-
引子
-
并发编程
-
socketserver模块实现并发
-
基于TCP协议的套接字---支持并发
-
基于UDP协议的套接字---支持并发
-
操作系统
-
进程相关概念
-
开启进程的两种方式
-
进程之间内存空间彼此隔离
-
进程对象的方法
-
socketserver模块实现并发
基于tcp的套接字,关键就是两个循环,一个链接循环,一个通信循环
socketserver模块中分两大类:server类(解决链接问题)和request类(解决通信问题)
-
socketserver模块的使用
基于TCP协议的套接字--支持并发(拿之前通信的例子,主要针对服务端,客户端不变)
# 服务端.py
import socketserver # 导入模块
# 先定义一个类,这个类专门解决通信循环的,必须继承一个类BaseRequestHandler
class MyRequestHandler(socketserver.BaseRequestHandler):
def handle(self): # 必须要写一个函数,叫handle的方法,里面放通信循环
while True:
try:
data = self.request.recv(1024) # 最大接收的字节数
if len(data) == 0:
break
print(data)
self.request.send(data.upper())
except Exception:
break
self.request.close()
# 链接循环,套接字属于IO密集型,对于IO密集型应该使用多线程
# 多线程ThreadingTCPServer里面放:监听的服务端ip和端口、定义的类、bind_and_activate=True
# bind_and_activate=True等同于bind()并且listen()默认属性为True无需添加。
server = socketserver.ThreadingTCPServer(('127.0.0.1',8080),MyRequestHandler,bind_and_activate=True)
# 一直对外提供服务
server.serve_forever()
# serve_forever()每建成一个链接,都调用MyRequestHandler这个类,创建一个对象,
# 把它建成的链接对象赋值给self下面的request进行通信
# 整体逻辑:相当于客户端每发来一个请求,服务端就启一个线程,每启一个线程就去运行对象下面的
# handle方法,把跟这个客户端所有相关的套接字信息全都放到self对象里面去并触发这个对象下面
# 的handle方法用这个方法跟客户端进行通信
# 客户端.py (可实现多个客户端同时通信)
import socket
# 1、买手机
phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) # 流式协议
# 2、打电话
phone.connect(('127.0.0.1',8080))
# 3、发收数据
while True:
msg = input('>>>: ').strip()
if len(msg) == 0:
continue
phone.send(msg.encode('utf-8'))
data = phone.recv(1024)
print(data.decode('utf-8'))
# 4、关闭
phone.close()
基于UDP协议的套接字--支持并发
# 服务端.py
import socketserver
class MyRequesthanlder(socketserver.BaseRequestHandler):
# 必须要写一个函数,叫handle的方法,里面放通信循环
def handle(self):
# 收到消息,进行解压。第一个值是客户端发来的数据。第二个值是套接字对象,用它来回消息
data,server = self.request
# 将收到的消息转大写回复,所有套接字信息都封装进self里了
server.sendto(data.upper(),self.client_address)
server = socketserver.ThreadingUDPServer(('127.0.0.1',9999),MyRequesthanlder)
server.serve_forever()
# 整体逻辑同上面TCP协议一样
# 客户端.py
from socket import *
client = socket(AF_INET,SOCK_DGRAM)
while True:
msg = input(">>>>:").strip()
client.sendto(msg.encode('utf-8'),('127.0.0.1',9999))
res,server_addr = client.recvfrom(1024)
print(res.decode('utf-8'))
-
操作系统
-
为什么要有操作系统。
程序员无法把所有的硬件操作细节都了解到,管理这些硬件并且加以优化使用是非常繁琐的工作,这个繁琐的工作就是操作系统来干的,有了他,程序员就从这些繁琐的工作中解脱了出来,只需要考虑自己的应用软件的编写就可以了,应用软件直接使用操作系统提供的功能来间接使用硬件。
-
什么是操作系统
操作系统就是一个协调、管理和控制计算机硬件资源和软件资源的控制程序。
操作系统位于计算机硬件与应用软件之间,本质也是一个软件。操作系统由操作系统的内核(运行于内核态,管理硬件资源)以及系统调用(运行于用户态,为应用程序员写的应用程序提供系统调用接口)两部分组成,所以,单纯的说操作系统是运行于内核态的,是不准确的
-
必备的理论基础
一 操作系统的作用:
1:隐藏丑陋复杂的硬件接口,提供良好的抽象接口
2:管理、调度进程,并且将多个进程对硬件的竞争变得有序
二 多道技术:
1.产生背景:针对单核,实现并发
ps:
现在的主机一般是多核,那么每个核都会利用多道技术
有4个cpu,运行于cpu1的某个程序遇到io阻塞,会等到io结束再重新调度,会被调度到4个
cpu中的任意一个,具体由操作系统调度算法决定。
2.空间上的复用:如内存中同时有多道程序
3.时间上的复用:复用一个cpu的时间片
强调:遇到io切,占用cpu时间过长也切,核心在于切之前将进程的状态保存下来,这样
才能保证下次切换回来时,能基于上次切走的位置继续运行
-
进程的相关概念
进程:进程指的就是程序的运行过程,是一个动态的概念
程序:程序就是一系列的代码文件,是一个静态的概念
进程也可以说成是操作系统干活的过程,
一个进程说白了就是操作系统控制硬件来运行应用程序的过程所以说进程是操作系统最核心的概念,没有之一,研究进程就是在研究操作系统
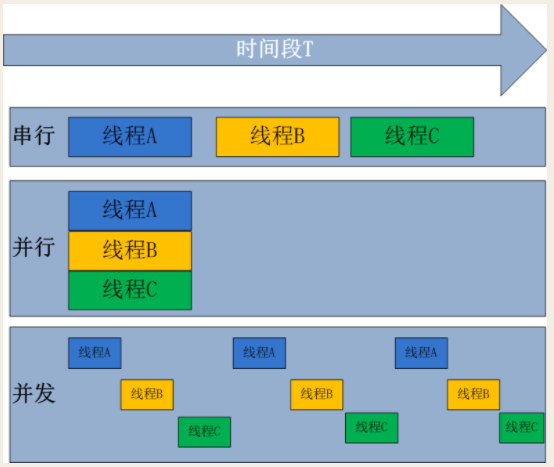
并发、并行与串行
无论是并行还是并发,在用户看来都是'同时'运行的,不管是进程还是线程,都只是一个任务而已,真是干活的是cpu,cpu来做这些任务,而一个cpu同一时刻只能执行一个任务
并发:是伪并行,多个任务看起来是同时运行。单个cpu+多道技术就可以实现并发,(并行也属于并发)
并行:多个任务真正意义上的同时运行,只有具备多个cpu才能实现并行
串行:一个任务运行完毕后才能开启下一个任务然后运行
单核下,可以利用多道技术,多个核,每个核也都可以利用多道技术(多道技术是针对单核而言的)
有四个核,六个任务,这样同一时间有四个任务被执行,假设分别被分配给了cpu1,cpu2,cpu3,
cpu4
一旦任务1遇到I/O就被迫中断执行,此时任务5就拿到cpu1的时间片去执行,这就是单核下的多道技术
而一旦任务1的I/O结束了,操作系统会重新调用它(需知进程的调度、分配给哪个cpu运行,由操作系统说了算),可能被分配给四个cpu中的任意一个去执行
所有现代计算机经常会在同一时间做很多件事,一个用户的PC(无论是单cpu还是多cpu),都可以同时运行多个任务(一个任务可以理解为一个进程)。
启动一个进程来杀毒(360软件)
启动一个进程来看电影(暴风影音)
启动一个进程来聊天(腾讯QQ)
所有的这些进程都需被管理,于是一个支持多进程的多道程序系统是至关重要的
多道技术概念回顾:内存中同时存入多道(多个)程序,cpu从一个进程快速切换到另外一个,使每个进程各自运行几十或几百毫秒,这样,虽然在某一个瞬间,一个cpu只能执行一个任务,但在1秒内,cpu却可以运行多个进程,这就给人产生了并行的错觉,即伪并发,以此来区分多处理器操作系统的真正硬件并行(多个cpu共享同一个物理内存)
-
提交任务的两种方式:
同步:提交一个任务,提交之后在原地等待提交的结果,之后再去提交下一个任务。所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不会返回。按照这个定义,其实绝大多数函数都是同步调用。但是一般而言,我们在说同步、异步的时候,特指那些需要其他部件协作或者需要一定时间完成的任务。
异步:提交一个任务,提交之后不等提交的任务运行完直接提交下一个任务。异步的概念和同步相对。当一个异步功能调用发出后,调用者不能立刻得到结果。当该异步功能完成后,通过状态、通知或回调来通知调用者。如果异步功能用状态来通知,那么调用者就需要每隔一定时间检查一次,效率就很低(有些初学多线程编程的人,总喜欢用一个循环去检查某个变量的值,这其实是一 种很严重的错误)。如果是使用通知的方式,效率则很高,因为异步功能几乎不需要做额外的操作。至于回调函数,其实和通知没太多区别。
-
一个任务运行的三种状态
运行态(Running)
当进程正在被CPU执行,或已经准备就绪随时可由调度程序执行,则称该进程为处于运行态
就绪态(Ready)
若此时进程没有被CPU执行,则称其处于就绪运行状态。
阻塞态(Blocked)
正在执行的进程,由于等待某个事件发生而无法执行时,便处于阻塞状态。引起进程阻塞的事件可有多种,例如,等待I/O完成、申请缓冲区不能满足、等待信件(信号)等
进程三种状态间的转换
①就绪→运行处于就绪状态的进程,当进程调度程序为之分配任务后,该进程便由就绪状态转变成运行状态。
②运行→就绪处于执行状态的进程在其执行过程中,因调度程序选择另一个进程,于是进程从执行状态转变成就绪状态。
③运行→阻塞正在运行的进程因等待某种事件发生而无法继续执行时,便从运行状态变成阻塞状态。
④阻塞→就绪处于阻塞状态的进程,若其等待的事件已经发生,于是进程由阻塞状态转变为就绪状态。阻塞:阻塞调用是指调用结果返回之前,当前线程会被挂起(如遇到io操作)。函数只有在得到结果之后才会将阻塞的线程激活。有人也许会把阻塞调用和同步调用等同起来,实际上他是不同的。对于同步调用来说,很多时候当前线程还是激活的,只是从逻辑上当前函数没有返回而已。
非阻塞(运行、就绪):非阻塞和阻塞的概念相对应,指在不能立刻得到提交结果之前也会立刻返回,同时该函数不会阻塞当前线程。
总结:
-
同步与异步针对的是函数/任务的调用方式:同步就是当一个进程发起一个函数(任务)调用的时候,一直等到函数(任务)完成,而进程继续处于激活状态。而异步情况下是当一个进程发起一个函数(任务)调用的时候,不会等函数返回,而是继续往下执行当,函数返回的时候通过状态、通知、事件等方式通知进程任务完成。
-
阻塞与非阻塞针对的是进程或线程:阻塞是当请求不能满足的时候就将进程挂起,而非阻塞则不会阻塞当前进程
-
-
开启进程的两种方式
进程是操作系统的概念,进程是由操作系统来开启的,例如你告诉操作系统有一段代码需要运行,把这段代码交给操作系统,就是一个进程。应用程序要开启进程,是为了实现多个任务的并发,真正能开启进程,管理进程的是操作系统。开启进程就是在给操作系统发起系统调用。调用的是操作系统的接口,而接口在Windows系统和Linux系统上是不一样的(Windows是CreateProcess,Linux是Fork),不同操作系统接口不同很正常,我们只需调用封装好的模块就可以,这个模块解决了跨平台性问题。
-
multiprocessing模块介绍
python中的多线程无法利用多核优势,如果想要充分地使用多核CPU的资源(os.cpu_count()查看),在python中大部分情况需要使用多进程。Python提供了multiprocessing。 multiprocessing模块用来开启子进程,并在子进程中执行我们定制的任务(比如函数),该模块与多线程模块threading的编程接口类似。
multiprocessing模块的功能众多:支持子进程、通信和共享数据、执行不同形式的同步,提供了Process、Queue、Pipe、Lock等组件。
需要再次强调的一点是:与线程不同,进程没有任何共享状态,进程修改的数据,改动仅限于该进程内。
-
Process类的介绍
创建进程的类:
由该类实例化得到的对象,表示一个子进程中的任务(尚未启动)
Process([group [, target [, name [, args [, kwargs]]]]])
强调:
1. 需要使用关键字的方式来指定参数
2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号
参数介绍:
group 参数未使用,值始终为None
target 表示调用对象,即子进程要执行的任务
args 表示调用对象的位置参数元组,args=(1,2,'egon',)
kwargs 表示调用对象的字典,kwargs={'name':'egon','age':18}
name 为子进程的名称
方法介绍:
p.start():启动进程,并调用该子进程中的p.run()
p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法
p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,
使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁
p.is_alive():如果p仍然运行,返回True
p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是
可选的 超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
属性介绍:
p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,
并且 设定为True后,p不能创建自己的新进程,必须在p.start()之前设置
p.name:进程的名称
p.pid:进程的pid
p.exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可)
p.authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网
Process类的使用
注意:在windows中Process()必须放到# if name == 'main':下
开启进程的方式一:可以让多个任务并发起来在后台同时运行
from multiprocessing import Process
import os
import time
def task(n):
print('父进程:%s 自己:%s 正在运行' %(os.getppid(),os.getpid()))
time.sleep(n)
print('父进程:%s 自己:%s 正在运行' % (os.getppid(), os.getpid()))
if __name__ == '__main__': # Windows规定启进程的代码必须放在它下面
# target表示调用对象,即子进程要执行的任务 ,args表示调用对象的位置参数元组
p = Process(target=task,args=(3,))
p.start() # 通知操作系统开启进程
print('主',os.getpid())
开启进程的方式二:用自定义类的方式(效果同方式一样)
from multiprocessing import Process
import os
import time
class Myprocess(Process): # 自定义的类必须继承Process类
def __init__(self,n):
super().__init__()
self.n = n
def run(self)->None:
print('父进程:%s 自己:%s 正在运行' % (os.getppid(),os.getpid()))
time.sleep(self.n)
print('父进程:%s 自己:%s 正在运行' % (os.getppid(), os.getpid()))
if __name__ == '__main__':
p = Myprocess(3)
p.start()
print('主',os.getpid())
-
进程之间内存空间彼此隔离
from multiprocessing import Process
import time
count = 100 # 在windows系统中把全局变量定义在if __name__ == '__main__'之上就可以了
def task():
global count
count = 0
if __name__ == '__main__':
p = Process(target=task)
p.start() # 通知操作系统开启进程
time.sleep(5) # 5秒够子进程启动起来运行完
print("主",count)
# 运行count = 100产生一个变量,定义一个函数,主进程里面有一份,然后开了一个子进程
# 开子进程的时候操作系统会把父进程数据一模一样复制给一份子进程,所以子进程也有100的值,
# 接着子进程启动的时候会运行task(),task()会将100改为0了,运行之后子进程改成功了,
# 那主进程呢?主进程的100仍然等于100,证明进程之间内存空间是彼此隔离的
-
进程对象的方法
# 例1:
from multiprocessing import Process
import os
import time
count = 100
def task():
global count
count = 0
if __name__ == '__main__':
p = Process(target=task)
p.start() # 通知操作系统开启进程
p.join() # 主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)
print("主",count)
# 例2:
from multiprocessing import Process
import os
import time
def task(n):
print(os.getpid())
time.sleep(n)
if __name__ == '__main__':
p1 = Process(target=task,args=(3,))
p2 = Process(target=task,args=(2,))
p3 = Process(target=task,args=(1,))
start = time.time()
p1.start() # 通知操作系统开启进程
p1.join()
p2.start() # 通知操作系统开启进程
p2.join()
p3.start() # 通知操作系统开启进程
p3.join()
stop = time.time()
print(stop - start)
# 加上join并不是变成串行了,而是看join放在什么位置,join往后放看到的是并发
# 例3:
from multiprocessing import Process
import os
import time
def task(n):
print(os.getpid())
time.sleep(n)
if __name__ == '__main__':
p1 = Process(target=task, args=(3,),name='进程1')
p1.start()
print(p1.name,p1.pid)
# p1.join()
p1.terminate()
time.sleep(0.01)
print(p1.is_alive())