型
计算机是可以做数学计算的机器,因此,计算机程序理所当然地可以处理各种数值。但是,计算机能处理的远不止数值,还可以处理文本、图形、音频、视频、网页等各种各样的数据,不同的数据,需要定义不同的数据类型。在Python中,能够直接处理的数据类型有:数字、字符串、列表、元组、字典等。
序列
在python中,序列就是一组按照顺序排列的值(数据集合)(字符串就是序列)
Python中包含三种内置的序列类型:字符串,列表和元组。(字典不属于序列)
序列的优点:支持索引和切片的操作;
特征:第一个正索引为0,指向的是左端,第一个索引为负数的时候,指向的是右端。
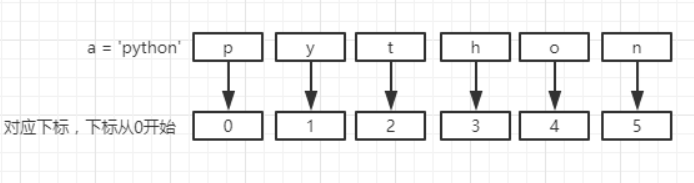
1、字符串(str)及常用方法
下标和切片
字符串有下标,切片是指截取字符串中的其中一段内容。
切片使用语法:[起始下标:结束下标:步长] ,默认步长为1
切片截取的内容不包含结束下标对应的数据,步长指的是隔几个下标获取一个字符。
切片的高级特性:可以根据下标获取序列对象的任意(部分)数据;
切片
格式:slice[start:end:step]
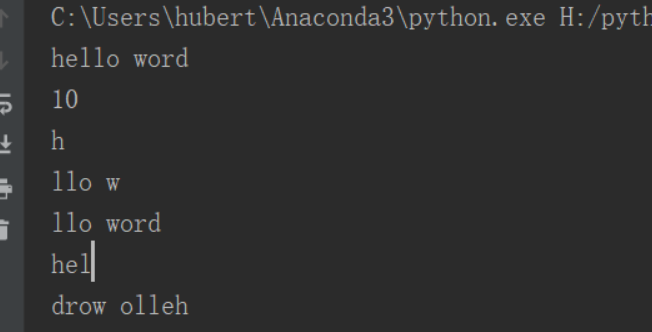
a='hello word' print(a) print(len(a)) #包含空格 print(a[0]) print(a[2:7]) #左闭右开,其实是2-6的索引 print(a[2:]) print(a[:3]) print(a[::-1])
常用的函数(好多即适用字符串又适用列表元组之类的)
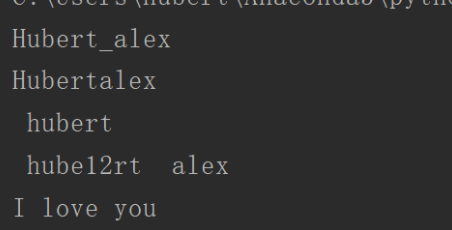
1.capitalize() 首字母变大写;title()把每个单词的首字母变成大写
首位数不是字母就不用变
a='hubert_alex' b='hubertalex' c=' hubert' d=' hube12rt alex' e='i love you' print(a.capitalize()) print(b.capitalize()) print(c.capitalize()) print(d.capitalize()) print(e.capitalize())
将不是字母后的字母自动识别为首字母
a='hubert_alex' b='hubertalex' c=' hubert' d=' hube12rt alex' e='i love you' print(a.title()) print(b.title()) print(c.title()) print(d.title()) print(e.title())

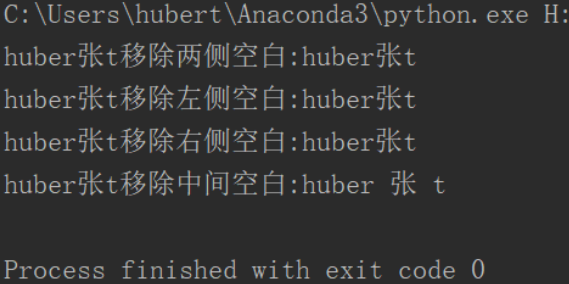
2.strip() 同时移除两侧空白(同理:lstrip和rstrip只能移除左侧或右侧)
name=' huber张t ' name1=' huber张t' name2='huber张t ' name3='huber 张 t ' print('huber张t移除两侧空白:%s'%name.strip()) print('huber张t移除左侧空白:%s'%name1.strip()) print('huber张t移除右侧空白:%s'%name2.strip()) print('huber张t不能移除中间空白:%s'%name3.strip())
3.查看内存地址id()

4.find()与index()查找目标对象在序列对象中的索引值
# find查找 a='i love python' print(a.find('p')) print(a[a.find('p')]) print(a.find('py')) print(a.find('m')) #不存在的时候返回-1 print(a.find('o')) #有多个时候,只找到第一个的索引值 #index函数 print(a.index('p')) print(a.index('py')) print(a.index('o')) # print(a.index('m')) #不存在的时候会报错

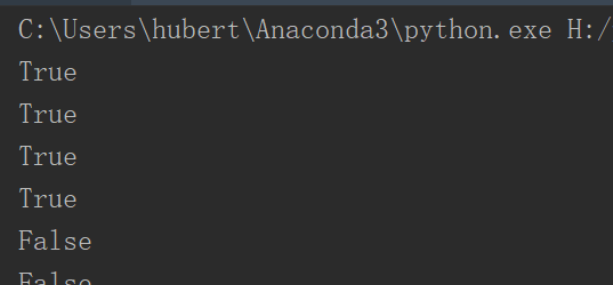
5、endswith/startswith()是否 x结束/开始
a='i love python' print(a.startswith('i ')) print(a.endswith('on')) print(a.startswith('i')) print(a.endswith('n')) print(a.startswith('I ')) print(a.endswith('N'))
6、swapcase大写变小写,小写变大写;lower/upper 大小写转换;islower()判断是否是小写

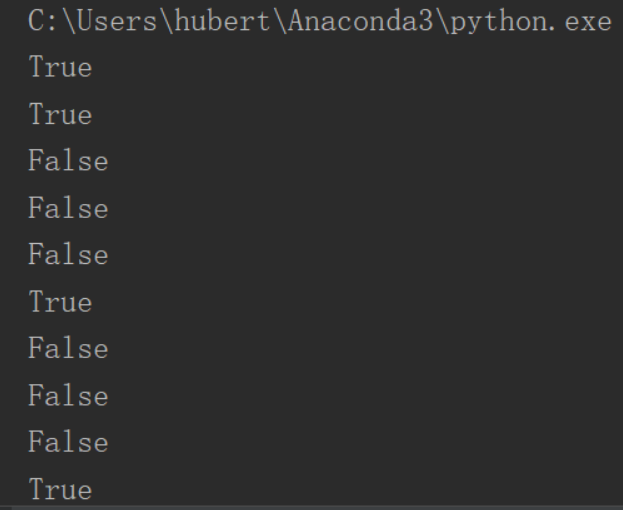
7、isalnum()判断是否是字母和数字;isalpha()判断是否是字母 ;isdigit()判断是否是数字
a='abc123' b='Abc1235' c='aCb' d='abc12@!' e='123' print(a.isalnum()) print(b.isalnum()) print(d.isalnum()) print(a.isalpha()) print(b.isalpha()) print(c.isalpha()) print(d.isalpha()) print(a.isdigit()) print(d.isdigit()) print(e.isdigit())
8、split()分割字符串,通过指定分隔符对字符串进行切片,并返回分割后的字符串列表(list)
a='i love python' # split不带参数的时候以空格(不管几个空格)进行分割标识 print(a.split()) print(type(a.split())) a='www.python.com' # 以.为分割标识符 print(a.split('.')) # 分割一次 print(a.split('.',1)) # 分割两次,取第一个分片(序号为0) print(a.split('.',2)[0]) # 分割两次,并把分割后的三个部分保存到三个变量中 b,c,d=a.split('.',2) print(b) print(type(b)) print('案例') a='http://www.python.com/hjorth/p/5566677.html' print(a.split('//')) print(a.split('//')[1].split('.')) print(a.split('//')[1].split('.')[1]) print('案例2') a='kkkkkkpythonkkkiskkkgoodkk' print(a.split('k')) print(a.split('kk'))

9、count()统计某内容出现的次数
a='Hello word! Hello Python!' print(a.count('H')) # 默认从0开始索引 print(a.count('H',2)) # 设置从2开始索引,有1个H print(a.count('H',13)) # 从13开始,有0个H print(a.count('H',0,100)) # 在0-100内索引 print(a.count('H',1,100)) # 在1-100内索引 print(a.count('th'))

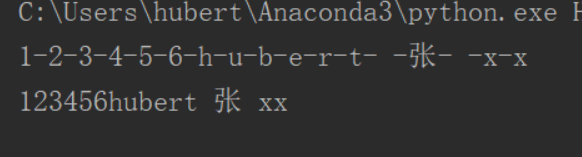
10、join()循环取出所有值并用‘xx’去连接
a='123456hubert 张 xx' print('-'.join(a)) print(''.join(a)) #空字符连接
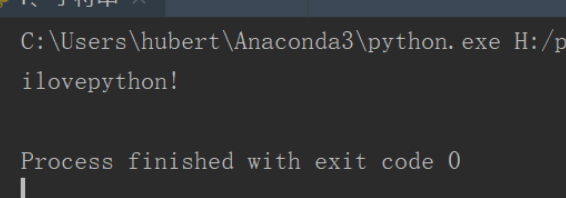
11、replace()是一个替换函数 其使用格式为 变量 .replace('要替换的值','替换后的值')
# 替换空格 a=' i love pyth on !' print(a.replace(' ',''))
2、列表(list)及常用方法
python中重要的数据结构,是一种有序的数据集合
支持增删改查 列表中的数据是可以变化的(数据项可以变化,内存中的地址不会改变)
用[]来表示列表类型,数据项之间用逗号来分割,注意:数据项可以是任何类型的数据
支持索引和切片来进行操作
列表中常用的函数
1、切片(查找,获取)
# li=[] # 空列表 li=[1,2,3,'hubert', '张','HaAJJ',True] print(type(li)) print(li) print(len(li)) str='我喜欢python' print(len(str)) # 切片 print(li[0]) print(li[2:4]) print(li[::-1]) print(li*3) #复制三次
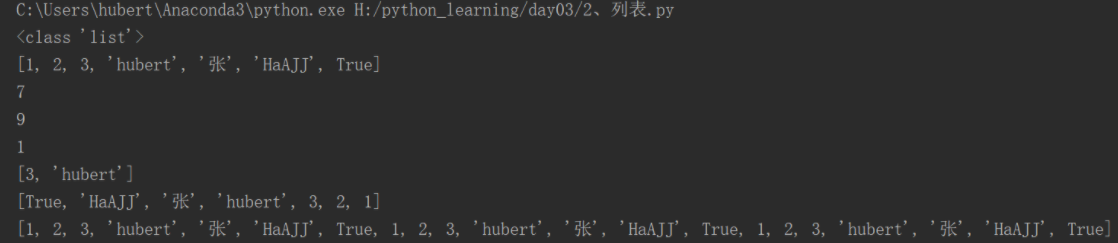
1、append()函数,insert()函数
# append()函数:在后面增加 li=[1,2,3,'hubert', '张','HaAJJ',True] print('增加列表前:',li) li.append(['fff','ddd']) print('增加列表后:',li) li.append(888) print('增加数字:',li) li.append('ioui222') print('增加字符串:',li) # insert()函数:指定插入 li.insert(1,'在1位置插入这句话') print('在1位置插入这句话:',li)

2、extend():批量增加
intdata=range(10) print(type(intdata)) print(intdata) lia=list(intdata) # 强制转换成list print(type(lia)) print(lia) li=[1,2,3,'hubert', '张','HaAJJ',True] print(li) li.extend(lia) # 不能直接写在print里面 print(li) li.extend([11,12,13]) print(li)
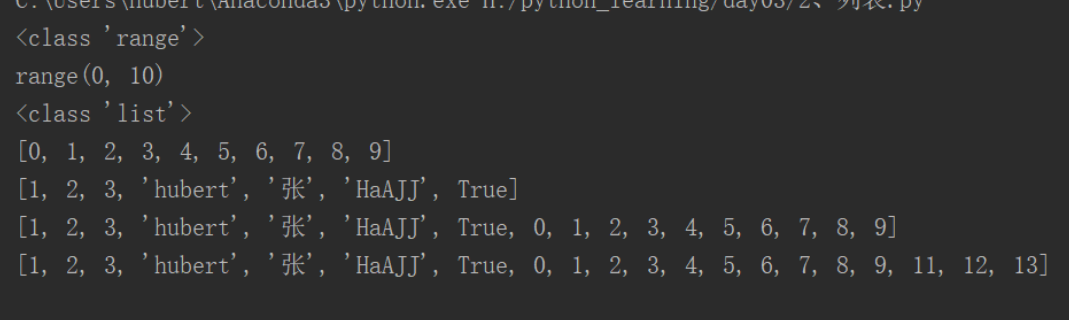
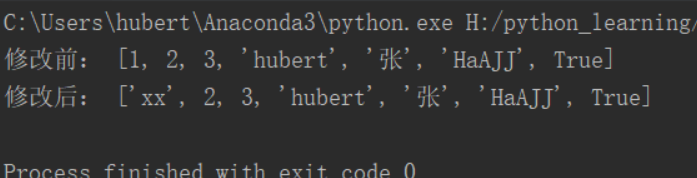
3、修改:通过索引值找到,重新赋值
li=[1,2,3,'hubert', '张','HaAJJ',True] print('修改前:',li) li[0]='xx' print('修改后:',li)
4、删除:del,remove,pop
li=list(range(10,50)) print(li) del li[0] print(li) del li[1:4] #批量删除 print(li) li.remove(20) #移除指定元素 print(li) li.pop(2) # 移除指定项的索引值对应的元素 print(li)

5、反转:reverse
li=list(range(10,50)) print(li) li.reverse() print(li) li=[1,2,3,'hubert', '张','HaAJJ',True] print(li) li.reverse() print(li)

7、排序:sort
sort函数定义:sort(cmp=None, key=None, reverse=False)
cmp:用于比较的函数(大于时返回1,小于时返回-1,等于时返回0),比较什么由key决定,有默认值,迭代集合中的一项;
key:用列表元素的某个属性和函数进行作为关键字,有默认值,迭代集合中的一项;
reverse:排序规则. reverse = True 或者 reverse = False,有默认值。
a = [2, 1, 4, 9, 6] print(a) a.sort() #内置cmp是升序,默认reverse=False print(a) L = [('a', 3), ('d', 2), ('c', 1), ('b', 4)] print(L) a = sorted(L) print(a) b=sorted(L,reverse=True) print(b)

alist = [('2', '3', '10'), ('1', '2', '3'), ('5', '6', '7'), ('2', '5', '10'), ('2', '4', '10')] print(alist) alist.sort() print(alist) # 原始的按照升序 # 多级排序,先按照每个里面的第3个元素排序,然后按照第2个元素排序: alist.sort(key = lambda x:(int(x[2]),int(x[1]))) print(alist)

key负责指定排序的比较顺序,reverse=True表示按照升序,False表示按照降序
3、元组(tuple)及常用方法
是一种不可变的序列,在创建之后不能做任何的修改,因此需要转换为其他格式 (因此不能进行修改,只能进行查找)
用小括号创建元组类型
当元祖中只有一个元素的时候,要加上逗号,不然解释器会当做整型或者其他类型来处理
查询
tupleA=('ABCD','abcd',12,34,'张',[11,22,33],(1,2,3)) print(tupleA) for i in tupleA: print(i,end='') pass print() print(tupleA[2]) print(type(tupleA[2])) # 切片取一个就不是元组类型 print(tupleA[1]) print(type(tupleA[1])) # 切片取一个就不是元组类型 print(tupleA[2:5]) print(type(tupleA[2:4])) # 切片区取个就还是元组 print(tupleA[::-1]) print(tupleA[::-2]) # 表示反转字符串,并步长为2 print(tupleA[::-3]) # 表示反转字符串,并步长为3 print(tupleA[-2:-1:]) print(tupleA[-4:-2:]) print(tupleA[-4:-6:]) print(tupleA[-4:-6:-1])
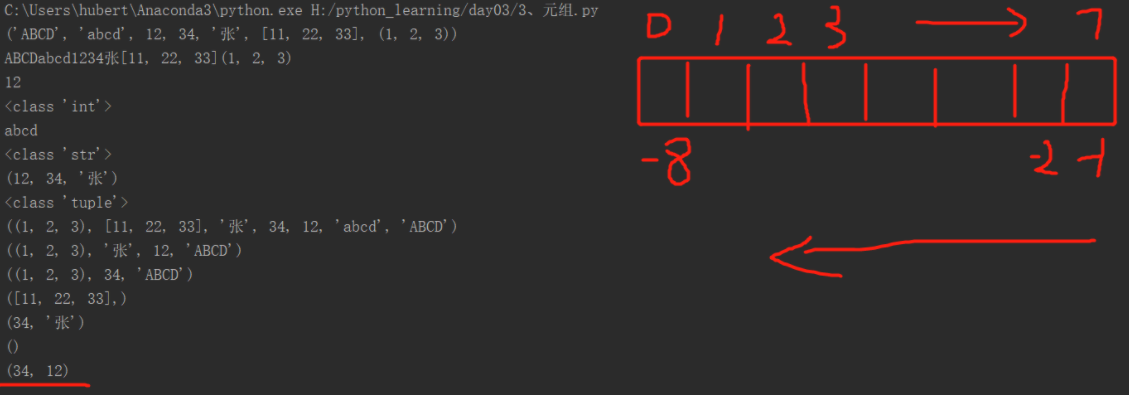
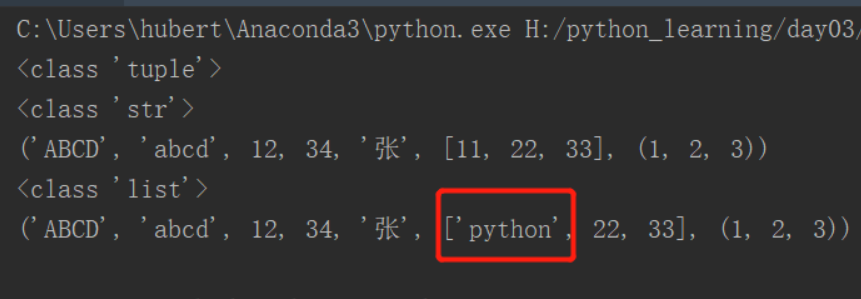
元组中的列表可以被修改(重点)
# 修改 tupleA=('ABCD','abcd',12,34,'张',[11,22,33],(1,2,3)) print(type(tupleA)) print(type(tupleA[0])) print(tupleA) # tupleA[0]='python' # 元组中的字符串不能修改 # tupleA[2]='python' # 元组中的整型不能修改 print(type(tupleA[5])) tupleA[5][0]='python' # 元组中的列表可以修改 print(tupleA)
4、字典(dict)及常用方法
字典不是序列,所以不能通过索引来访问;(是一种无序的键值集合,没有下标)
字典是Python的中重要的一种数据类型,可以存储任意对像。字典是以键值对的形式创建的集合,{'key':'value'}利用大括号包裹,通常使用键来访问,效率极高。
访问值的安全方式get方法,在我们不确定字典中是否存在某个键而又想获取其值时,可以使用get方法,还可以设置默认值。
字典的键(key)不能重复,值(value)可以重复,如果出现重复的键,后者会覆盖前者。
字典的键(key)只能是不可变类型,如数字,字符串,元组。

创建字典
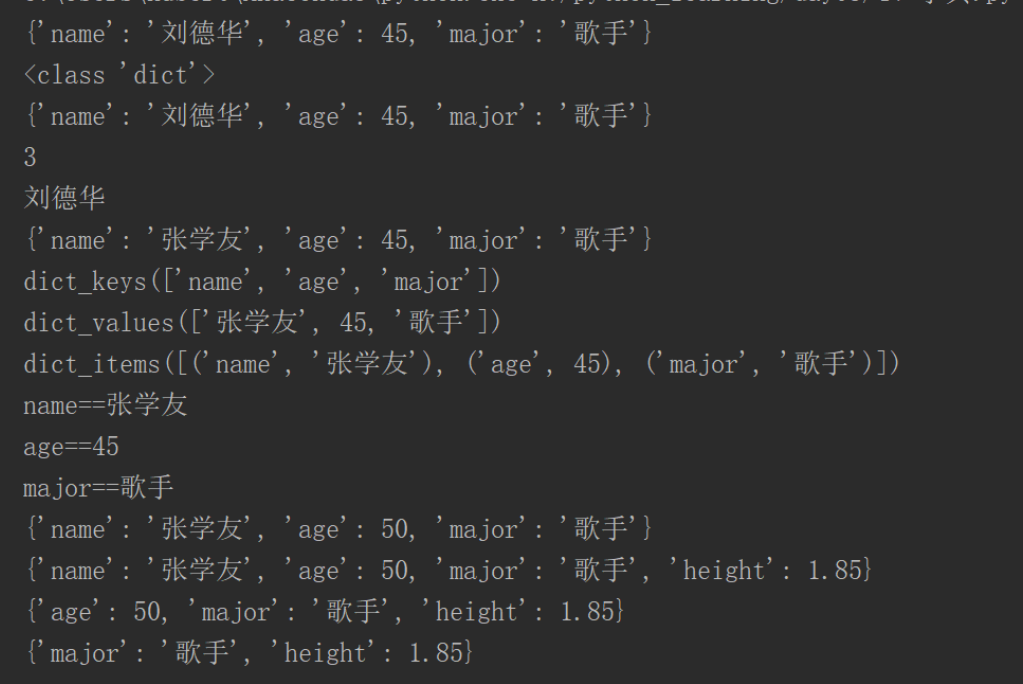
# 创建字典 dictB={'name':'刘德华','age':45,'major':'歌手'} print(dictB) # 字典可以添加 dictA={} # 空字典 dictA['name']='刘德华' dictA['age']=45 dictA['major']='歌手' print(type(dictA)) print(dictA) print(len(dictA)) #一个键值对表示一个长度 # 通过键来查找和获取 print(dictA['name']) # 修改 dictA['name']='张学友' print(dictA) # 获取所有的键 print(dictA.keys()) # 获取所有的值 print(dictA.values()) # 获取所有键值对 print(dictA.items()) for keys,values in dictA.items(): # print('%s==%s'%(keys,values)) print('{}=={}' .format(keys, values)) # 更新(已经存在的更新,不存在的添加) # dictA.update=({'age':50},{'height':1.85}) # 只能一个一个更新 dictA.update({'age':50}) print(dictA) dictA.update({'height':1.85}) print(dictA) # 删除 del dictA['name'] print(dictA) dictA.pop('age') print(dictA)
字典排序
# 字典排序(通过ACCII码) # 按照keys排序 dictA={'name':'刘德华','age':45,'major':'歌手'} print(dictA) print(sorted(dictA.items(),key=lambda d:d[0])) #按照key中的英文来排序,d[0]表示key # 按照values来排序(前提是类型的一样,age中是int其是str) dictA.update({'age':'45'}) print(sorted(dictA.items(),key=lambda d:d[1])) #d[0]表示values

5、共有方法
1、合并:两个相同类型的对象相加操作,会合并两个对象+(字符串,列表,元组)
strA='人生苦短,' strB='我用python!' listA=[1,2,3,'hubert'] listB=[4,5,6,'hubert'] tupleA=('xx',1,2) tupleB=('yy',4,5) print(strA+strB) print(strB+strA) print(listA+listB) print(tupleA+tupleB) # print(strA+listB) # 报错 # print(strA+tupleB) # 报错 # print(tupleA+listB) #报错

2、复制:对象自身按指定次数进行 + 操作*(字符串,列表,元组)
strA='人生苦短,' listA=[1,2,3,'hubert'] tupleA=('xx',1,2) print(strA*3) print(listA*2) print(tupleA*4)

3、判断指定元素是否存在于对象中in(字符串,列表,元组,字典)
strA='人生苦短,我用python' listA=[1,2,3,'hubert'] tupleA=('xx',1,2) print('生' in strA) print('生 我' in strA) #False print('py' in strA) print(',' in strA) print(1 in listA) print('hubert' in listA) print('hu' in listA) # False print('xx' in tupleA) print(1 in tupleA) print('x' in tupleA) # False # 字典判断key在不在 dictA={'name':'刘德华'} print('name' in dictA) print(dictA) print('刘德华' in dictA) # False
