模型保存(tf.keras保存模型)
- 保存
- Tf.Keras 模型保存为 HDF5 文件
- Keras 使用了 h5py Python 包。
- h5py 是 Keras 的依赖项,应默认被安装
- 保存/加载整个模型
-
不建议使用 pickle 或 cPickle 来保存模型。
-
使用 model.save(‘path/to/my_model.h5’) 将整个模型保存到单个 HDF5 文件中。
-
包括以下内容:
- · 模型的结构,允许重新创建模型
- · 模型的权重
- · 训练配置项(损失函数,优化器)
- · 优化器状态,允许准确地从你上次结束的地方继续训练。
-
保存/加载整个模型可使我们在不访问原始 python 代码的情况下使用模型。还可以从中断的位置恢复训练。
-
保存完整模型会非常有用——我们可以在 TensorFlow.js (HDF5, Saved Model) 加载保存的模型,然后在 web 浏览器中训练和运行它们,或者使用 TensorFlow Lite 将它们转换为在移动设备上运行(HDF5, Saved Model)
-
重新创建完全相同的模型,包括其权重和优化程序new_model = tf.keras.models.load_model(‘my_model.h5’)
-
Keras 通过检查网络结构来保存模型。
-
目前,它无法保存 Tensorflow 优化器(调用自tf.train)。使用这些优化器的时候,需要在加载后重新编译模型,否则将失去优化器的状态。
-
通过 saved_model 格式保存(实验性的,未来可能变化):tf.keras.experimental.export_saved_model(model, saved_model_path)
-
通过 saved_model 格式恢复:new_model =tf.keras.experimental.load_from_saved_model(sav
ed_model_path) -
通过 saved_model 格式恢复:saved_model 格式包含完整的TensorFlow程序,是tensorflow对象的独立序列化格式,包括权重和计算。它不需要运行原始模型构建代码,这使得它可用于共享或部署(使用TFLite,TensorFlow.js,TensorFlow服务)
-
- 只保存/加载模型的结构
- 保存模型的结构,而非其权重或训练配置项:Config = model.get_config()
- 得到的是一个Python Dict,它使我们可以重新创建相同的结构的模型
- 加载模型的结构,而非其权重或训练配置项:Reinitialized_model = tf.keras.Model.from_config(config)
- 保存模型的结构,也可以使用json字符串,方便保存到磁盘:json_string = model.to_json()
- Reinitialized_model = tf.keras.models.model_from_json(json_string )
- 只保存模型的权重:model.save_weights(‘my_model_weights.h5’)
- 只加载模型的权重 :model.load_weights(‘my_model_weights.h5’)
- 注意保存和加载模型的权重 :既可以使用HDF5格式也可以使用SavedModel格式,取决于后缀,也可以通过 save_format参数来显式指定。
- 参数可以取: tf 或 h5
- 在训练期间保存模型
- tf.keras.callbacks.ModelCheckpoint 允许在训练的过程中和结束时回调保存的模型。
例子
import os
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
os.environ['TF_FORCE_GPU_ALLOW_GROWTH'] = 'true'
gpu_ok = tf.test.is_gpu_available()
print("tf version:", tf.__version__)
print("use GPU", gpu_ok) # 判断是否使用gpu进行训练

# 下载数据集并划分为训练集和测试集
(train_image,train_lable),(test_image,test_label) = tf.keras.datasets.fashion_mnist.load_data()
# 归一化
train_image=train_image/255
test_image=test_image/255
# 建立模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28))) # 28*28
model.add(tf.keras.layers.Dense(128,activation="relu"))
model.add(tf.keras.layers.Dense(10,activation="softmax"))
# 编译模型
model.compile(optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["acc"]
)
# 使用训练集训练模型
model.fit(train_image,train_lable,epochs=5)
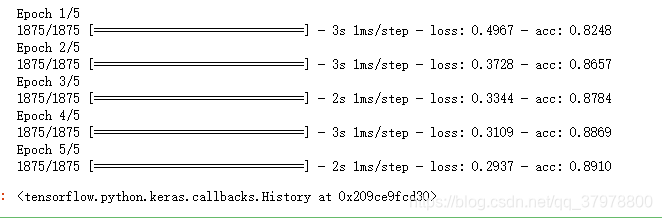
# 使用测试集进行评价
model.evaluate(test_image,test_label)

保存整个模型
整个模型可以保存到一个文件中,其中包含权重值、模型配置乃至优化器配置。这样,您就可以为模型设置检查点,并稍后从完全相同的状态继续训练,而无需访问原始代码。
在 Keras 中保存完全可正常使用的模型非常有用,您可以在 TensorFlow.js 中加载它们,然后在网络浏览器中训练和运行它们。
Keras 使用 HDF5 标准提供基本的保存格式。
# 保存模型:此方法保存以下所有内容:
# 1.权重值 2.模型配置(架构) 3.优化器配置
model.save("./save/less_model.h5")
# 加载模型
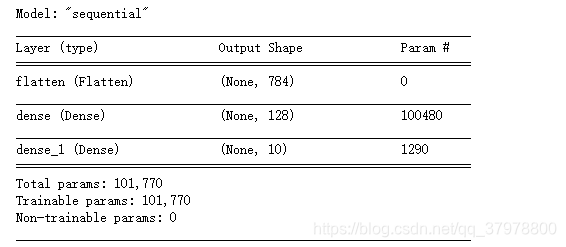
new_model = tf.keras.models.load_model("./save/less_model.h5")
new_model.summary()# 查看模型架构
# 使用测试集进行评价
new_model.evaluate(test_image,test_label)

仅保存架构
有时我们只对模型的架构感兴趣,而无需保存权重值或优化器。在这种情况下,可以仅保存模型的“配置” 。
- 保存架构只需要使用with open 文件操作方法把json_config 把配置写入磁盘就行
json_config = model.to_json()
json_config

# 重建模型
reinitialized_model = tf.keras.models.model_from_json(json_config)
reinitialized_model.summary()

# 编译
reinitialized_model.compile(optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["acc"]
)
# 使用测试集进行评价 因权重是随机的所以准确率稍微降低了
reinitialized_model.evaluate(test_image,test_label)

仅保存权重
有时我们只需要保存模型的状态(其权重值),而对模型架构不感兴趣。在这种情况下,可以通过get_weights()获取权重值,并通过set_weights()设置权重值
weights = model.get_weights()

# 加载权重
reinitialized_model.set_weights(weights)
# 使用测试集进行评价
reinitialized_model.evaluate(test_image,test_label)

# 把权重保存到磁盘上
model.save_weights("./save/less_weights.h5")
# 从磁盘上加载权重
reinitialized_model.load_weights("./save/less_weights.h5")
# 使用测试集进行评价
reinitialized_model.evaluate(test_image,test_label)

在训练期间保存检查点
在训练期间或训练结束时自动保存检查点。这样一来,您便可以使用经过训练的模型,而无需重新训练该模型,或从上次暂停的地方继续训练,以防训练过程中断。
回调函数:tf.keras.callbacks.ModelCheckpoint
Checkpoint_path = "./save/cp.cpkt" # 定义路径
cp_callback = tf.keras.callbacks.ModelCheckpoint(Checkpoint_path,
save_weights_only=True)# 只保存权重save_weights_only=True
# 建立模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28))) # 28*28
model.add(tf.keras.layers.Dense(128,activation="relu"))
model.add(tf.keras.layers.Dense(10,activation="softmax"))
# 编译模型
model.compile(optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["acc"]
)
# 使用训练集训练模型
model.fit(train_image,train_lable,epochs=5,callbacks=[cp_callback]) # 每训练一个epoch后保存一次
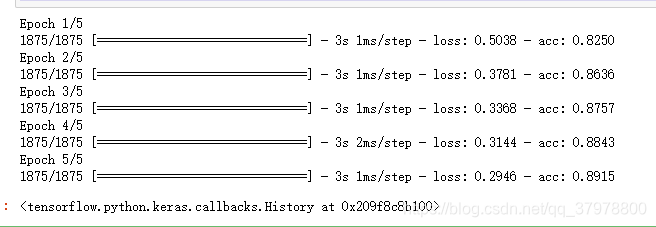
# 使用检查点文件
model.load_weights(Checkpoint_path)
model.evaluate(test_image,test_label)

自定义中保存模型
import os
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
os.environ['TF_FORCE_GPU_ALLOW_GROWTH'] = 'true'
gpu_ok = tf.test.is_gpu_available()
print("tf version:", tf.__version__)
print("use GPU", gpu_ok) # 判断是否使用gpu进行训练
(train_image, train_lable), (test_image, test_label) = tf.keras.datasets.fashion_mnist.load_data()
train_image = train_image/255
test_image = test_image/255
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28))) # 28*28
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(10))
optimizer = tf.keras.optimizers.Adam()
loss_func = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss(model, x, y):
y_ = model(x)
return loss_func(y, y_)
def train_step(model, images, labels):
with tf.GradientTape() as t:
pred = model(images)
loss_step = loss_func(labels, pred)
grads = t.gradient(loss_step, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
train_loss(loss_step)
train_accuracy(labels, pred)
train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('train_accuracy')
test_loss = tf.keras.metrics.Mean('test_loss', dtype=tf.float32)
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('test_accuracy')
cp_dir = './save' # 存储路径
cp_prefix = os.path.join(cp_dir, 'ckpt')
checkpoint = tf.train.Checkpoint(optimizer=optimizer,
model=model
) # 需要保存的参数
dataset = tf.data.Dataset.from_tensor_slices((train_image, train_lable))
dataset = dataset.shuffle(10000).batch(32)
def train():
for epoch in range(5):
for (batch, (images, labels)) in enumerate(dataset):
train_step(model, images, labels)
print('Epoch{} loss is {}'.format(epoch, train_loss.result()))
print('Epoch{} Accuracy is {}'.format(epoch, train_accuracy.result()))
train_loss.reset_states()
train_accuracy.reset_states()
if (epoch + 1) % 2 == 0:
checkpoint.save(file_prefix = cp_prefix)
train()

tf.train.latest_checkpoint(cp_dir)

# 恢复模型
checkpoint.restore(tf.train.latest_checkpoint(cp_dir)) # 取出最新的检查点
tf.argmax(model(train_image, training=False), axis=-1).numpy() # 取出预测值

train_lable # 实际值

# 求出正确率
(tf.argmax(model(train_image, training=False), axis=-1).numpy() == train_lable).sum()/len(train_lable)
