MobileNet v2 论文链接:https://arxiv.org/abs/1801.04381
MobileNet v2是对MobileNet v1的改进,也是一个轻量化模型。
关于MobileNet v1的介绍,请看这篇:对MobileNet网络结构的解读
MobileNet v1遗留下的问题
1)结构问题
MobileNet v1的结构非常简单,是一个直筒结构,这种结构的性价比其实不高,后续一系列的ResNet,DenseNet等结构已经证明通过复用图像特征,使用Concat/Eltwise+等操作进行特征融合,能极大提升网络的性价比。
Concat(张量拼接):比如26*26*128,26*26*256经过拼接(Concat)之后得到(26*26*384)
Eltwise有三个操作:product(点乘),sum(相加减)和max(取最大值),其中sum是默认操作
2)Depthwise Convolution的潜在问题
Depthwise Convolution确实是降低了计算量,而在NxN Depthwise + 1x1 Pointwise的结构在性能上也接近NxN Conv。在实际使用中发现,Depthwise的部分kernel比较容易训废掉:训练完之后发现Depthwise训出来的kernel有不少是空的。当时我们认为,Depthwise每个kernel dim相对于普通Conv要小得多,过小的kernel_dim,加上ReLU的激活影响下,使得神经元输出很容易变为0,所以学废了。ReLU对于0的输出梯度为0,所以一旦陷入0输出,就没法恢复了。我们还发现,这个问题在定点化低精度的时候会进一步放大。
MobileNet v2的创新点
1. Inverted residuals,通常的residuals block(残差块)是先经过1*1的Conv layer,把feature map的通道数"压"下来,再经过3*3Conv layer,最后经过一个1*1的Conv layer,将feature map通道数再"扩展"回去。即先"压缩",最后"扩张"回去。
而Inverted residuals就是先"扩张",最后"压缩",后面会有介绍。
2. Linear bottlenecks,为了避免ReLU对特征的破坏。
MobileNet v2和v1之间的区别
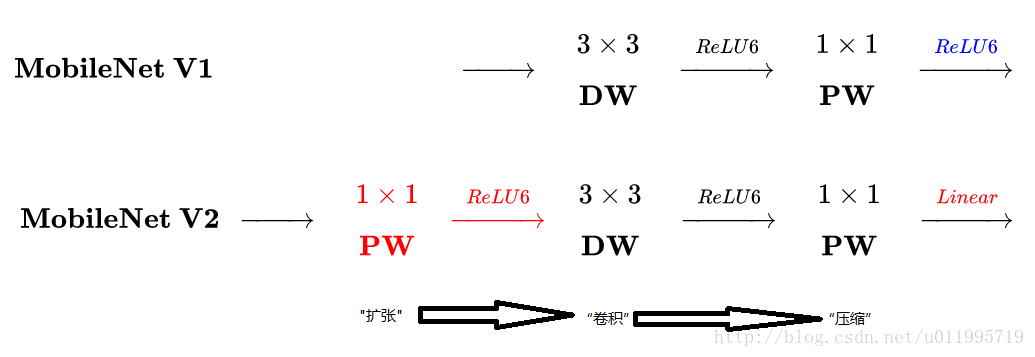
主要是两点:
1. Depthwise convolution之前多了一个1*1的"扩张"层,目的是为了提升通道数,获得更多特征
2. 最后不采用ReLU,而是linear,目的是防止ReLU破坏特征
MobileNet v2的网络结构

其中: t 表示"扩张倍数",c 表示输出通道数,n 表示重复次数,s 表示步长stride
有两点错误:
1. 第五行,也就是第7~10个bottleneck,stride = 2,分辨率应该从28降低到14,如果不是分辨率出错,那就应该是stride=1
2. 文中提到共计采用19个bottleneck,但是这里只有17个
一个bottleneck有如下三个部分组成:

stride = 1和stride = 2,在结构上稍微有点不同。在stride=2时,不采用shortcut。我们对MobileNet v1和MobileNet v2进行比较如下图:

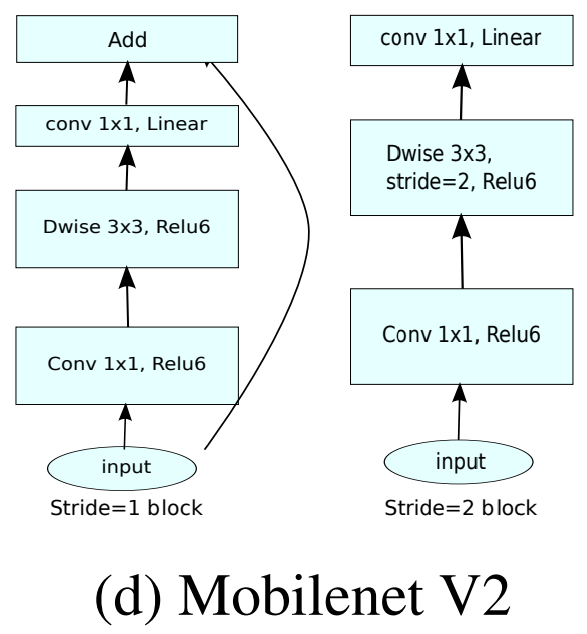
注意:除了最后的avgpool,整个网络并没有采用pooling进行下采样,而是采用stride=2来下采样。