摘自https://www.cnblogs.com/duaimili/p/10275728.html
众所周知,程序的性能好坏影响着用户体验。所以性能是留住用户很重要的一环。Python 语言虽然能做很多事情,但是有一个不足之处,那就是执行效率和性能不够理想。
因此,更有必要进行一定的代码优化来提高 Python 程序的执行效率。本文章主要是输出自己在 Python 程序优化的经验。
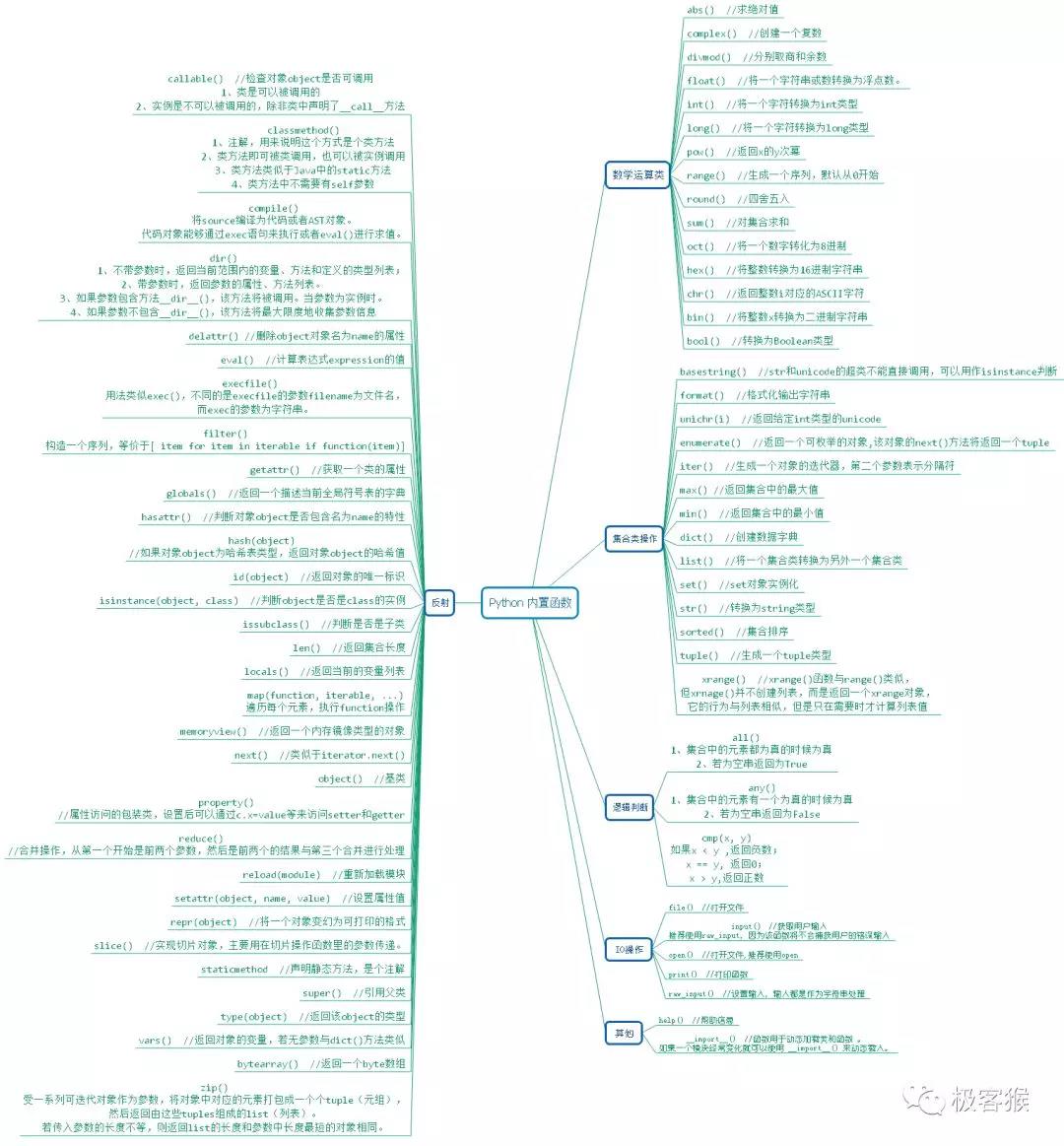
01尽量使用内置函数
Python 的标准库中有很多内置函数,它们的运行效率都很高。因为很多标准库是使用 C 语言编写的。Pyhton 的内置函数有:
02拼接字符串
运算符 "+" 不仅能用于加法运算,还能做字符串连接。但是这种效率不是很高。在 Python 中,字符串变量在内存中是不可变的。如果使用 "+" 拼接字符串,内存会先创建一个新字符串,然后将两个旧字符串拼接,再复制到新字符串。推荐使用以下方法:
-
使用 "%" 运算符连接
这种方式有点像 C 语言中 printf 函数的功能,使用 "%s" 来表示字符串类型参数,再用 "%" 连接一个字符串和一组变量。
1 fir = 'hello' 2 sec = 'monkey' 3 result = '%s, %s' % (fir, sec) 4 print(result)
-
使用 format() 格式化连接
这种格式化字符串函数是 Python 特有的,属于高级用法。因为它威力强大,不仅支持多种参数类型,还支持对数字格式化。
1 fir = 'hello'
2 sec = 'monkey'
3 result = '{}, {}'.format(fir, sec)
4 print(result)
上述代码使用隐式的位置参数,format() 还能显式指定参数所对应变量的位置。
1 fir = 'hello'
2 sec = 'monkey'
3 result = '{1}, {0}'.format(fir, sec)
4 print(result)
-
使用 join() 方式
这种算是技巧性办法。join() 方法通常是用于连接列表或元组中的元素。
1 list = ['1', '2', '3'] 2 result = '+'.join(list) 3 print(result)
03使用 generator
generator 翻译成中文是生成器。生成器也是一种特殊迭代器。它其实是生成器函数返回生成器的迭代。生成器算是 Python 非常棒的特性。它的出现能帮助大大节省些内存空间。
假如我们要生成从 1 到 10 这 10 个数字,采用列表的方式定义,会占用 10 个地址空间。采用生成器,只会占用一个地址空间。因为生成器并没有把所有的值存在内存中,而是在运行时生成值。所以生成器只能访问一次。
1 # 创建一个从包含 1 到 10 的生成器 2 gen = (i for i in range(10)) 3 print(gen) 4 for i in gen: 5 print(i)
04死循环
虽然使用While True和while 1都能实现死循环,但是while 1是单步运算,所以效率会高一点。
1 # 推荐 2 while 1: 3 # todo list 4 5 while True: 6 # todo list
05巧用多重赋值
交换将两个变量的值,我们会立马想到应用一个第三方变量的方法。
1 # 将 a 和 b 两个值互换 2 temp = a 3 a = b 4 b = temp
Python 素有优雅的名声,所以有一个更加优雅又快速的方法,那就是多重赋值。
1 # 将 a 和 b 两个值互换 2 a, b = b, a
06列表的插入与排序
Python 标准库中有个 bisect 模块是内置模块,它实现了一个算法用于插入元素到有序列表。在一些情况下,这比反复排序列表或构造一个大的列表再排序的效率更高。

1 import bisect 2 3 L = [1,3,3,6,8,12,15] 4 x = 3 5 6 x_insert_point = bisect.bisect_left(L, x) 7 # 在 L 中查找 x,x 存在时返回 x 左侧的位置,x 不存在返回应该插入的位置 8 # 这是3存在于列表中,返回左侧位置1 9 print(x_insert_point) 10 11 x_insert_point = bisect.bisect_right(L, x) 12 # 在 L 中查找 x,x 存在时返回x右侧的位置,x 不存在返回应该插入的位置 13 # 这是3存在于列表中,返回右侧位置3 14 print(x_insert_point) 15 16 x_insort_left = bisect.insort_left(L, x) 17 #将 x 插入到列表 L 中,x 存在时插入在左侧 18 print(L) 19 20 x_insort_rigth = bisect.insort_right(L, x) 21 #将 x 插入到列表L中,x 存在时插入在右侧 22 print(L)
07尽量使用局部变量
Python 检索局部变量比检索全局变量快。因此, 尽量少用 "global" 关键字。