SqueezeNet网络模型非常小,但分类精度接近AlexNet。
这里复习一下卷积层参数的计算
输入通道ci,核尺寸k,输出通道co,参数个数为:![]()
以AlexNet第一个卷积为例,参数量达到:3*11*11*96=34848
基础模块
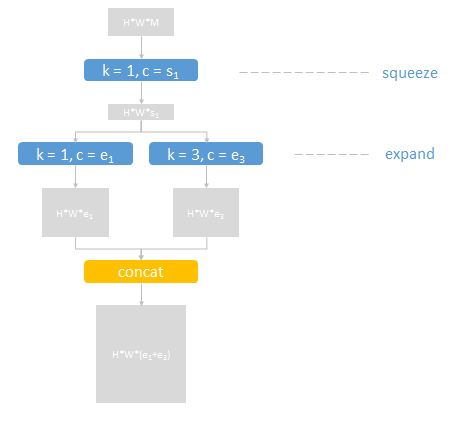
包含三个卷积层(蓝色),步长为1,分为squeeze和expand两部分,分别压缩和扩展数据(灰色矩形)的通道数
expand部分中,两个不同核尺寸的结果通过串接层(黄色)合并输出
fire模块有三个可调参数:
- s1:squeeze部分,1x1卷积层的通道数
- e1:expand部分,1x1卷积层的通道数
- e3:expand部分,3x3卷积层的通道数
输入输出尺寸相同。输出通道数不限,输出通道数为e1+e3
在本文提出SqueezeNet结构中,![]()
网络结构

整个网络包含10层
第1层为卷积层,缩小输入图像,提取96维特征
第2到9层为fire模块,每个模块内部先减少通道数(squeeze)再增加通道数(expand)。每两个模块之后,通道数会增加
在1、4、8层之后加入降采样的max pooling,缩小一般尺寸
第10层又是卷积层,为小图的每个像素预测1000类分类得分
最后用一个全图average pooling得到这张图的1000类得分,使用softmax函数归一化为概率
这是一个全卷积网络,避免了如今越来越不受待见的全连接层。由于最后一层提供了全图求平均操作,可以接受任意尺寸的输入。当然,输入还是需要归一化大致相当的尺寸,保持统一尺度
全连接层的参数多,对性能提升帮助不大,现在往往被pooling代替
这个网络达到了和AlexNet相当的分类精度,但模型缩小了50倍
| architecture | model size | top-1 accuracy | top-5 accuracy |
|---|---|---|---|
| AlexNet | 240MB | 57.2% | 80.3% |
| SqueezeNet | 4.8MB | 57.5% | 80.3% |
网络设计的要点
1. 为了使1x1和3x3filter输出的结果有相同的尺寸,在expand modules中,给3x3filter的原始输入添加一个像素的边界(zero-padding)
2. squeeze和expand layers中都是用ReLU作为激活函数
3. 在fire9 module之后,使用Dropout,比例取50%
4. 训练过程中,初始学习率设为为0.04,在训练过程中线性降低学习率
5. 由于caffe中不支持使用两个不同尺寸的filter,在expand layer中实际上使用了两个单独的卷积层(1x1filter和3x3filter),最后将这两层的输出连接在一起,这在数值上等价于使用单层但是包含两个不同尺寸的filter
当然SqueezeNet还可以继续压缩,使模型更小。SqueezeNet采用了一些deep-compression的方法,比如裁剪,量化和编码
裁剪:设置阈值,对于小于阈值的参数直接写0,然后用非零参数再次训练
量化:对参数做聚类,然后每个类别的参数的梯度值相加,作用在聚类中心上
编码:Huffman编码进一步压缩存储
参考: