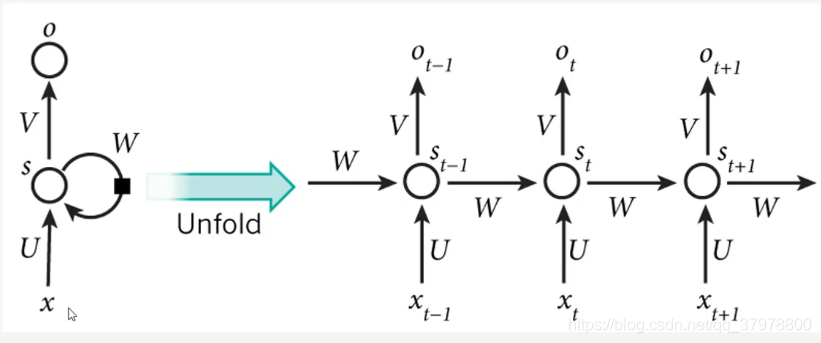
什么是RNN?







代码
import tensorflow as tf
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import pandas as pd
import os
import re
# 显存自适应分配
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu,True)
gpu_ok = tf.test.is_gpu_available()
print("tf version:", tf.__version__)
print("use GPU", gpu_ok) # 判断是否使用gpu进行训练

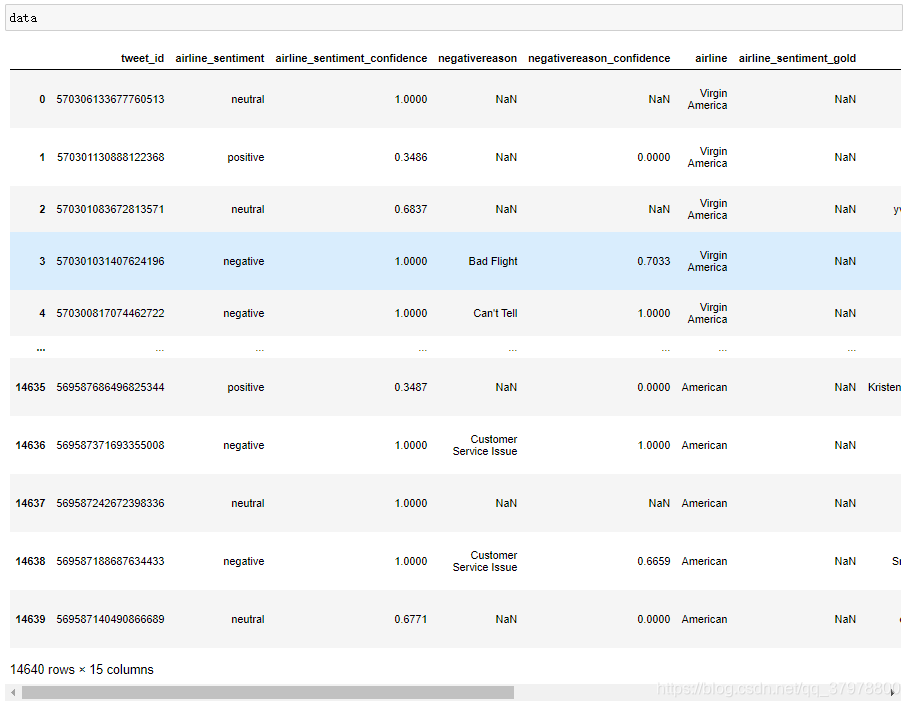
读取数据
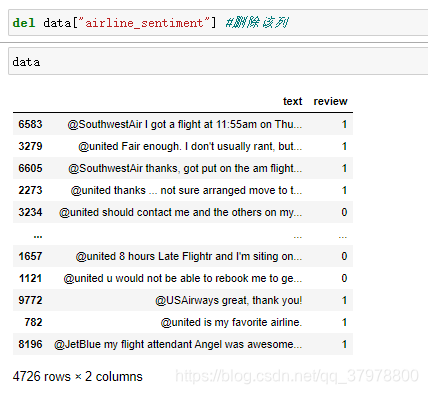
data = pd.read_csv ("F:/py/ziliao/数据集/Tweets.csv")
data = data[["airline_sentiment","text"]] # 取出需要的列
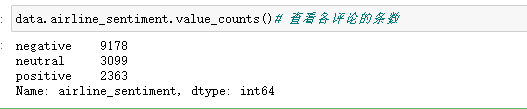
data_p = data[data.airline_sentiment=="positive"] # 取出需要的评论
data_n = data[data.airline_sentiment=="negative"]
data_n = data_n.iloc[:len(data_p)] # 我们从差评里取出好评这么多数据让数据一致
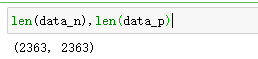
数据预处理
# 创建新的数据
data = pd.concat([data_n,data_p])
len(data)

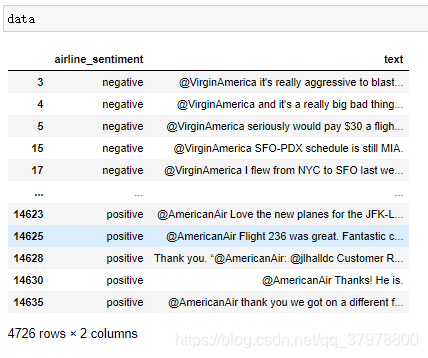
# 处理label
# 返回布尔值,把布尔值astype成int类型 赋值给review列
data["review"] = (data.airline_sentiment=="positive").astype("int")
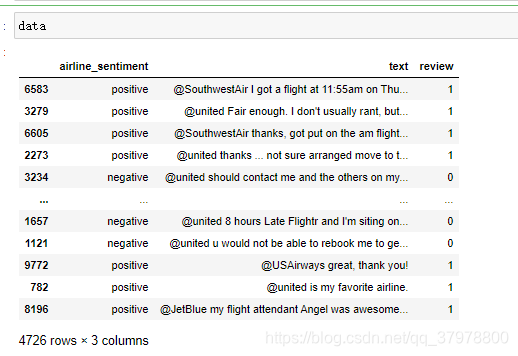
处理评论文本
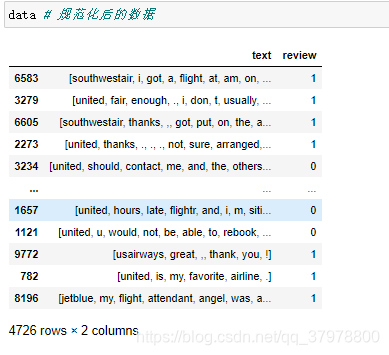
token = re.compile("[A-Za-z]+|[!?,.()]")# 编写一个正则取出A-Z a-z !?,.()
def reg_text(text):
new_text = token.findall(text) # 提取字符
new_text = [word.lower()for word in new_text] # 变成小写
return new_text
data["text"] = data.text.apply(reg_text) # 字符处理后重新赋值给text
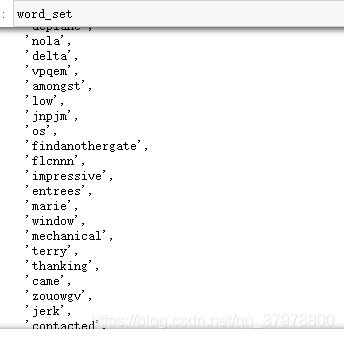
# 提取出文本中的唯一单词
word_set = set()
for text in data.text:
for word in text:
word_set.add(word)
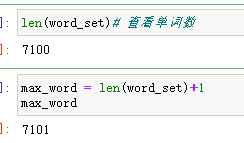
# 构造一个 英文单词:索引
word_list = list(word_set) # 转换成列表

# 转换成 英文单词:数字索引 把所有数字+1 表示不从0开始数数
word_index = dict((word,word_list.index(word)+1) for word in word_list)

# 对数据集进行转换 如果未匹配到 0作为填充
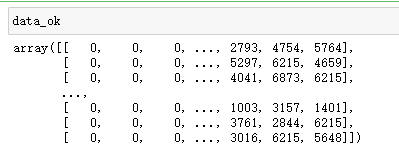
data_ok = data.text.apply(lambda x:[word_index.get(word,0)for word in x])
max(len(x)for x in data_ok),min(len(x)for x in data_ok) # 查看评论长度
maxlen = max(len(x)for x in data_ok)
# 对所有评论安装最大长度进行填充 填充为0
data_ok = tf.keras.preprocessing.sequence.pad_sequences(data_ok.values,
maxlen=maxlen)

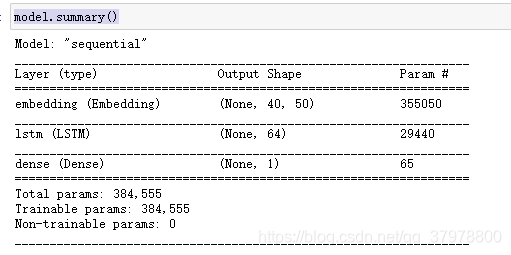
搭建循环神经网络
model = tf.keras.Sequential() # 顺序模型
# 最大单词格式 , 密集向量长度 , 评论的长度
model.add(tf.keras.layers.Embedding(max_word,50,input_length=maxlen))
model.add(tf.keras.layers.LSTM(64)) # 添加LSTM层 隐藏单元 64个 #超参数
model.add(tf.keras.layers.Dense(1,activation="sigmoid")) # 二分类激活函数sigmoid
# 编译
model.compile(optimizer="adam",
loss="binary_crossentropy",
metrics=["acc"]
)
# 训练
model.fit(data_ok,label, # 训练数据及label
epochs=10, # 训练步数
batch_size=128, # 每次训练128个数据
validation_split=0.2 # 从训练集中分割出20%作为测试集
)
