K近鄰算法,其英文全稱:K-Nearest Neighbor Classification,一般簡稱為KNN。該算法是一種經典的分類算法
在K近鄰分類算法中,對於預測的新樣本數據(未有分類標籤),將其與訓練樣本一一進行比較,
找到最為相似的K個訓練樣本,並以這K個訓練樣本中出現最多的分類標籤作為最終新樣本數據的預測標籤。
其思想與「近朱者赤,近墨者黑」有異曲同工之妙!
K近邻算法有三个要素:
一、K值的定義(通俗理解即選擇多少個和自己比較相似的小夥伴)
二、距離(相似度)定義(衡量自己與小夥伴是否相似的度量標準/公式)
三、鄰居類別的統計(採用少數服從多數的原則,給未分類標籤數據進行賦值)
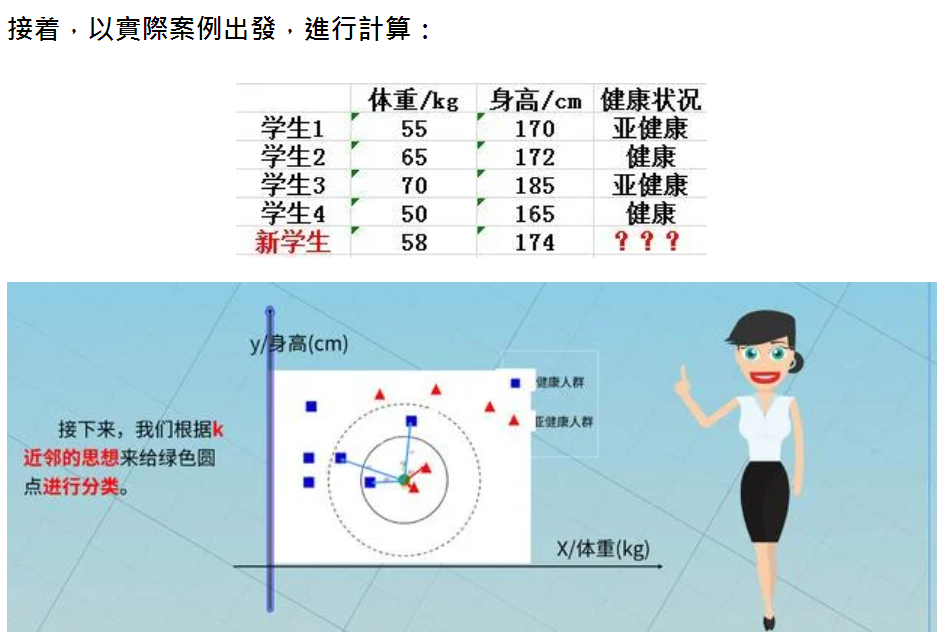
如上圖所示,我們有學生1,2,3,4,5(新學生)的數據(體重、身高),
其中學生1,2,3,4還有標籤(健康或亚健康)。
我們的問題是通過對學生1,2,3,4的數據進行學習,然後對學生5的标签(健康或亚健康)做出預測?
