What is Foreign key and how to create a Foreign key constraint?
Note:Foreign Keys are used to enforce(强制) database integrity(完整) . In layman's terms(一般来说), A foreign key in one table points to a primary key in another table. The foreign key constraint prevents invalid data form being inserted into the foreign key column. The values that you enter into the foreign key column, has to be one of the values contained in the table it points to.
for example:add a foreign key relation.
Table - Student: ID, GenderID;
Gender: ID, StudentID;
alter table Student add constraint FK_Student_GenderID
foreign key (GenderID) references Gender (ID)
Syntax:
ALTER TABLE 外键表名 ADD CONSTRAINT 外键约束名
FOREIGN KEY (外键名) REFERENCES 主表名 (主键名)
Adding a default constraint and dropping a constraint
Altering an existing column to add a default constraint:
alter table Gender
add constraint DF_Gender_ID
default 1 for ID
Syntax:
ALTER TABLE 表名
ADD CONSTRAINT 约束名
DEFAULT 默认值 FOR 列名
Adding a new column with default value, to an existing table:
alter table Student
add Name nvarchar(20) not null
constraint DF_Student_Name default 'gester'
Syntax:
ALTER TABLE 表名
ADD 列名 数据类型 是否允许null
CONSTRAINT 约束名 DEFAULT 默认值
Dropping a constraint:
alter table Student
drop constraint DF_Student_Name
Syntax:
ALTER TABLE 表名
DROP CONSTRAINT 约束名
Cascading referential integrity constraint
Cascading referential integrity constraint allows to define the actions Microsoft SQL Server should take when a user attempts to delete or update a key to which an existing foreign keys points.
For example, consider the 2 tables shown below. If you delete row with ID = 1 fromtblGender table, then row with ID = 3 from tblPerson table becomes an orphan record. You will not be able to tell the Gender for this row. So, Cascading referential integrity constraint can be used to define actions Microsoft SQL Server should take when this happens. By default, we get an error and the DELETE or UPDATE statement is rolled back. 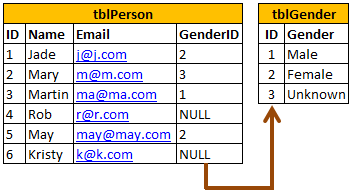
However, you have the following options when setting up Cascading referential integrity constraint
1. No Action: This is the default behaviour. No Action specifies that if an attempt is made to delete or update a row with a key referenced by foreign keys in existing rows in other tables, an error is raised and the DELETE or UPDATE is rolled back.
2. Cascade: Specifies that if an attempt is made to delete or update a row with a key referenced by foreign keys in existing rows in other tables, all rows containing those foreign keys are also deleted or updated.
3. Set NULL: Specifies that if an attempt is made to delete or update a row with a key referenced by foreign keys in existing rows in other tables, all rows containing those foreign keys are set to NULL.
4. Set Default: Specifies that if an attempt is made to delete or update a row with a key referenced by foreign keys in existing rows in other tables, all rows containing those foreign keys are set to default values.
Adding a check constraint
CHECK constraint is used to limit the range of the values, that can be entered for a column.
Let's say, we have an integer AGE column, in a table. The AGE in general cannot be less than ZERO and at the same time cannot be greater than 150. But, since AGE is an integer column it can accept negative values and values much greater than 150.
So, to limit the values, that can be added, we can use CHECK constraint. In SQL Server, CHECK constraint can be created graphically, or using a query.
The following check constraint, limits the age between ZERO and 150.
ALTER TABLE tblPerson
ADD CONSTRAINT CK_tblPerson_Age CHECK (Age > 0 AND Age < 150)
The general formula for adding check constraint in SQL Server:
ALTER TABLE { TABLE_NAME }
ADD CONSTRAINT { CONSTRAINT_NAME } CHECK ( BOOLEAN_EXPRESSION )
If the BOOLEAN_EXPRESSION returns true, then the CHECK constraint allows the value, otherwise it doesn't. Since, AGE is a nullable column, it's possible to pass null for this column, when inserting a row. When you pass NULL for the AGE column, the boolean expression evaluates to UNKNOWN, and allows the value.
To drop the CHECK constraint:
ALTER TABLE tblPerson
DROP CONSTRAINT CK_tblPerson_Age
Unique key constraint
We use UNIQUE constraint to enforce uniqueness of a column i.e the column shouldn't allow any duplicate values. We can add a Unique constraint thru the designer or using a query.
To add a unique constraint using SQL server management studio designer:
1. Right-click on the table and select Design
2. Right-click on the column, and select Indexes/Keys...
3. Click Add
4. For Columns, select the column name you want to be unique.
5. For Type, choose Unique Key.
6. Click Close, Save the table.
To create the unique key using a query:
Alter Table Table_Name Add Constraint Constraint_Name Unique(Column_Name)
Both primary key and unique key are used to enforce, the uniqueness of a column. So, when do you choose one over the other?
A table can have, only one primary key. If you want to enforce(强制) uniqueness on 2 or more columns, then we use unique key constraint.
What is the difference between Primary key constraint and Unique key constraint? This question is asked very frequently in interviews.
1. A table can have only one primary key, but more than one unique key
2. Primary key does not allow nulls, where as unique key allows one null
To drop the constraint
1. Right click the constraint and delete.
Or
2. Using a query
Alter Table tblPerson Drop COnstraint UQ_tblPerson_Email