接着这篇文章[js高手之路]Node.js+jade抓取博客所有文章生成静态html文件继续,在这篇文章中实现了采集与静态文件的生成,在实际的采集项目中, 应该是先入库再选择性的生成静态文件。
那么我选择的数据库是mongodb,为什么用这个数据库,因为这个数据库是基于集合,数据的操作基本是json,与dom模块cheerio具有非常大的亲和力,cheerio处理过滤出来的数据,可以直接插入mongodb,不需要经过任何的处理,非常的便捷,当然跟node.js的亲和力那就不用说了,更重要的是,性能很棒。这篇文章我就不具体写mongodb的基本用法,到时候会另起文章从0开始写mongodb基本常用用法.先看下入库的效果与生成静态文件的效果:
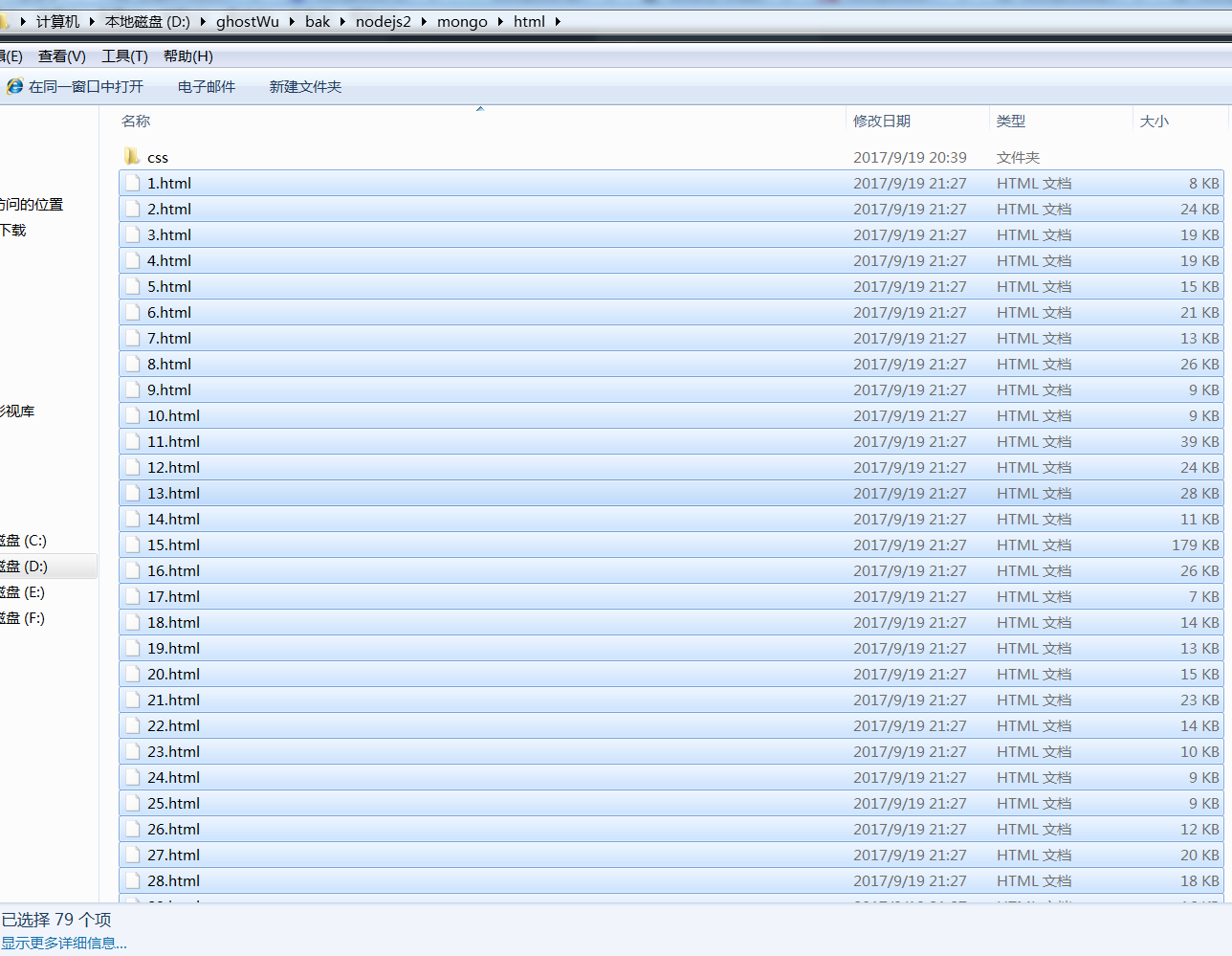

我在这个阶段,把爬虫分离成2个模块,采集入库( crawler.js ), 生成静态文件(makeHtml.js).
crawler.js:
1 var http = require('http'); 2 var cheerio = require('cheerio'); 3 var mongoose = require('mongoose'); 4 mongoose.Promise = global.Promise; 5 var DB_URL = 'mongodb://localhost:27017/crawler'; 6 7 var aList = []; //博客文章列表信息 8 var aUrl = []; //博客所有的文章url 9 10 var db = mongoose.createConnection(DB_URL); 11 db.on('connected', function (err) { 12 if (err) { 13 console.log(err); 14 } else { 15 console.log('db connected success'); 16 } 17 }); 18 var Schema = mongoose.Schema; 19 var arcSchema = new Schema({ 20 id: Number, //文章id 21 title: String, //文章标题 22 url: String, //文章链接 23 body: String, //文章内容 24 entry: String, //摘要 25 listTime: Date //发布时间 26 }); 27 var Article = db.model('Article', arcSchema); 28 29 function saveArticle(arcInfo) { 30 var arcModel = new Article(arcInfo); 31 arcModel.save(function (err, result) { 32 if (err) { 33 console.log(err); 34 } else { 35 console.log(`${arcInfo['title']} 插入成功`); 36 } 37 }); 38 } 39 40 function filterArticle(html) { 41 var $ = cheerio.load(html); 42 var arcDetail = {}; 43 var title = $("#cb_post_title_url").text(); 44 var href = $("#cb_post_title_url").attr("href"); 45 var re = //(d+).html/; 46 var id = href.match(re)[1]; 47 var body = $("#cnblogs_post_body").html(); 48 return { 49 id: id, 50 title: title, 51 url: href, 52 body: body 53 }; 54 } 55 56 function crawlerArc(url) { 57 var html = ''; 58 var str = ''; 59 var arcDetail = {}; 60 http.get(url, function (res) { 61 res.on('data', function (chunk) { 62 html += chunk; 63 }); 64 res.on('end', function () { 65 arcDetail = filterArticle(html); 66 saveArticle(arcDetail); 67 if ( aUrl.length ) { 68 setTimeout(function () { 69 if (aUrl.length) { 70 crawlerArc(aUrl.shift()); 71 } 72 }, 100); 73 }else { 74 console.log( '采集任务完成' ); 75 return; 76 } 77 }); 78 }); 79 } 80 81 function filterHtml(html) { 82 var $ = cheerio.load(html); 83 var arcList = []; 84 var aPost = $("#content").find(".post-list-item"); 85 aPost.each(function () { 86 var ele = $(this); 87 var title = ele.find("h2 a").text(); 88 var url = ele.find("h2 a").attr("href"); 89 ele.find(".c_b_p_desc a").remove(); 90 var entry = ele.find(".c_b_p_desc").text(); 91 ele.find("small a").remove(); 92 var listTime = ele.find("small").text(); 93 var re = /d{4}-d{2}-d{2}s*d{2}[:]d{2}/; 94 listTime = listTime.match(re)[0]; 95 96 arcList.push({ 97 title: title, 98 url: url, 99 entry: entry, 100 listTime: listTime 101 }); 102 }); 103 return arcList; 104 } 105 106 function nextPage(html) { 107 var $ = cheerio.load(html); 108 var nextUrl = $("#pager a:last-child").attr('href'); 109 if (!nextUrl) return getArcUrl(aList); 110 var curPage = $("#pager .current").text(); 111 if (!curPage) curPage = 1; 112 var nextPage = nextUrl.substring(nextUrl.indexOf('=') + 1); 113 if (curPage < nextPage) crawler(nextUrl); 114 } 115 116 function crawler(url) { 117 http.get(url, function (res) { 118 var html = ''; 119 res.on('data', function (chunk) { 120 html += chunk; 121 }); 122 res.on('end', function () { 123 aList.push(filterHtml(html)); 124 nextPage(html); 125 }); 126 }); 127 } 128 129 function getArcUrl(arcList) { 130 for (var key in arcList) { 131 for (var k in arcList[key]) { 132 aUrl.push(arcList[key][k]['url']); 133 } 134 } 135 crawlerArc(aUrl.shift()); 136 } 137 138 var url = 'http://www.cnblogs.com/ghostwu/'; 139 crawler(url);
其他的核心模块没有怎么改动,主要增加了数据库连接,数据库创建,集合创建( 集合相当于关系型数据库中的表 ),Schema( 相当于关系型数据库的表结构 ).
mongoose操作数据库( save:插入数据 ).分离了文件生成模块.
makeHtml.js文件
1 var fs = require('fs'); 2 var jade = require('jade'); 3 4 var mongoose = require('mongoose'); 5 mongoose.Promise = global.Promise; 6 var DB_URL = 'mongodb://localhost:27017/crawler'; 7 8 var allArc = []; 9 var count = 0; 10 11 var db = mongoose.createConnection(DB_URL); 12 db.on('connected', function (err) { 13 if (err) { 14 console.log(err); 15 } else { 16 console.log('db connected success'); 17 } 18 }); 19 var Schema = mongoose.Schema; 20 var arcSchema = new Schema({ 21 id: Number, //文章id 22 title: String, //文章标题 23 url: String, //文章链接 24 body: String, //文章内容 25 entry: String, //摘要 26 listTime: Date //发布时间 27 }); 28 var Article = db.model('Article', arcSchema); 29 30 function makeHtml(arcDetail) { 31 str = jade.renderFile('./views/layout.jade', arcDetail); 32 ++count; 33 fs.writeFile('./html/' + count + '.html', str, function (err) { 34 if (err) { 35 console.log(err); 36 } 37 console.log( `${arcDetail['id']}.html创建成功` + count ); 38 if ( allArc.length ){ 39 setTimeout( function(){ 40 makeHtml( allArc.shift() ); 41 }, 100 ); 42 } 43 }); 44 } 45 46 function getAllArc(){ 47 Article.find( {}, function( err, arcs ){ 48 allArc = arcs; 49 makeHtml( allArc.shift() ); 50 } ).sort( { 'id' : 1 } ); 51 } 52 getAllArc();