一、Django实现表与表的关联
以图书管理系统为例我们在数据库建立四张表:图书表、出版社表、作者表、作者信息,这里表与标的对应关系如下:
| 表 | 表 | 对应关系 |
|---|---|---|
| 出版社 | 图书 | 一对多 |
| 作者 | 图书 | 多对多 |
| 作者信息 | 作者 | 一对一 |
在Django中创建表与表的外间关系具体程序如下:
class Book(models.Model):
title = models.CharField(max_length=32)
# 小数总共八位 小数占两位
price = models.DecimalField(max_digits=8,decimal_places=2)
# 书跟出版社是一对多 并且书是多的一方 所以外键字段健在书表中
publish = models.ForeignKey(to='Publish') # to用来指代跟哪张表有关系 默认关联的就是表的主键字段
"""
一对多外键字段创建的时候同步到数据中表字段会自动加_id后缀,如果我们手动加了_id orm也会在给我们加一次,所以我们这里不要加_id
"""
# 书跟作者是多对多的关系外键字段建在任意一方都可以,但是建议建在查询频率较高的那一方
author = models.ManyToManyField(to='Author') # django orm会自动帮我们创建书籍和作者的第三张关系表
# author这个字段是一个虚拟字段能在表中展示出来 仅仅只是起到告诉orm建第三表张的关系的作用
class Publish(models.Model):
title = models.CharField(max_length=32)
email = models.EmailField()
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
# 一对一的表关系 外键字段建在任意一方都可以,但是建议建在查询频率较高的那一方
author_detail = models.OneToOneField(to='Author_detail') # fk + unique
"""
一对一外键字段创建的时候同步到数据中表字段会自动加_id后缀,如果我们手动加了_id orm也会在给我们加一次,所以我们这里不要加_id
"""
class Author_detail(models.Model):
phone = models.BigIntegerField()
addr = models.CharField(max_length=32)
这里需要说明:
-
一对一、多对多的表关系外键建立在任意一方都可以,建议建在查询频率高的一方
-
一对多外键字段创建的时候同步到数据中表字段会自动加_id后缀,如果我们手动加了_id orm也会在给我们加一次,所以我们这里不要加_id
-
多对多关系,django orm会自动帮我们创建书籍和作者的第三张关系表
-
#外键的建立 publish = models.ForeignKey(to='Publish') author = models.ManyToManyField(to='Author') author_detail = models.OneToOneField(to='Author_detail')
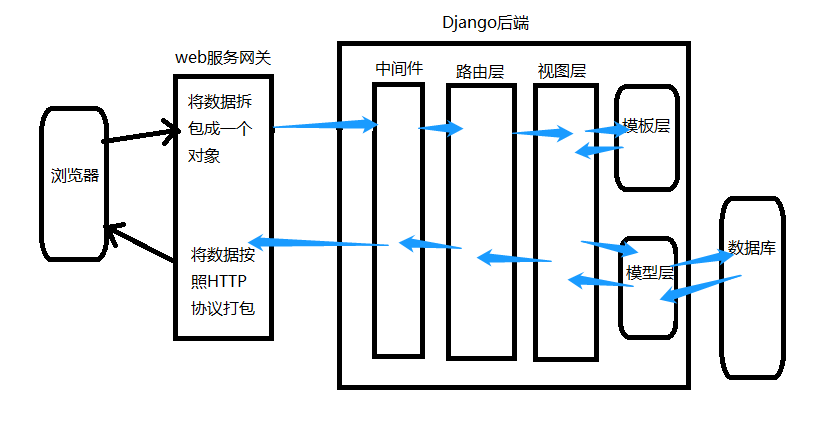
二、Django请求生命周期流程图
三、路由层
3.1路由匹配
url第一个参数是一个正则表达式只要该正则表达式能够匹配到内容,就会立刻执行后面的视图函数 而不再往下继续匹配了,Django中进行路由匹配时先直接对接收到的url进行一次路由匹配,如果匹配不到就在原来的url后面加一个反斜杠然后再进行一次路由匹配。这就是我们通常访问网站时浏览器上一些网站的网址自动加了反斜杠的原因,当然我们可以通过修改配置信息取消这一功能,具体修改方式:将settings里的APPEND_SLASH改为False。
3.2有名分组
会将分组内的正则表达式匹配到的内容当做关键字参数传递给视图函数
url(r'^testadd/(?P<year>d+)/', views.testadd)
#year就是关键字参数的关键字,参数是year匹配到的内容
3.3无名分组
将分组内正则表达式匹配到的内容当做位置参数传递给视图函数如:
url(r'^test/([0-9]{4})/', views.test)
3.4反向解析
反向解析指根据一个别名动态解析出一个结果,该结果可以直接访问对应的url。反向解析的目的是为了解决url接口变动造成的前端后端都要按照变动的接口取修改代码内接口名称的问题。
3.4.1情况一
路由中的正则表达式获取的值是固定的如:
url(r'^home/$', views.home,name='xxx')这时相当于给路由和视图函数起别名。
前端反向解析
{% url 'xxx' %}
后端反向解析
from django.shortcuts import render,HttpResponse,redirect,reverse
url = reverse('xxx')
3.4.2情况二
当正则匹配到的是不确定的内容时,需要我们在程序中指定匹配到的内容是什么时执行代码,如:
url(r'^home/(d+)/', views.home,name='xxx')
前端反向解析
<p><a href="{% url 'xxx' 12 %}">111</a></p>
<p><a href="{% url 'xxx' 1324 %}">111</a></p>
<p><a href="{% url 'xxx' 14324 %}">111</a></p>
<p><a href="{% url 'xxx' 1234 %}">111</a></p>
<p><a href="{% url 'xxx' 12 %}">111</a></p>
后端反向解析
url = reverse('xxx',args=(1,))
url1 = reverse('xxx',args=(3213,))
url2 = reverse('xxx',args=(2132131,))
3.4.3情况三
有名分组的反向解析,在解析的时候需要指定正则匹配的内容,这点和无名分组相似。代码如下:
url(r'^home/(?P<year>d+)/', views.home,name='xxx')
前端反向解析
写法1:与无名分组相同
<p><a href="{% url 'xxx' 12 %}">111</a></p>
写法2:
<p><a href="{% url 'xxx' year=1232 %}">111</a></p>
后端反向解析
写法1:与无名分组相同
url = reverse('xxx',args=(1,))
写法2:
url = reverse('xxx',kwargs={'year':213123})
例子(伪代码):
url(r'^edit_user/(d+)/',views.edit_user,name='edit')
def edit_user(request,edit_id):
# edit_id就是用户想要编辑数据主键值
pass
{% for user_obj in user_list %}
<a href='/edit_user/{{user_obj.id}}/'>编辑</a>
<a href='{% url 'edit' user_obj.id %}'>编辑</a>
{% endfor %}
3.5路由分发
当一个项目比较大时,为了简化项目文件的路由匹配,在Django中所有的app都建立自己独立的urls.py,这时总路由不在做匹配的活,而仅仅是做任务分发(请求来了之后总路由不做对应关系,只负责询问你要访问哪个app的功能然后将请求转发给对应的app的urls处理)
配置方法:
总路由
1.在总urls中导入个app的urls
from app01 import urls as app01_urls
from app02 import urls as app02_urls
2.进行如下配置
urlpatterns = [
url(r'^admin/', admin.site.urls), # url第一个参数是一个正则表达式
# 路由分发
url(r'^app01/',include(app01_urls)), # 路由分发需要注意的实现 就是总路由里面不能以$结尾
url(r'^app02/',include(app02_urls)),
]
如果向下面这样写,可以不用导入模块
urlpatterns = [
url(r'^app01/',include('app01.urls')),
url(r'^app02/',include('app02.urls'))
]
子路由
from django.conf.urls import url
from app01 import views
urlpatterns = [
url('^reg/',views.reg)
]
3.6名称空间
当多个app出现别名其重复的情况时,在做路由分发的时候可以给每一个app创建一个名称空间,这样反向解析的时候就会选择去对应的名称空间去查找。
url(r'^app01/',include('app01.urls',namespace='app01')),
url(r'^app02/',include('app02.urls',namespace='app02'))
使用的时候如:
# 后端
print(reverse('app01:reg'))
print(reverse('app02:reg'))
# 前端
<a href="{% url 'app01:reg' %}"></a>
<a href="{% url 'app02:reg' %}"></a>
其实关于别名重复的问题还有更好的解决方法,就是起名字的时候直接把app的名字直接加上作为前缀就可以了,如:app01_rep。
3.7伪静态
伪静态就是将一个动态网页伪装成一个静态网页,以此来提高搜索引擎SEO的查询频率和收藏力度。(静态网页会优先被收藏)
伪静态就是让访问的网页后缀名是.html 我们的作法是在url正则式后面直接加.html。
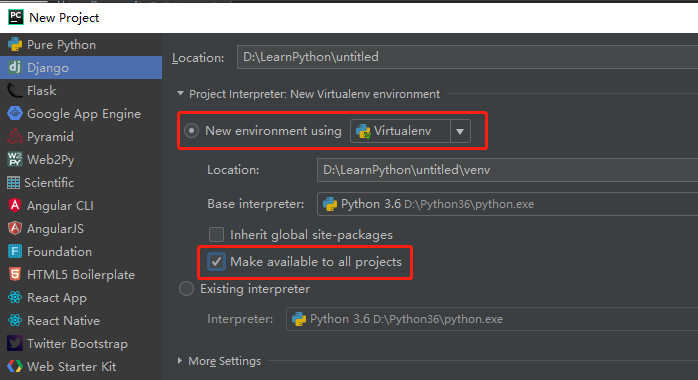
3.8虚拟环境
虚拟环境的目的是给每一个项目创建一个只装备该项目所需要的模块的运行环境,每创建一个虚拟环境类似于重新下载了一个纯净的python解释器。
创建步骤:
1.创建项目的时候进行如下选择:
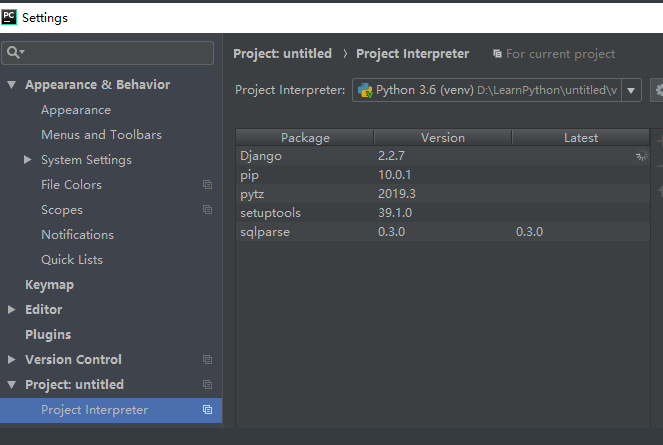
2.查看是否使用了虚拟环境
3.9Django1.x和2.x的版本的路由层区别
1.Django2.x中默认的url通过path接收,path的第一个输入值不是正则表达式,里面写的是什么就按什么匹配。
urlpatterns = [
path('admin/', admin.site.urls),
]
2.Django2.x中的re_path对应的是Django1.x中的url功能相同。
3.path提供了五种转换器,能够将匹配到的数据转成对应的数据类型而且还支持自定义转换器,用于解决数据类型转换问题和正则表达式冗余问题。
path的具体使用方法如下:
from django.urls import path,re_path
from app01 import views
urlpatterns = [
path('articles/<int:year>/', views.year_archive), # <int:year>相当于一个有名分组,其中int是django提供的转换器,相当于正则表达式,专门用于匹配数字类型,而year则是我们为有名分组命的名,并且int会将匹配成功的结果转换成整型后按照格式(year=整型值)传给函数year_archive
#用一个int转换器可以替代多处正则表达式
path('articles/<int:article_id>/detail/', views.detail_view),
path('articles/<int:article_id>/edit/', views.edit_view),
path('articles/<int:article_id>/delete/', views.delete_view),
]
#1、path与re_path或者1.0中的url的不同之处是,传给path的第一个参数不再是正则表达式,而是一个完全匹配的路径,相同之处是第一个参数中的匹配字符均无需加前导斜杠
#2、使用尖括号(<>)从url中捕获值,相当于有名分组
#3、<>中可以包含一个转化器类型(converter type),比如使用 <int:name> 使用了转换器int。若果没有转换器,将匹配任何字符串,当然也包括了 / 字符
path默认的五种转换器
str,匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式
int,匹配正整数,包含0。
slug,匹配字母、数字以及横杠、下划线组成的字符串。
uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
path,匹配任何非空字符串,包含了路径分隔符(/)
自定义转换器示例:
-
在app01下新建文件path_ converters.py,文件名可以随意命名
class MonthConverter: regex='d{2}' # 属性名必须为regex def to_python(self, value): return int(value) def to_url(self, value): return value # 匹配的regex是两个数字,返回的结果也必须是两个数字 -
在urls.py中,使用 register_converter 将其注册到URL配置中:
from django.urls import path,register_converter from app01.path_converts import MonthConverter register_converter(MonthConverter,'mon') from app01 import views urlpatterns = [ path('articles/<int:year>/<mon:month>/<slug:other>/', views.article_detail, name='aaa'), ] -
views.py中的视图函数article_detail
from django.shortcuts import render,HttpResponse,reverse def article_detail(request,year,month,other): print(year,type(year)) print(month,type(month)) print(other,type(other)) print(reverse('xxx',args=(1988,12,'hello'))) # 反向解析结 果/articles/1988/12/hello/ return HttpResponse('xxxx')