数据库导入导出命令
1.导出整个数据库 mysqldump -u用户名 -p密码 数据库名 > 导出的文件名 例如:C:Usersjack> mysqldump -uroot -pmysql sva_rec > e:sva_rec.sql 2.导出一个表,包括表结构和数据 mysqldump -u用户名 -p 密码 数据库名 表名> 导出的文件名 例如:C:Usersjack> mysqldump -uroot -pmysql sva_rec date_rec_drv> e:date_rec_drv.sql 3.导出一个数据库结构 例如:C:Usersjack> mysqldump -uroot -pmysql -d sva_rec > e:sva_rec.sql 4.导出一个表,只有表结构 mysqldump -u用户名 -p 密码 -d数据库名 表名> 导出的文件名 例如:C:Usersjack> mysqldump -uroot -pmysql -d sva_rec date_rec_drv> e:date_rec_drv.sql 5.导入数据库 常用source 命令 进入mysql数据库控制台, 如mysql -u root -p mysql>use 数据库 然后使用source命令,后面参数为脚本文件(如这里用到的.sql) mysql>source d:wcnc_db.sql
导入sql文件
可以使用Navicat Premium 工具的导入sql功能将表导入数据库,mysql和Oracle都适用
数据库优化方案
https://www.cnblogs.com/luokakale/p/7242839.html(详细案例)
总体思路从以下几个方面: 1、选取最适用的字段属性 2、使用连接(JOIN)来代替子查询(Sub-Queries) 3、使用联合(UNION)来代替手动创建的临时表 4、事务(当多个用户同时使用相同的数据源时,它可以利用锁定数据库的方法来为用户提供一种安全的访问方式,这样可以保证用户的操作不被其它的用户所干扰) 5.锁定表(有些情况下我们可以通过锁定表的方法来获得更好的性能) 6、使用外键(锁定表的方法可以维护数据的完整性,但是它却不能保证数据的关联性。这个时候我们就可以使用外键) 7、使用索引 8、优化的查询语句(绝大多数情况下,使用索引可以提高查询的速度,但如果SQL语句使用不恰当的话,索引将无法发挥它应有的作用)
什么是读写分离?
简述流程
1.数据库服务器搭建主集群一主一从,一主多从都可以 2.数据库主机负责读写操作,从机只负责读操作 3.数据库主机通过复制将数据同步到从机,每台数据服务器都存储了所有的业务
4.数据业务服务器将写操作发给数据库主机,将操作发给数据库从机
MySQL Proxy最强大的一项功能是实现“读写分离(Read/Write Splitting)”。基本的原理是让主数据库处理事务性查询,而从数据库处理SELECT查询。数据库复制被用来把事务性查询导致的变更同步到集群中的从数据库。 当然,主服务器也可以提供查询服务。使用读写分离最大的作用无非是环境服务器压力。可以看下这张图:
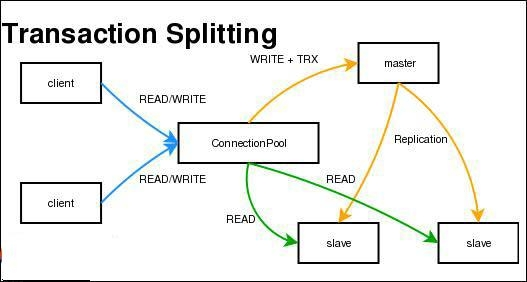
读写分离的好处
1、增加冗余
2、增加了机器的处理能力
3、对于读操作为主的应用,使用读写分离是最好的场景,因为可以确保写的服务器压力更小,而读又可以接受点时间上的延迟。
读写分离提高性能之原因
1、物理服务器增加,负荷增加
2、主从只负责各自的写和读,极大程度的缓解X锁和S锁争用
3、从库可配置myisam引擎,提升查询性能以及节约系统开销
4、从库同步主库的数据和主库直接写还是有区别的,通过主库发送来的binlog恢复数据,但是,最重要区别在于主库向从库发送binlog是异步的,从库恢复数据也是异步的
5、读写分离适用与读远大于写的场景,如果只有一台服务器,当select很多时,update和delete会被这些select访问中的数据堵塞,等待select结束,并发性能不高。 对于写和读比例相近的应用,应该部署双主相互复制
6、可以在从库启动是增加一些参数来提高其读的性能,例如--skip-innodb、--skip-bdb、--low-priority-updates以及--delay-key-write=ALL。当然这些设置也是需要根据具体业务需求来定得,不一定能用上
7、分摊读取。假如我们有1主3从,不考虑上述1中提到的从库单方面设置,假设现在1分钟内有10条写入,150条读取。那么,1主3从相当于共计40条写入,而读取总数没变,因此平均下来每台服务器承担了10条写入和50条读取(主库不承担读取操作)。因此,虽然写入没变,但是读取大大分摊了,提高了系统性能。另外,当读取被分摊后,又间接提高了写入的性能。所以,总体性能提高了,说白了就是拿机器和带宽换性能。MySQL官方文档中有相关演算公式:官方文档 见6.9FAQ之“MySQL复制能够何时和多大程度提高系统性能”
8、MySQL复制另外一大功能是增加冗余,提高可用性,当一台数据库服务器宕机后能通过调整另外一台从库来以最快的速度恢复服务,因此不能光看性能,也就是说1主1从也是可以的。
读写分离示意图
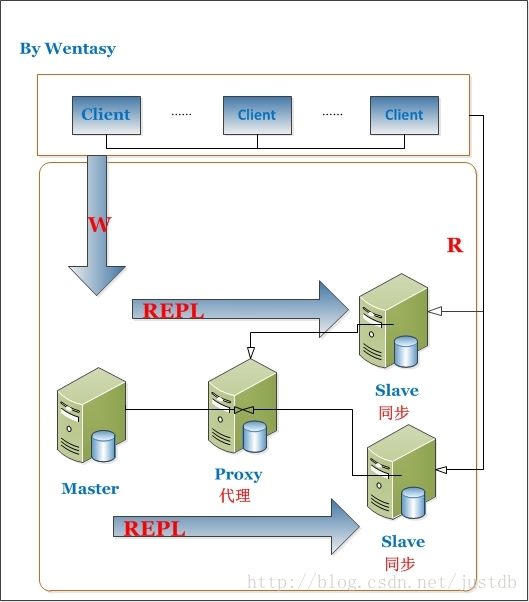
本文转载自https://www.cnblogs.com/zhuifeng-mayi/p/9296498.html