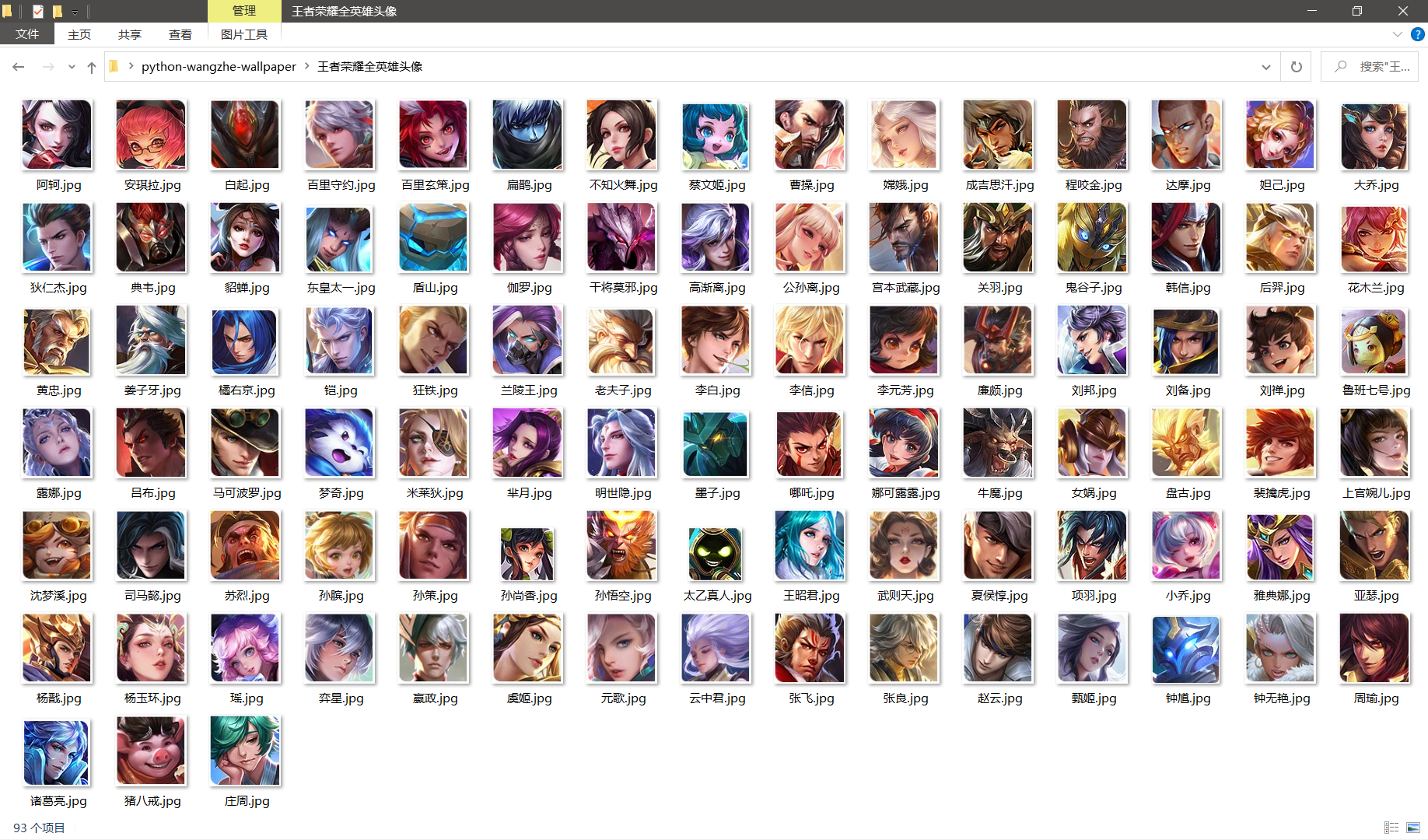
成果展示
目标网址
依赖模块
beautifulsoup4:用于网页元素审查和定位。
pip install beautifulsoup4
lxml:用于网页文档高速解析。
pip install lxml
requests:用于发送和接收网络请求。
pip install requests
完整代码
import concurrent.futures as cf
from bs4 import BeautifulSoup
import os, time, requests
class HeroDownloader(object):
# 创建头像保存文件夹
def __init__(self):
self.root = './heros/'
if not os.path.exists(self.root):
os.mkdir(self.root)
else:
pass
self.site = 'https://pvp.qq.com/web201605/herolist.shtml'
# 单张头像下载
def down(self, name, url):
try:
res = requests.get(url)
with open(name, 'wb') as f:
f.write(res.content)
except Exception as e:
print(e)
# 进度条打印
def show(self, num, _sum, runTime):
barLen = 20 # 进度条的长度
perFin = num/_sum
numFin = round(barLen*perFin)
numNon = barLen-numFin
leftTime = (1-perFin)*(runTime/perFin)
print(
f"{num:0>{len(str(_sum))}}/{_sum}",
f"|{'█'*numFin}{' '*numNon}|",
f"PROCESS: {perFin*100:.0f}%",
f"RUN: {runTime:.0f}S",
f"ETA: {leftTime:.0f}S",
end='
'
)
# 多线程
def main(self):
resp = requests.get(self.site)
soup = BeautifulSoup(resp.content, 'lxml')
hero = soup.select('div.herolist-content li a img') # 头像定位
total = len(hero) # 总的头像个数 (截至到2020/12/09, 王者荣耀正式服共有93名英雄)
count = 0
with cf.ThreadPoolExecutor() as tp:
futures = []
t1 = time.time()
for item in hero:
alt = item['alt']
src = item['src']
name = self.root+alt+'.jpg' # 图片名
url = 'https:'+src # 图片url
future = tp.submit(self.down, name, url)
futures.append(future)
for future in cf.as_completed(futures):
count += 1
t2 = time.time()
self.show(count, total, t2-t1)
print()
if __name__ == "__main__":
HeroDownloader().main()
进度打印
93/93 |████████████████████| PROCESS: 100% RUN: 2S ETA: 0S