这些东西总是忘记来回查,特此记录一下:
1. caffe标注txt文件的读取与保存(使用pandas.DataFrame)
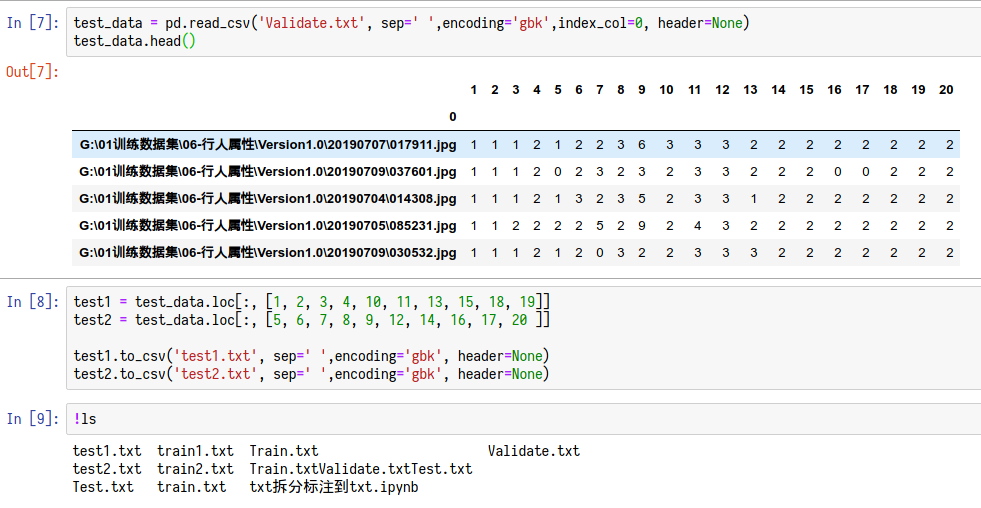
读取:
train_data = pd.read_csv('Train.txt', sep=' ',encoding='gbk',index_col=0, header=None)
保存
test1.to_csv('test1.txt', sep=' ',encoding='gbk', header=None)
实例:
2. LMDB数据读取Data层:
caffe生成的lmdb数据,有生产2文件夹和4文件夹版本, 对应data层如下:
windows版本:
layer {
name: "data"
type: "Data"
top: "data"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 224
mean_file: "mean.binaryproto"
contrast_brightness_adjustment: true
smooth_filtering: true
max_color_shift: 10
max_smooth: 6
apply_probability: 0.5
}
data_param {
source: "CaffeLMDB/TrainDataDB"
batch_size: 24
backend: LMDB
}
}
layer {
name: "label"
type: "Data"
top: "label"
include {
phase: TRAIN
}
data_param {
source: "CaffeLMDB/TrainlableDB"
batch_size: 24
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 224
mean_file: "mean.binaryproto"
}
data_param {
source: "CaffeLMDB/ValDataDB"
batch_size: 1
backend: LMDB
}
}
layer {
name: "label"
type: "Data"
top: "label"
include {
phase: TEST
}
data_param {
source: "CaffeLMDB/VallableDB"
batch_size: 1
backend: LMDB
}
}
我的linux版本:
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 331
mean_file: "./lmdb_data/img_test_lmdb/mean.binaryproto"
contrast_brightness_adjustment: true
smooth_filtering: true
max_color_shift: 10
max_smooth: 6
apply_probability: 0.5
}
data_param {
source: "./lmdb_data/img_test_lmdb"
batch_size: 8
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 331
mean_file: "./lmdb_data/img_train_lmdb/mean.binaryproto"
}
data_param {
source: "./lmdb_data/img_train_lmdb"
batch_size: 1
backend: LMDB
}
}
3. caffe训练命令
#!/bin/bash
set -e
# 设置环境变量, 制定caffe路径
export PATH=/home/zhuoshi/ZSZT/Geoffrey/caffe/caffe-master/build/tools:$PATH
# 设置开启日志
GLOG_logtostderr=0
GLOG_log_dir='./log'
caffe train
--solver=solver.prototxt
--weights=snapshot/solver_iter_50000.caffemodel # 这里指定caffe模型文件
--snapshot=snapshot/solver_iter_20000.solverstate # 这里指定caffe中间态文件
--gpu=0 # 可以指定序号或者`all`
snapshot和weights只能指定一个用于继续训练和finetune
4. caffe的solver文件解释
# 网络的模型文件
net: "./train.prototxt"
# test_iter * 测试batch_size = 测试集大小
test_iter: 2000
# 每迭代多少次测试一遍
test_interval: 25000
base_lr: 0.001
lr_policy: "step"
gamma: 0.1
# 每隔多少次衰减学习率
stepsize: 50000
# 迭代多少次显示一次日志
display: 100
# 最大迭代次数
max_iter: 500000
momentum: 0.9
weight_decay: 0.0005
# 每隔多少次保存
snapshot: 20000
snapshot_prefix: "./snapshot"
solver_mode: GPU
5. txt2lmdb脚本
#!/usr/bin/env sh
# Create the imagenet lmdb inputs
####################################################
# 配置
####################################################
EXAMPLE=/home/zhuoshi/ZSZT/Geoffrey/Person-resnet18/lmdb_data # lmdb存储位置
DATA=/home/zhuoshi/ZSZT/Geoffrey/Person-resnet18/data # txt文件所在文件夹 - 同时也是.txt相对路径的起始点(图片绝对路径=$DATA+txt中相对路径)
CAFFE_HOME=/home/zhuoshi/ZSZT/Geoffrey/caffe/caffe-master # caffe的工具库
HEIGHT=256
WIDTH=256
####################################################
# 处理train
####################################################
echo "Creating train lmdb..."
TRAIN_PATH=$EXAMPLE/img_train_lmdb
# 如果存在,删除原数据
if [ ! -d "$TRAIN_PATH/" ];then
echo "文件不存在"
mkdir -p $TRAIN_PATH/
else
echo "$TRAIN_PATH文件夹已存在"
rm -rf $TRAIN_PATH/
# mkdir -p $TRAIN_PATH/
fi
# 生成lmdb
$CAFFE_HOME/build/tools/convert_imageset --shuffle --resize_height=$HEIGHT --resize_width=$WIDTH $DATA/ $DATA/train.txt $TRAIN_PATH #
echo "Creating train lmdb Done!, Create mean.binaryproto..."
# # 计算图片均值
$CAFFE_HOME/build/tools/compute_image_mean $TRAIN_PATH/ $TRAIN_PATH/mean.binaryproto
echo "train Done!"
####################################################
# 处理test
####################################################
echo "Creating test lmdb ..."
TEST_PATH=$EXAMPLE/img_test_lmdb
# 如果存在,删除原数据
if [ ! -d "$TEST_PATH/" ];then
echo "文件不存在"
mkdir $TEST_PATH
else
echo "$TEST_PATH文件夹已存在"
rm -rf $TEST_PATH/
# mkdir $TEST_PATH/
fi
# 生成lmdb
$CAFFE_HOME/build/tools/convert_imageset --shuffle --resize_height=256 --resize_width=256 $DATA/ $DATA/test.txt $TEST_PATH #
echo "Creating test lmdb Done!, Create mean.binaryproto..."
# # 计算图片均值
$CAFFE_HOME/build/tools/compute_image_mean $TEST_PATH/ $TEST_PATH/mean.binaryproto
echo "test Done!"
####################################################
echo "Done."
windows版本的bat命令:
echo "Creating train Mulit-Out CaffeLMDB..."
del "E:/CaffeLMDB/TrainDataDB*.*" /f /s
del "E:/CaffeLMDB/TrainlableDB*.*" /f /s
del "E:/CaffeLMDB/ValDataDB*.*" /f /s
del "E:/CaffeLMDB/VallableDB*.*" /f /s
rd /s /q "E:/CaffeLMDB/TrainDataDB"
rd /s /q "E:/CaffeLMDB/TrainlableDB"
rd /s /q "E:/CaffeLMDB/ValDataDB"
rd /s /q "E:/CaffeLMDB/VallableDB"
"E:/CaffeTool/Caffe_Release/convert_imageset" --gray=false --shuffle --resize_height=224 --resize_width=224 "" "E:/CaffeTrain/PersonProperty/data/Train.txt" "E:/CaffeLMDB/TrainDataDB" "E:/CaffeLMDB/TrainlableDB" 20
"E:/CaffeTool/Caffe_Release/convert_imageset" --gray=false --shuffle --resize_height=224 --resize_width=224 "" "E:/CaffeTrain/PersonProperty/data/Validate.txt" "E:/CaffeLMDB/ValDataDB" "E:/CaffeLMDB/VallableDB" 20
pause