Supervised Contrastive Learning
对比学习是自监督的,这篇文章将其扩展至强监督。
Introduction
业界广泛使用cross-entropy作为loss
许多工作尝试改进cross-entropy,但是,往往在实际应用中,特别是大数据集上,效果并不好
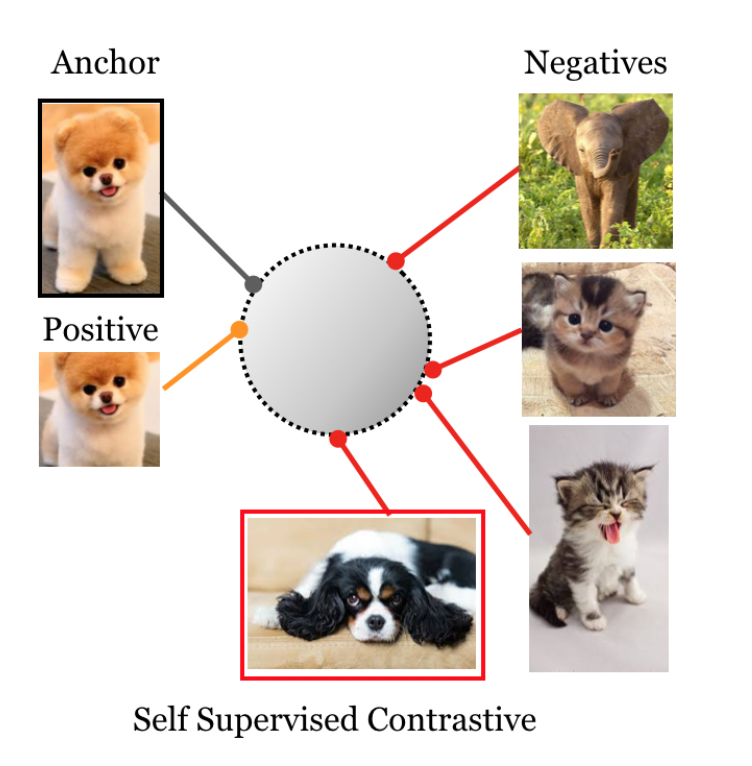
许多工作在尝试使用对比学习,他们用augmented data作为正样本,其他作为负样本
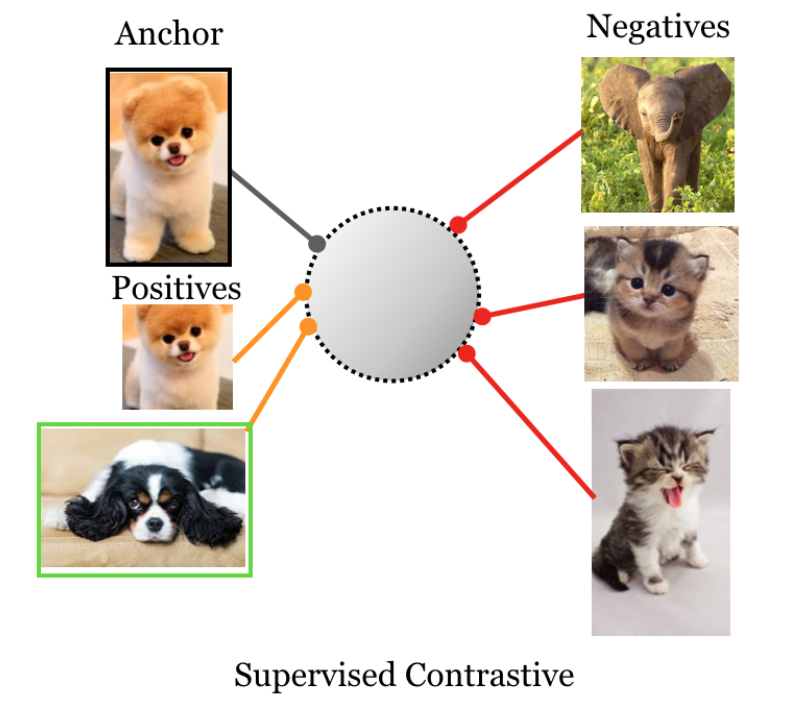
这篇文章提出了一个新的loss,把对比学习扩展至了强监督
利用强监督的label,现在同一类物体的normalized embeddings会距离更近
Method
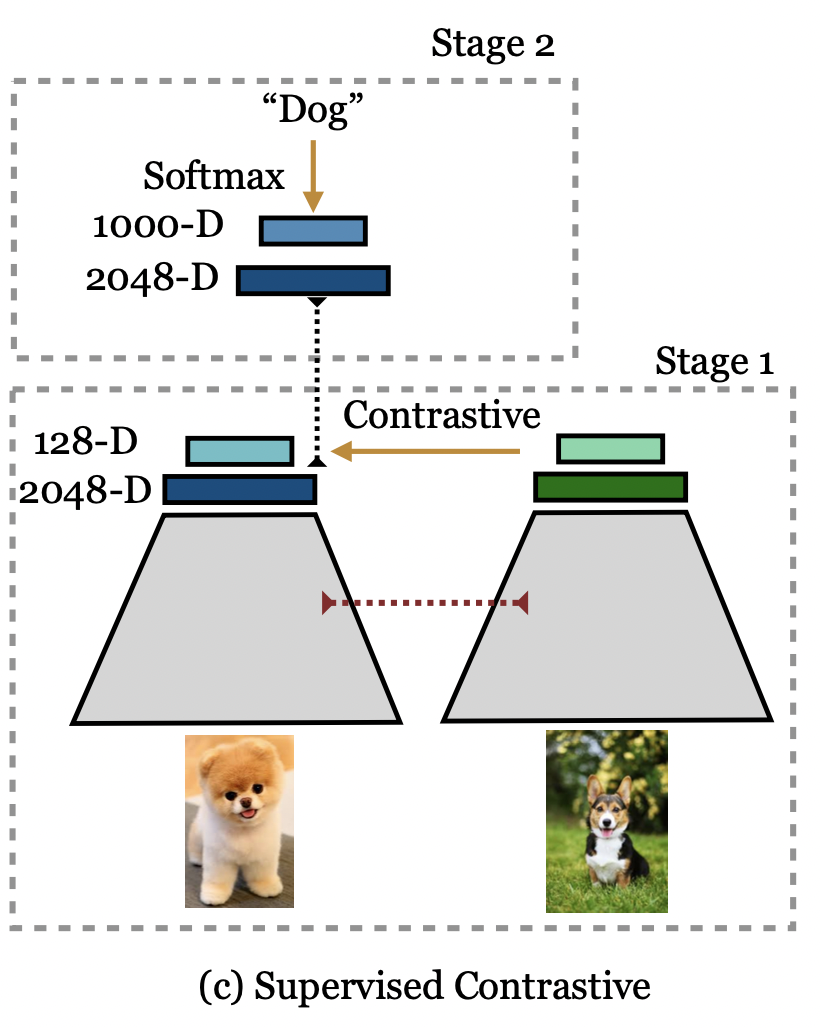
Representation Learning Framework
Data Augmentation Module \(Aug(\cdot)\)
对于每个输入 \(\mathbf{x}\), augment 两组数据
Encoder Network \(Enc(\cdot)\)
Encoder network maps \(\mathbf{x}\) to a vector \(\mathbf{r}\).
Both augmented samples are inputed into a encoder to get a pair of representation vectors, which are then normalized to unit vectors.
Projection Network \(Proj(\cdot)\)
Projection network maps \(\mathbf{r}\) to a vector \(\mathbf{z}\). (2048 to 128)
The output \(\mathbf{z}\) is also normalized.
Contrastive Loss Functions
对每个sample,augment得到两组samples,后者称为multiviewed batch
Self-Supervised Contrastive Loss
自监督的对比学习Loss是这样的
其中\(I\)为\({1,2,\cdots,2N}\),表示augmented data,\(j(i)\)表示和\(i\)同源的另一组augmented data,\(A(i)\)为\(I - \{i\}\),\(z_i=Proj(Enc(\widetilde {x_i}))\)
也就是说,\(i\)是anchor,\(j(i)\)是正样本,其余都认为是负样本
Supervised Contrastive Loss
强监督要解决的问题是,利用label,把同类的物体拉近
给出两种最直接的解决方案
这里\(P(i)\)表示\(\{p\in A(i)| \widetilde y_p = \widetilde {y}_i\}\),也就是\(i\)同类的所有样本,正样本集
这里的in和out,区分求和\(\sum_{p\in P(i)}\)在log内还是外
这两个loss,都具有如下性质
- 对任意数量的正样本都适用
- 负样本越多,对比效果越好
- 挖掘强正负样本的能力?
这两个loss不完全一样,不等式证得\(\mathcal L_{in}^{sup} \le \mathcal L_{out}^{sup}\),out是更好的loss

作者认为,in的结构不适合训练,out的normalization在log外面,有更强的去bias能力
Experiments
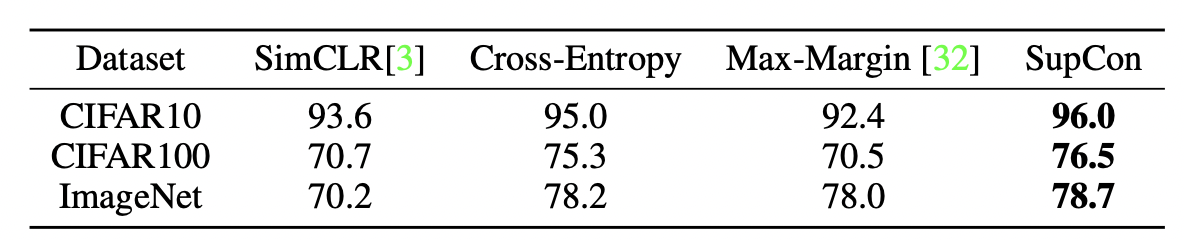
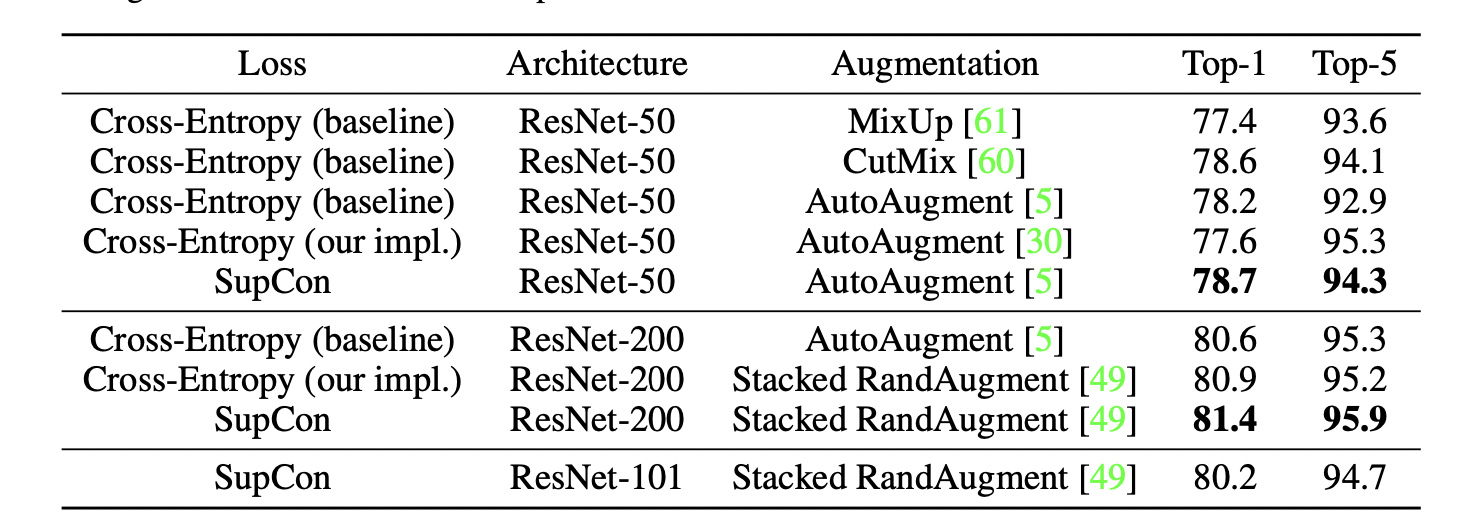
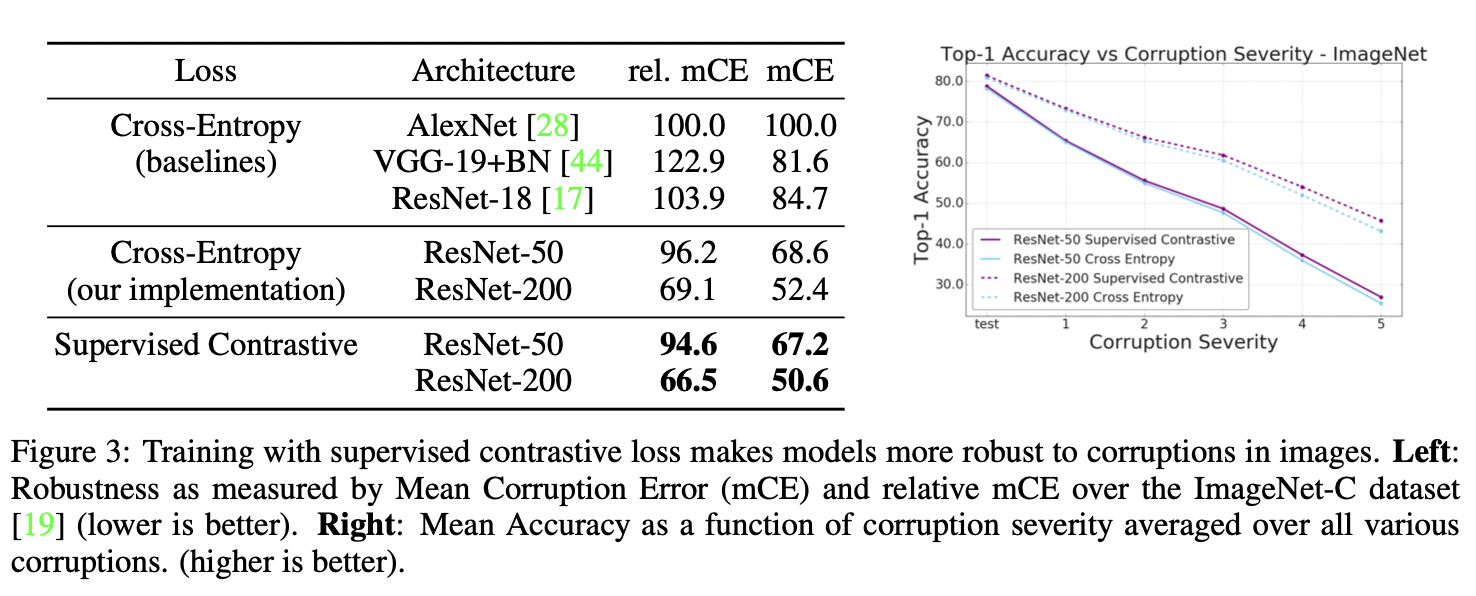
对坏标签也有很robust